Available now:
2024 Software Development Tools from Intel
I’m pleased to introduce the 2024 release of software development tools from Intel. New features are found throughout our collection of numerous (I counted more than forty) AI, HPC, and rendering software tools.
Award-winning – Thank you for your feedback.
We know that our tools have earned the trust of very demanding software developers over the past three decades. We are deeply honored with recognition from these demanding users when readers of HPCwire selected our Intel oneAPI Toolkit as the “Best HPC Programming Tool or Technology” in the HPCwire 2023 Readers’ Choice Awards. (More information at https://www.hpcwire.com/2023-readers-editors-choice-programming-tool-technology.)
Serious AI acceleration
Much of our AI focus comes together in AI tools which bring more performance to AI in numerous ways to meet your needs. A sampling of key new capabilities include:
- Intel® Distribution for Python supports Intel GPUs and helps developers get more work done with fast performance using standard Python to deploy numeric workloads and optimized data parallel extensions (Python, NumPy*, Numba*) intelligently on CPU and GPU systems.
- Accelerated AI and machine learning with native support through Intel-optimized PyTorch and TensorFlow frameworks and improvements to data parallel extensions in Python on Intel CPUs and GPUs.
- Intel® oneAPI Data Analytics Library (oneDAL) optimizes big data analysis with integration into Microsoft's open-source ML.Net* framework to build and ship machine learning models.
- Intel® oneAPI Deep Neural Network (oneDNN) Library streamlines storage efficiency and optimizes performance on Intel® Xeon® processors. It also enhances compatibility with graph compiler capabilities and advances code generation through Xbyak and accelerated sparse_tensor_dense_matmul() performance on Intel Xeon processors with TensorFlow 2.5—ultimately boosting development productivity and application speed.
- Intel® oneAPI Collective Communications Library (oneCCL) boosts performance for distributed AI workloads through better utilization of hardware resources through its optimized communication patterns.
- Intel® Advisor adds support for profiling Python code to find performance headroom with an automated Roofline analysis. It supports FP16 and BF16 extensions and Intel® AMX profiling in 4th gen Intel Xeon Scalable processors. Discover application performance characterization, such as bandwidth sensitivity, instruction mix, and cache-line use, for Intel GPUs, multi-tile architectures, and VNNI and ISA support.
Extensions for TensorFlow and extensions for PyTorch deliver significant performance gains with native support for Intel GPUs and CPUs. Advanced optimizations and features provide additional capabilities to process large and complex AI workloads at scale.
- Intel® Optimizations for XGBoost provides new optimizations for GPUs, giving a choice of running on all of Intel’s CPUs and GPUs.
- Intel® Extension for Scikit-learn improves the handling of sparse data for better analytics and machine learning performance by using new K-means and low-order algorithms. Python developers now have more options for performance gains with two new algorithms.
- Intel® Distribution of Modin accelerates data manipulation for AI performance, efficiency, and innovation and supports Intel GPUs. Data management enhancements focus on interactive job performance, benchmark competitiveness, and achieving efficient data ingestion.
- Intel® Neural Compressor adds support for Intel GPUs and simplifies optimization across Intel AI execution providers with an integrated Neural Network Compression Framework for a seamless user experience and resource savings. Now supports TensorFlow 2.14, PyTorch 2.2, and ONNX-RT 1.15.
Standards – We deliver leading support
Our commitment to open standards is unequaled. We know that open standards, with open governance, are highly valuable in helping make your coding investment portable, performance portable, and free of vendor lock-in.
Reflecting our unwavering and constant emphasis on standards, this release strongly supports key standards including Python, C, C++, Fortran, OpenMP, MPI, SYCL*, and oneAPI-UXL.
Our latest C++ compiler features strong OpenMP support and support toward our goal of having full SYCL 2020 conformance soon. The definitive book for learning the use of standard C++ with SYCL released a second edition recently - grab a free (PDF) copy from the Apress website.
We challenge you to find anyone else supporting C, C++, and Fortran better than we do. We love standard C, C++, and Fortran – and it shows in how well we support them.
- OpenMP in both C/C++ and Fortran compilers:
- OpenMP application programming 1.x, 2.x, 3.x, 4.x, 5.0, 5.1, 5.2, and much of the latest TR12 (aka “future 6.0”) (detailed OpenMP standard implementation status list here)
- Our C/C++ compiler:

- C++17 and C17 are the default language standards for our C/C++ compiler. Other versions (including much of C++23) can be selected using the std command line option, and command line options enable OpenMP and SYCL support.
