Introduction
This guide is for users who are already familiar with Open vSwitch* (OvS) with DPDK* (Data Plane Development Kit). It provides recommendations for configuring hardware and software that will provide the best performance in most situations. However, note that we rely on the users to carefully consider these settings for their specific scenarios, since OvS and DPDK can be deployed in multiple ways.
Open vSwitch is a multilayer software switch for monitoring, queuing, and shaping network traffic. It can be used for VLAN as well as tunnel (VXLAN, Geneve) isolation and traffic filtering. It is well-suited to function as a virtual switch in VM environments. DPDK is the Data Plane Development Kit used to accelerate packet processing workloads.
The 4th generation Intel® Xeon® Scalable Processor platform is an unique, scalable platform optimized for different workload acceleration including HPC, AI, big data, and networking with higher performance and total cost of ownership (TCO) efficiency.
Improvements of particular interest to this workload are:
- More cores with up to 56 cores per socket and up to 448 cores in an 8-socket platform
- Increased memory bandwidth and speed with DDR5 (versus DDR4)
- High throughput for latency-sensitive workloads with up to 2x I/O bandwidth with PCIe* 5.0
- Intel® Advanced Vector Extensions
- Intel® Data Streaming Accelerator (Intel® DSA)
Many OvS deployments today use virtual interfaces like vHost/virtio extensively to steer packets to and from the virtual machines (VM). These virtual interfaces use packet copy to transfer messages between the VM and OvS running on the host. In such scenarios, the computational cost of performing those copies can be significant, especially for larger packet sizes. Intel® DSA is used to asychronously offload these expensive CPU packet copy operations between the Guest or VM and OvS.
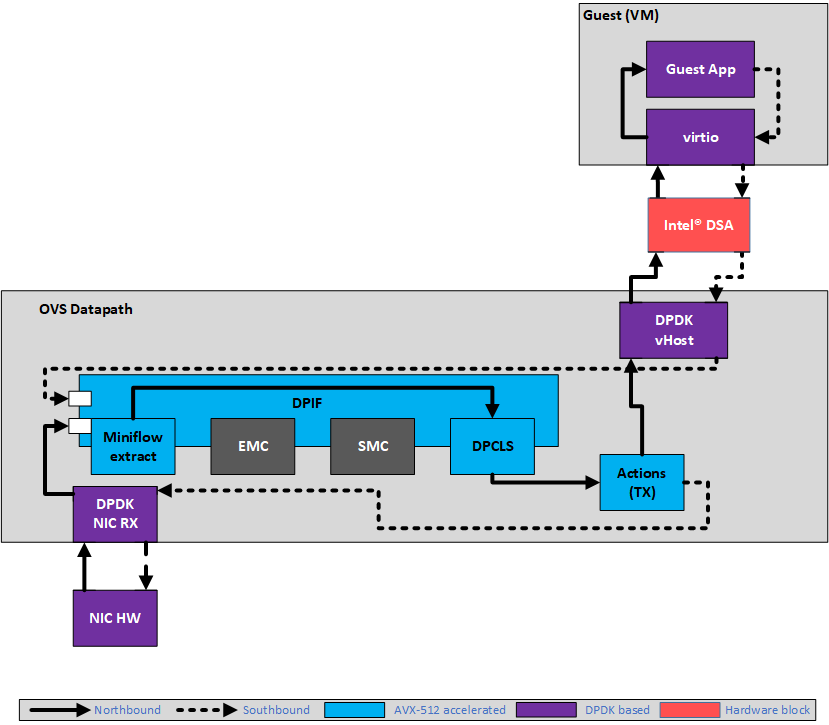
The preceding diagram shows Intel DSA use in a PVP (PHY-VM-PHY) setup.
Software Configuration
Software configuration including tuning the operating system is essential. General purpose default settings almost never yield the best performance for specialized workloads.
Linux Kernel Optimization Settings
The 5.11+ kernel is required for the availability of the DSA idxd driver. If the kernel requirements cannot be met, users can bind DSA devices to userspace drivers like vfio-pci.
