Fine-tuning is the process of using the weights of a trained neural network as the starting values for training a new neural network. In simple words, fine-tuning means making small adjustments to improve the performance of a model for a specific task.
Previously, training a model entailed starting with randomized weights and adjusting them during the lengthy process of learning on a massive dataset when creating new neural networks. But now, the best practice is to start with a pretrained model on a large dataset and modify it. This is particularly useful for language models. In this way, you can take a trained model on general knowledge of the language. At that point, the model already knows how the natural language works, and the process of fine-tuning can focus on a narrow task, such as classifying a sentiment, an emotion, a topic of text, and in the case of generative language models, responding to a selected topic or in a particular way.
This article showcases a code sample on how to fine-tune a BERT tiny model for an emotion classification task using quantization-aware training from Intel® Neural Compressor.
Fine-tuning helps to use pretrained language representations for specific downstream tasks, enabling effective text or emotion classification in various applications, and the fine-tuned models are based on the knowledge of emotional vocabulary and do not require training data. This process of fine-tuning can be expanded to any text classification task where a task-specific vocabulary is available.
Why Is Fine-Tuning Important?
Fine-tuning has the following advantages over training neural networks from scratch:
- Saving time and resources. This allows developers to use the knowledge that has already been learned by a pretrained model.
- Improving performance and accuracy of the model. Data scientists and developers can create a model that is optimized for the new problem by adapting a pretrained model to a new task. This can lead to improved performance on the new task, especially if the pretrained model was trained on a large dataset.
Using Intel Neural Compressor for Fine-Tuning Optimization
Intel Neural Compressor helps to optimize the fine-tuning process using quantization-aware training. Quantization-aware training replicates inference-time quantization and all the weight adjustments during training are made while being aware of the fact that the model will ultimately be quantized. In other words, it provides quantization to the model during training (or fine-tuning like in our case) based on the provided quantization configuration.
Intel Neural Compressor offers configuration for quantization-aware training. To perform quantization-aware training, import the neural_compressor package and initialize the appropriate configurationusing the following code:
from neural_compressor import QuantizationAwareTrainingConfigquantization_config = QuantizationAwareTrainingConfig()
To use this configuration during the fine-tuning process, you can use INCTrainer, an optimize trainer from Hugging Face Optimum* for Intel. Also, provide all necessary parameters:
- Initialized model and tokenizer
- Configuration for quantization aware training
- Training arguments
- Datasets for training and evaluation
- Prepared metrics that allow you to see progress in training
Note To install Optimum Intel with Intel Neural Compressor accelerator, use:
pip install --upgrade-strategy eager "optimum[neural-compressor]"
The following example shows how to use INCTrainer:
from optimum.intel import INCTrainer trainer = INCTrainer(model, quantization_config, args, train_dataset, eval_dataset, compute_metrics, tokenizer)
Code Sample
Emotion Dataset
The Emotion dataset from Hugging Face is used for the code sample. This dataset has two different configurations, split and unsplit, both with different texts collected from X* (formerly Twitter*) messages.
In this code sample, we are using split configuration. It contains 20,000 examples in total, and is split into three datasets:
- Train (16,000 texts)
- Test (2,000 texts)
- Validation (2,000 texts)
We use a split configuration dataset instead of an unsplit configuration as it contains over 400,000 texts, which is overkill for fine-tuning.