- Conforms to C++20, C++17, C++14, and C++11 while supporting many C++23 features already.
- Conforms to C17, C11, and C99
- Of course, this includes support for parallel STL (pSTL) and some exciting new innovations for ease of use, which I will describe later in this blog.
- SYCL 2020 Specification is almost completely supported (detailed SYCL standard implementation status is here), and work is progressing rapidly towards SYCL 2020 conformance.
- More detailed C++ standard implementation status list here.
- Our Fortran compiler:
- Supports some Fortran 2023 features.
- Conforms to 2018, 2008, 2003, 95, 90, 77, and 66 standards, plus supports high compatibility with Visual Fortran, DEC Fortran 90 and VAX FORTRAN 77.
- Of course, this includes Coarray and DO CONCURRENT. DO CONCURRENT supports a reduce clause and GPU offload.
- More detailed Fotrn standard implementation status is here.
- The MPI library:
- MPI-1, MPI-2.2 and MPI-3.1 specification conformance
- MPI 4.0 supported features: Large Counts
- Interconnect independence
- C, C++, Fortran 77, Fortran 90, and Fortran 2008 language bindings
- Amazon AWS/EFA
- Google GCP support
- More detailed MPI standard implementation status is here.
- oneAPI and UXL
- Full oneAPI support
- We are a founding member of UXL and will continue to provide technical contributions and support in our products.
Linux Foundation with UXL and HPSF
Last quarter, we joined the Linux Foundation creation of the “Unified Acceleration (UXL) Foundation.” UXL promotes an open, unified standard accelerator programming model that delivers cross-platform performance and productivity. Intel contributed the oneAPI specification and several open-source projects to this effort. Our tools reflect our strong support of oneAPI and UXL.
Earlier this week, we joined the Linux Foundation's announcement of an intent to form the “High Performance Software Foundation (HPSF).” Jeff McVeigh (corporate VP and GM, Intel Software Engineering Group) emphasized, "Open standards are vital to accelerate innovation in the computing ecosystem.” We look forward to how we can best support HPSF as it comes together next year.
Performance and Innovation
We remain very pleased that C++, with SYCL support, shows competitive results on NVIDIA and AMD GPUs. I encourage you to look at Ruyman Reyes' blog published earlier this year, “SYCL Performance for NVIDIA and AMD GPUs Matches Native System Language.” The results demonstrate higher or comparable performance of SYCL workloads on NVIDIA and AMD GPUs vs. native system language (CUDA for NVIDIA or HIP for AMD)." Recently, the tests were re-run to compare NVIDIA H100 CUDA vs. SYCL (and updated AMD MI250 results too). Same result: SYCL code is portable and competitive with CUDA (or HIP) performance. You can sum it up as “it's just compiler variations” – in other words, some are faster, and some are slower, but generally, they are equivalent. It’s about the compiler, not that language. Except, of course, SYCL offers a multivendor multiarchitecture approach that CUDA and HIP do not.
Here are recent results the team achieved as updates to the results in Ruyman’s earlier blog.