In addition, following are Linux* boot parameters:
Host Grub
default_hugepagesz=1G hugepagesz=1G hugepages=<huge_pages> isolcpus=<core_list> rcu_nocbs=<core_list> nohz_full=<core_list> intel_pstate=disable processor.max_cstate=1 intel_idle.max_cstate=1 intel_iommu=on,sm_on iommu=on nmi_watchdog=0 audit=0 nosoftlockup hpet=disable mce=off tsc=reliable numa_balancing=disable workqueue.power_efficient=false
VM Grub
default_hugepagesz=1G hugepagesz=1G hugepages=<huge_pages> isolcpus=<core_list> rcu_nocbs=<core_list> intel_pstate=disable processor.max_cstate=1 intel_idle.max_cstate=1 nmi_watchdog=0 audit=0 nosoftlockup
Other general performance recommendations applicable to this workload are listed in the latest performance report.
Required Tools and Information
Device availability
Since Intel DSA is enumerated as a PCI device, you can use lspci to query its presence.
lspci -vvv | grep "0b25"
Output will look like:
6a:01.0 System peripheral: Intel Corporation Device 0b25
where 0b25 is the device ID for Intel DSA on 4th gen Intel Xeon processors. Query Intel DSA using the device ID due to the absence of pci-id database entries for them at this point.
Alternatively, you can use the DPDK dpdk-devbind.py script to check for DMA availability on the platform supported by DPDK, using:
$DPDK_DIR/usertools/dpdk-devbind.py --status-dev dma
Output will look like:
DMA devices using kernel driver
===============================
0000:e7:01.0 'Device 0b25' drv=idxd unused=vfio-pci
Accel Config
This is the tool used to configure Intel DSA instances when bound to kernel idxd driver: https://github.com/intel/idxd-config
Example:
After building and installing the tool per the documentation, to configure one Intel DSA instance with four dedicated work queues (DWQ) each with 32 queue depth/batch descriptors, the following set of commands can be used:
accel-config disable-device dsa0
accel-config config-engine dsa0/engine0.0 --group-id=0
accel-config config-engine dsa0/engine0.1 --group-id=1
accel-config config-engine dsa0/engine0.2 --group-id=2
accel-config config-engine dsa0/engine0.3 --group-id=3
accel-config config-wq dsa0/wq0.0 --group-id=0 --mode=dedicated --priority=10 --wq-size=32 --type=user --name=dpdk_ovs
accel-config config-wq dsa0/wq0.1 --group-id=1 --mode=dedicated --priority=10 --wq-size=32 --type=user --name=dpdk_ovs
accel-config config-wq dsa0/wq0.2 --group-id=2 --mode=dedicated --priority=10 --wq-size=32 --type=user --name=dpdk_ovs
accel-config config-wq dsa0/wq0.3 --group-id=3 --mode=dedicated --priority=10 --wq-size=32 --type=user --name=dpdk_ovs
accel-config enable-device dsa0
accel-config enable-wq dsa0/wq0.0 dsa0/wq0.1 dsa0/wq0.2 dsa0/wq0.3
accel-config list
ls /dev/dsa # this command should output: wq0.0 wq0.1 wq0.2 wq0.3
Note While configuring Intel DSA work queues using accel-config, it is important to name the work queues starting with prefix dpdk_ (as in the previous example) to be recognized by DPDK.
Intel DSA Perf Micros
This tool is used to validate different Intel DSA metrics like throughput and operations per second. It is recommended to use this tool to test Intel DSA before using it with OvS or any application.
Example:
After building the tool as per the documentation, and configuring Intel DSA using the above commands, you can use the following command to check Intel DSA throughput for packet sizes ranging from 64 B to 4 KB:
b=32;qd=32;n=`expr $b \* $qd`;for sz in 64 128 256 512 1k 1518 2k 4k; do y=`sudo ./src/dsa_perf_micros -b$b -n$n -i1000 -jcf -s$sz -zD,D -K[0]@dsa0,0,[1]@dsa0,1,[2]@dsa0,2,[3]@dsa0,3 |egrep "GB per sec"|cut -d ' ' -f5,17`; echo $sz $y;done
Similarly, for vfio-pci/userspace driver bound devices, the command becomes:
b=32;qd=32;n=`expr $b \* $qd`;for sz in 64 128 256 512 1k 1518 2k 4k; do y=`sudo ./src/dsa_perf_micros -b$b -n$n -i1000 -jcf -s$sz -zD,D -u |egrep "GB per sec"|cut -d ' ' -f5,17`; echo $sz $y;done
For more details on the options used above, please refer to the documentation/command line help options of the tool.
For a more detailed description on how to use Intel DSA, see the Intel DSA user guide.