The dataset contains six different labels represented by digits from 0 to 5. Every digit symbolizes a different emotion:
0 - sadness
1 - joy
2 - love
3 - anger
4 - fear
5 – surprise
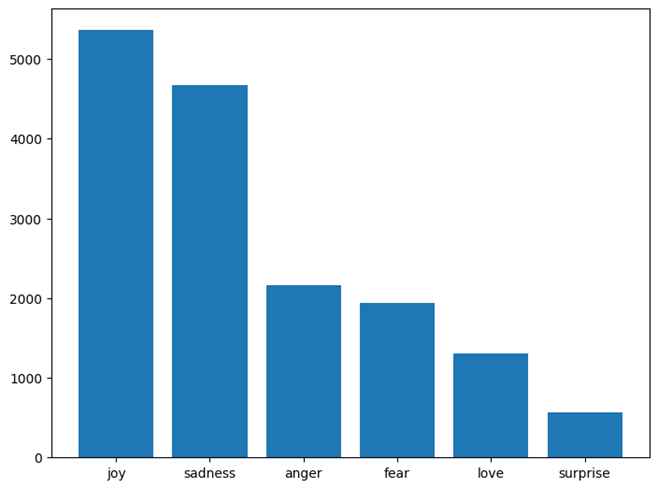
The following diagram shows the class distribution of the dataset. We can observe that the distribution of classes in the dataset is not equal, but the train, test, and validation distributions are similar.
A few example sentences from the dataset are:
| text (string) | label (class label) |
|
"i didn't feel humiliated" |
0 (sadness) |
|
"i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake" |
0 (sadness) |
|
"im grabbing a minute to post i feel greedy wrong" |
3 (anger) |
|
"i am ever feeling nostalgic about the fireplace i will know that it is still on the property" |
2 (love) |
Implementation
The following steps are implemented in the code sample:
- Load model and tokenizer. In this code sample, we use a small model, model_id = prajjwal1/bert-tiny. You can also use a different model, but remember that using larger models can be resource consuming and time consuming.
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=6) tokenizer = AutoTokenizer.from_pretrained(model_id, model_max_length=512)When loading the model, we should also specify the number of labels for the model used.
- Load the dataset. In the code sample, the dataset parameters, like distribution or example texts, are also explored.
dataset = load_dataset("emotion", name="split") - Perform tokenization on the loaded dataset. Create a function that takes every text from dataset and tokenize it with maximum token length (128).
def tokenize_data(example): return tokenizer(example['text'], padding='max_length', max_length=128) dataset = dataset.map(tokenize_data, batched=True) - Prepare evaluation metrics. We are using accuracy as a metric showing how well the model is doing. To do that, we created compute_metrics method, where we take predicted label values and compare them with referenced ones.
metric = evaluate.load("accuracy") def compute_metrics(eval_pred): logits, labels = eval_pred predictions = np.argmax(logits, axis=-1) return metric.compute(predictions=predictions, references=labels) - Prepare configuration. For this fine-tuning process, we use Intel Neural Compressor quantization-aware training configuration.
from neural_compressor import QuantizationAwareTrainingConfig quantization_config = QuantizationAwareTrainingConfig() - Create a trainer with prepared configuration. Use INCTrainer from optimum.intel package.
trainer = INCTrainer( model=model, quantization_config=quantization_config, args=TrainingArguments(save_dir, num_train_epochs=2.0, do_train=True, do_eval=False), train_dataset=dataset["train"], eval_dataset=dataset["validation"], compute_metrics=compute_metrics, tokenizer=tokenizer, ) - Train the model. We are using the train() method available in the created trainer. After training, you can see information about the model printed under *****Mixed Precision Statistics*****
train_result = trainer.train() - Evaluate the model. We are using the evaluate() method on the prepared trainer. It will show results prepared before evaluation metrics (evaluation accuracy and loss).
metrics = trainer.evaluate()
What’s Next?
Try out the preceding code sample to fine-tune your text model on a pretrained BERT-tiny model and see how Intel Neural Compressor optimizes the fine-tuning process using quantization-aware training. Download and try the AI Tools and Intel® Neural Compressor for yourself to build various end-to-end AI applications.
We encourage you to also check out and incorporate other AI and machine learning frameworks and end-to-end tools from Intel into your AI workflow. Learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel's AI software portfolio to help you prepare, build, deploy, and scale your AI solutions.
For more details about the 4th generation Intel® Xeon® Scalable processors, see Intel's AI Platform where you can learn how Intel is empowering developers to run end-to-end AI pipelines on these powerful CPUs.