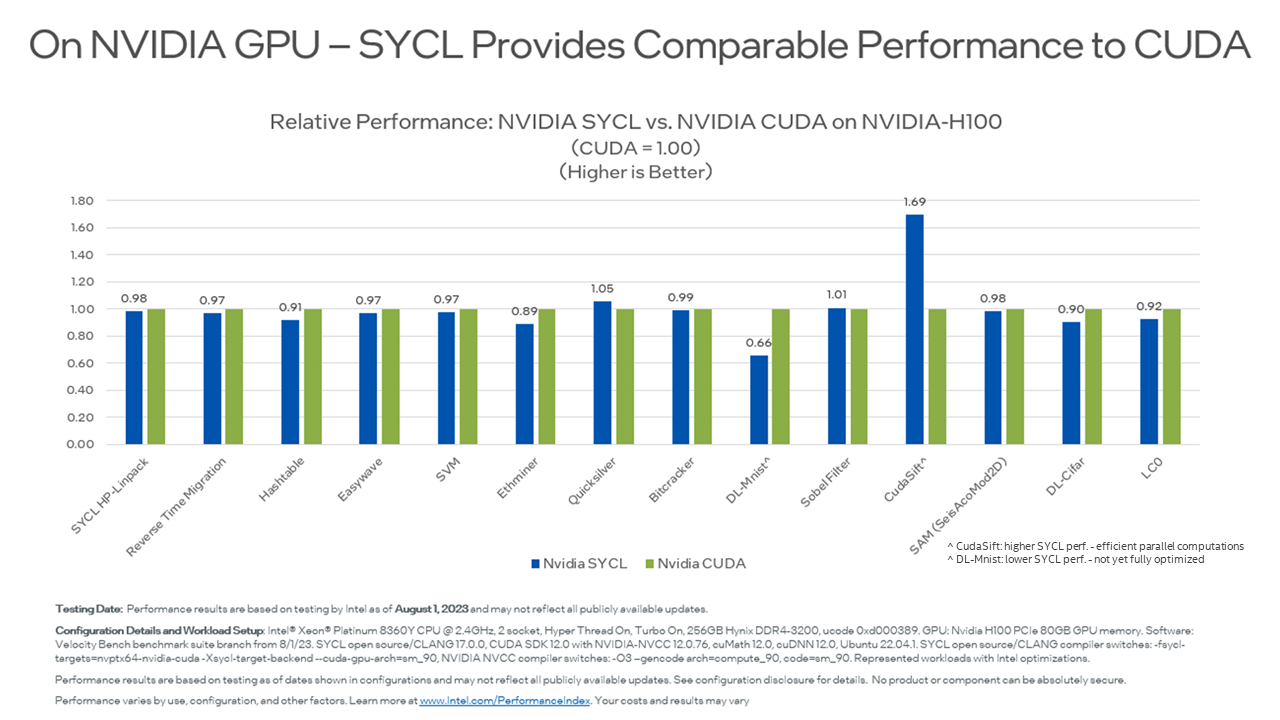
C++ with SYCL is highly performant on Nvidia GPU and performs comparably to native CUDA code for these tested workloads. The development environment and supporting components (compilers, tools, libraries) are highly efficient and competitive.
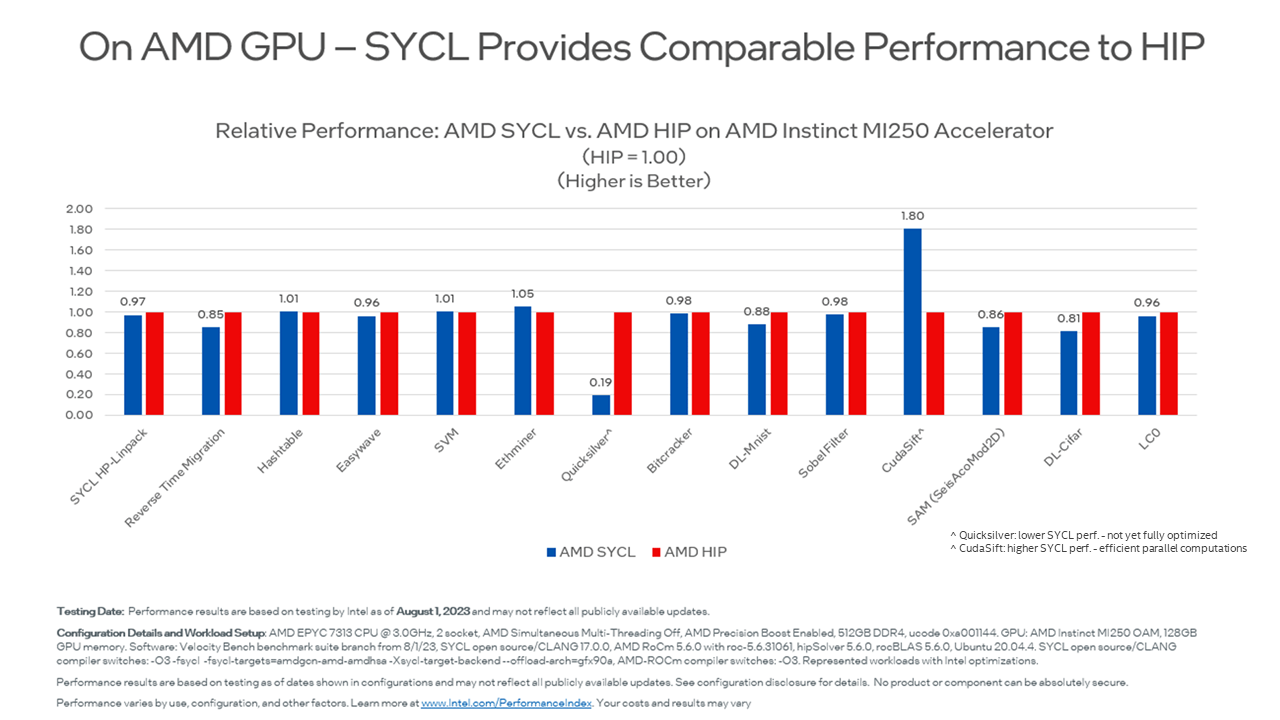
C++ with SYCL is highly performant on AMD GPU and performs comparably to native HIP code for these tested workloads. The development environment and supporting components (compilers, tools, libraries) are highly efficient and competitive.