DPDK with Intel DSA Support
DSA driver support for DPDK has been added since 21.11 as a “dmadev” device.
More information about the DPDK DSA driver could be found at: http://doc.dpdk.org/guides/dmadevs/idxd.html.
Note Current DPDK with Intel DSA driver supports only dedicated work queues (DWQ) and not shared work queues.
After configuring the Intel DSA device through accel-config/binding to userspace driver like vfio-pci, you can also use the "dmafwd" sample app in DPDK to validate its performance. Assuming DPDK libraries are already built, build the dmadfwd sample app and then run:
cd $DPDK_BUILD_DIR;
meson configure -Dexamples=dma
ninja
./examples/dpdk-dma -l <core_list> <traffic source> -- -i 1 -s 2048 -c hw -p 0x1 -q 1
where the traffic source can be a NIC port/pcap device/null device etc.
For more information about the app, see the Sample Application User Guide.
Note Since dmadev library supports telemetry, you can get the Intel DSA device info and statistics using the telemetry interface when used by a DPDK app. For more information, see Querying Device Statistics.
Code Availability
DPDK
The DPDK repo is located at: https://github.com/istokes/dpdk/tree/dma-tracking
Once cloned, ensure you are on the branch: dma-tracking:
cd dpdk
git checkout dma-tracking
Build DPDK as usual as there are no build options/changes required to enable DSA.
Open vSwitch (OvS)
Locate and clone the OvS repository.
Once cloned, ensure you are on the branch dpdk-dma-tracking:
cd ovs
git checkout dpdk-dma-tracking
Build OvS as usual as there are no build options or changes required to enable Intel DSA.
Note The DPDK vhost and dmadev APIs used in OvS for this feature are currently marked experimental.
Enable Intel DSA in OvS with DPDK
Intel DSA can be enabled in OvS using the following command:
ovs-vsctl --no-wait set Open_vSwitch . other_config:vhost-async-support=true
- Issuing this requires ovs-vswitchd daemon to be restarted.
- The default value is false.
- It is required to have Intel DMA devices visible to DPDK before OvS launch either by binding them to the userspace driver like vfio-pci or through other facilities as mentioned in the DPDK driver documentation.
- The current assignment model is one DPDK dmadev device per data plane thread in OvS. If no Intel DMA device is found for that thread, it will fall back to perform CPU copy, but may impact performance. Hence, users are recommended to ensure there are enough Intel DMA devices available before launching OvS.
- The NUMA-aware assignment of dmadev devices to data plane threads is automatically handled by iterating over the available dmadev devices (based on dmadev-id) and assumes there is only one vchannel supported per device.
- For more information on the dmadev design/architecture, see the DPDK documentation.
Performance Tuning
CPU Copy Optimization for Small Packets
Intel DSA copy is observed to be better performant for large packets compared to CPU, but for small packets, the cost of creating the descriptor and awaiting the completion is significant compared to the time to do the copy on the CPU. This can lead to scenarios where small copies are faster when performed on the CPU. So, you can get the best of both modes if Intel DSA is used for large packets and CPU for small packets while preserving the packet ordering.
Hence, you have the flexibility to choose a threshold (in bytes) at runtime beyond which packets must be offloaded to dmadev by the vHost library using the below command:
ovs-appctl netdev-dpdk/set-vhost-async-thresh <threshold_size>
The default threshold size is set to 128 bytes.
Similarly, you can also fetch the current threshold set using the command:
ovs-appctl netdev-dpdk/get-vhost-async-thresh
VFIO-PCI or Kernel Intel DSA Driver
Based on our experiments, for Intel DSA 1.0 on 4th gen Intel Xeon processors, it is recommended to use vfio-pci driver-bound Intel DSA devices over the kernel Intel DSA driver-bound devices for this workload.
Intel® Advanced Vector Extensions 512 (Intel® AVX-512)
Most parts of the packet processing pipeline in OvS (like Miniflow Extract, DPCLS, DPIF and others) have been optimized with Intel AVX-512. Since it drastically reduces the processing cycles of these precursor steps to vHost maddev offload, it increases the rate of dmadev enqueue and therefore elevates the overall OvS throughput. Hence, enabling Intel AVX-512 along with dmadev offload is highly recommended to make the most out of the features offered by the CPU or platform.
Enable Intel AVX-512 support in OvS and DPDK by using the following commands:
Before launching ovs-vswitchd:
ovs-vsctl --no-wait set Open_vSwitch . other_config:dpdk-extra="--force-max-simd-bitwidth=512"
After launching ovs-vswitchd:
ovs-appctl dpif-netdev/miniflow-parser-set study
ovs-appctl dpif-netdev/dpif-impl-set dpif_avx512
ovs-appctl dpif-netdev/subtable-lookup-prio-set avx512_gather 3
ovs-appctl odp-execute/action-impl-set avx512
For more details on the above commands, refer the to the OvS documentation.
In tests, we have observed a significant gain in performance when Intel AVX-512 is enabled alongside Intel DSA.
Output Batching
For better batch descriptor utilization that can lead to improved throughput, especially for scattered traffic, increase the size of the output batches by configuring the tx-flush-interval option:
ovs-vsctl set Open_vSwitch . other_config:tx-flush-interval=<time in microseconds>
A tx-flush-interval value of 50 microseconds has shown to provide a good throughput increase in our tests.
Note Additional throughput may come at the cost of latency. For more details, check the OvS documentation.
NUMA Awareness
In multi-NUMA systems, all OvS PMD cores, VM, NIC, and Intel DSA should be on the same NUMA. OvS currently uses a NUMA-aware Intel DSA assignment scheme based on the PMD core. If no Intel DSA devices are found on the same PMD core NUMA, it tries to assign an Intel DSA from another one. When this happens, OvS issues a warning like the following:
No available DMA device found on numa node <numa_id>, assigning DMA <dmadev_name> with dev id: <dmadev_id> on numa <numa_id> to pmd for vhost async copy offload.
Intel DSA WQ Queue-Depth
You may see a minor drop in throughput when Intel DSA runs out of available batch descriptors or slots in its DWQ and CPU copy is used as a fallback option. This behavior is possible for cases where the configured Intel DSA WQ queue-depth is low and/or the number of packets per batch is low, leading to suboptimal use of Intel DSA batch descriptors. Hence, to avoid such scenarios, its recommended to configure the WQ queue-depth to a sufficient value, such as 16/32 per WQ. For vfio-pci bound Intel DSA device, DPDK by default allocates the WQ queue-depth based on the total WQ-size available per device (128 in 4th Gen Xeon Scalable processors) by splitting them uniformly(8 DWQ in 4th Gen Xeon Scalable processors, hence 16 queue-depth per DWQ).
Hugepage memory
Like the DPDK documentation suggests, experiments reveal that using 1 GB hugepages compared to 2 MB hugepages results in better performance for OvS with DPDK on Intel DSA.
Other Observations
Latency Impact
The maximum and average latency at a fixed packet rate with Intel DMA offload may result in better latencies for large packet sizes compared to CPU. Also, at peak NDR bandwidth, for a given packet size, DMA offload may result in higher latencies compared to CPU but it is important to note that the bandwidth difference is quite vast (DMA offload bandwidth being higher) in such cases.
Packet Segmentation
Offloading costs to Intel DSA may increase with segmented/chained packets, for example, packets whose size is beyond the mbuf size (default size of 2 KB) being split into multiple mbufs. This implies more Intel DSA enqueues per packet and therefore may increase the offload cost and impacts performance.
Terminology
| Abbrevation | Description |
|---|---|
| DPIF | DataPath InterFace, OvS datapath component that represents the software datapath as a whole |
| DPCLS | Datapath Classifier, OvS software datapath component that performs wildcard packet matching |
| D2K | Direct-to-UPI |
| EMC | Exact Match Cache, OvS software datapath component that performs exact packet matching |
| IP | Internet Protocol |
| MFEX | Miniflow Extract |
| NIC | Network Interface Card |
| NUMA | Non-Uniform Memory Access |
| NDR | No Drop Rate |
| OvS | Open vSwitch |
| PMD | Poll Mode Driver |
| SMC | Signature Match Cache, OvS software datapath component that performs wildcard packet matching |
| SNC | Sub-NUMA Cluster |
| Intel® SST | Intel® Speed Select Technology |
| Intel® SST-BF | Intel® Speed Select Technology – Base Frequency (Intel® SST-BF) |
| VXLAN | Virtual Extensible LAN |
| VLAN | Virtual local area network |
| XPT | eXtended Prediction Table |
Feedback
We value your feedback. If you have comments on this guide or are seeking something that is not part of this guide, please let us know.