A rapidly growing list of success stories with significant applications migrated from CUDA to C++ with SYCL. A sampling includes:
- Results from the Atlas Experiment at the CERN's Large Hadron Collider for GPU-based track reconstruction found the vastly more portable SYCL code to be “very close to native CUDA code executing the same algorithm.” See the detailed report here.
- Numerical integration work that found “the oneAPI ports often achieve comparable performance to the CUDA versions, and that they are at most 10% slower.” See the detailed report here.
- A Poisson solver using a conjugate gradient method implemented originally in CUDA and migrated to the modern vendor-agnostic SYCL programming model, allowing experimentation with the same codebase on both CPU and GPUs. SYCL adoption opens diverse hardware architecture sets, ensuring stable and consistent performance across the board and reducing development and software stack maintenance efforts. See the detailed report here.
- Technical University of Darmstadt migrated AutoDock-GPU from CUDA to SYCL. The migrated SYCL code for CPUs is now faster than the original OpenCL for all local search methods and test cases… For GPUs, …it is possible to further reduce docking times by up to 1.88× compared to those on an NVIDIA A100 GPU. See the detailed report here.
Our adoption of LLVM for our compilers allows popular LLVM sanitizers to work well with our compilers as of this release. This is a great way to catch memory leaks, uninitialized memory, thread data races, potential deadlocks, and many other errors in your code.
The list of performance-enhancing additions is very large – here are a few to whet your appetite:
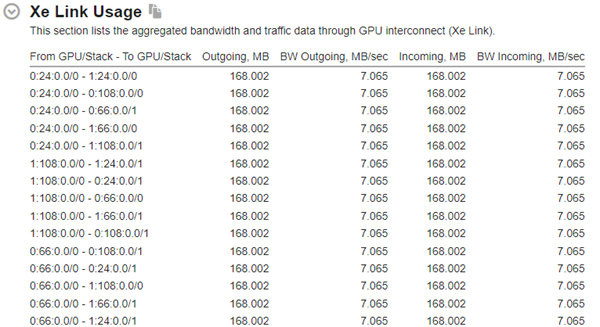
- Intel® VTune™ Profiler enables developers to understand cross-GPU traffic and bandwidth through Intel® Xe Link for each node and if and why implicit USM data movement is causing performance inefficiencies.
- oneMKL library integrates vector math optimizations into RNGs for HPC simulations, statistical sampling, and more on X86 CPUs and Intel GPUs. Supports Vector Math for FP16 datatype on Intel GPUs. Delivers high-performance benchmarks (HPCG, HPL, and HPL-AI) optimized for Intel® Xeon® CPU Max Series and Intel® Data Center GPU Max Series. SYCL library binary partitioning results in a smaller shared objects footprint for applications that use subdomains.
- Intel® Integrated Performance Primitives helps users securely transmit data faster with Intel® Advanced Vector Extensions (Intel® AVX)-2 optimizations for the AES-GCM algorithm and Intel® AVX-512 optimizations for the RSA algorithm.
- Intel® oneAPI DPC++ Library optimizes compute node resource utilization to choose between round-robin, load-based, and auto-tune policy to schedule work on available computing devices.
- Intel® oneAPI Threading Building Blocks thread composability manager provides greater flexibility and workload performance when nesting oneTBB and OpenMP threads.
- Intel® MPI library provides more efficient message passing with MPI RMA (one-sided communications) via CPU and GPU-initiated communications.
- Intel® Distribution for GDB improves debugging by boosting the debugger performance; refines the UI across the command line, Visual Studio*, and Visual Studio Code*; and provides advanced scheduler locking for fine-tuned lock control to debug applications for Intel CPUs and GPUs efficiently.
Notable Forward Looking Innovations
Several innovations are listed as “preview” items, code words for “we want community feedback before we consider this a full product feature.” This means Intel will bend the API and implementation based on feedback.
- New support in this release for SYCL Graph adds an important capability for additional performance through reduced GPU offload overhead. SYCL Graph supports recording work submitted to a queue using buffers (and their accessors) with implicit dependencies. SYCL Graph also enables developers to write explicit dependencies across command groups and store them in graph objects. The graph object can be submitted multiple times to a SYCL queue, reducing the host overhead and simplifying graph-based application implementation. SYCL graph is currently an experimental extension (feedback welcome.) implemented in the DPC++ open source compiler project (and therefore our product C/C++ compiler in this release). Support for SYCL Graph on Intel and NVIDIA GPUs is available now (open source). Product timing (when things were pulled from open source) means that Intel GPU support is in 2024.0 (now), and NVIDIA GPU support should come with next quarter’s 2024.1 update.

- Dynamic selection is an experimental feature in oneDPL that provides functions for choosing a resource using a selection policy. The selection policies in this release include a fixed_resource_policy that always selects a specified device, a round_robin_policy that rotates between devices for offload, a dynamic_load_policy that chooses the device that has the fewest outstanding submissions, and an auto_tune_policy that chooses the best device to use based on runtime profiling information. Dynamic selection aims to improve ease of use by assisting developers in choosing a device and providing mechanisms for load balancing across devices. You can read more in the Dynamic Selection section of the oneDPL Guide (oneapi-src.github.io/oneDPL/) and by exploring the oneAPI samples for dynamic selection at github.com/oneapi-src/oneAPI-samples/tree/master/Libraries/oneDPL/dynamic_selection
- C++ Parallel STL supports GPU offload through explicit oneDPL calls, which many already use, or a new (preview feature) compiler option to invoke automatically. We will be excited to hear from you about how you see the pros/cons of each for your particular needs.
- Thread composability to head off thread oversubscription in OpenMP
- VTune preview feature for technical evaluation: Profile offloaded code to NPUs (neural processor units) to understand how much data is transferred from NPU to DDR memory and identify the most time-consuming tasks.
Housekeeping: directory layout simplification
One of my favorite new features is a housekeeping one on which we had lots of input: directory layout simplification. I helped plan this over the past two years. The result is that the tools now support much fewer additions to environment variables, including path, various library paths, and include path. This simplifies scripts, reduces pressure on the size of environment variables, and makes looking at environment variables easy on the eyes. Historically, most of our tools started as individual products installed in their own directories (bin, lib, include…). That led to an explosion in what must be added to environment variables (notably when running setvars.sh). We initially thought, “Let’s just collapse them all into common directories.” We shared this thinking (proposal) with many of you and quickly found that many installations have clever and important uses in mixing and matching release tools to give a level of control developed from decades of experience and customization needs. We listened: the directory simplification does (by default) simplify paths while still offering the flexibility many of you need and use in production use.
When multiple toolkit versions are installed, the Unified layout ensures that your development environment contains the correct component versions for each installed version of the toolkit. To ensure no loss of capability and backward compatibility, the directory layout used before the 2024 release "the Component Directory Layout" is also supported on new and existing installations.
For detailed information about the Unified layout, including how to initialize the environment and advantages with the Unified layout, refer to Use the setvars and oneapi-vars Scripts with Linux and Use the setvars and oneapi-vars Scripts with Windows.
This housekeeping item is a non-trivial example of how we keep making our tools even better in every way we can.
We are here for you.
This release continues our unwavering commitment to be your favorite tool vendor for your most demanding AI, HPC, and enterprise applications:
- Delivered strong support of open standards
- Decades of experience and reliability
- Relentless pursuit of high performance
- Continuous innovation
Use the latest tools today.
Want to learn more? You can find the full list of the 2024 tools updates, plus even more detail in the release notes. As with the prior release, you can download the latest tools directly from Intel or via popular repositories.