PyTorch* is a deep learning framework based on the Torch* library and is mainly used for computer vision and natural language processing applications. This framework was developed by Meta and is now part of the Linux* foundation. Intel collaborates with the open source PyTorch project to optimize the framework for Intel® architectures. The newest optimizations and features are first released in Intel® Extension for PyTorch* before upstreaming them into the stock distribution of PyTorch.
This article introduces Intel® Advanced Matrix Extensions (Intel® AMX), the built-in AI accelerator engine in 4th Gen Intel® Xeon® processors, and highlights how it can help accelerate AI training and inference performance using PyTorch.
Intel® AMX in 4th Gen Intel® Xeon® Scalable processors
4th Gen Intel Xeon processors are designed to deliver increased performance, power-efficient computing, and stronger security, while also being optimized for overall total cost of ownership. These processors expand the reach of CPUs for AI workloads.
Intel AMX is a built-in accelerator found on each 4th Gen Intel Xeon processor core, and it helps accelerate deep learning training and inference workloads. Intel AMX architecture consists of two main components:
- Tiles - These are new, expandable 2D register files which are 1kB in size.
- TMUL (Tile Matrix Multiply) - These are the instructions which operate on the tiles to perform matrix-multiply computations for AI.
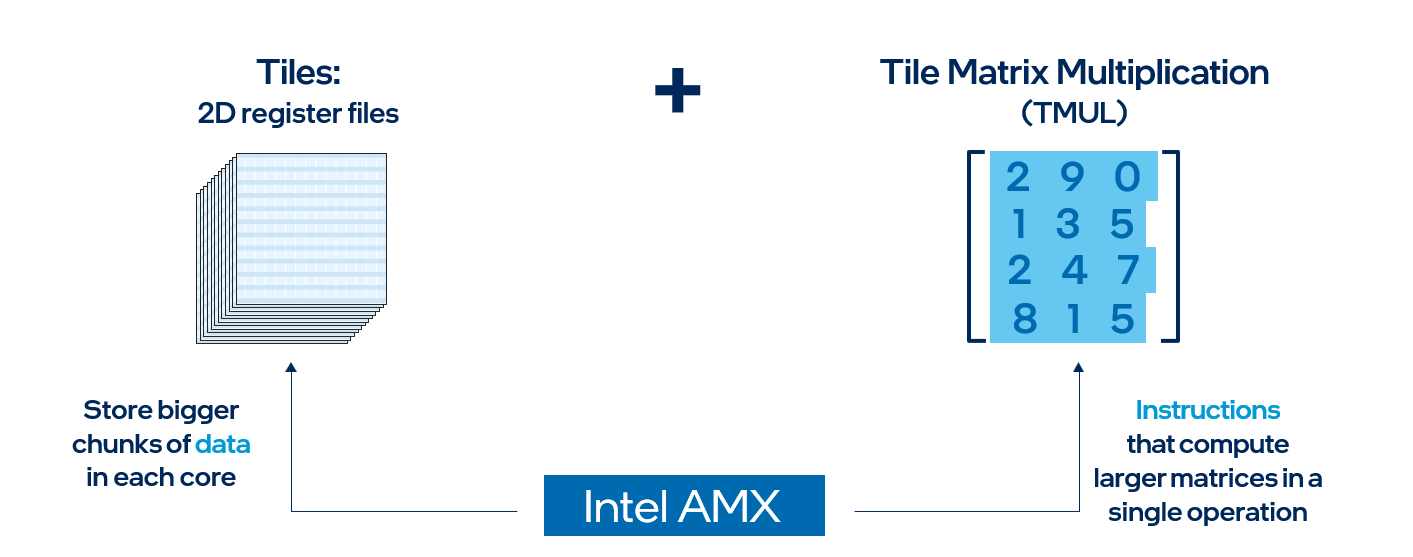
In simple terms, Intel AMX will store larger chunks of data in each core and then compute larger matrices in a single operation. Intel AMX only supports BF16 and INT8 data types, whereas FP32 data types are still supported through Intel® Advanced Vector Extensions 512 (Intel® AVX-512) instructions as found in 3rd Gen Intel Xeon processors. Intel AMX accelerates deep learning workloads such as recommender systems, natural language processing, and image detection. Classical machine learning workloads which use tabular data will use existing Intel AVX-512 instructions. Many deep learning workloads are mixed precision, and 4th Gen Intel Xeon processors can seamlessly transition between Intel AMX and Intel AVX-512 to run code using the most efficient instruction set.
So … What is Mixed Precision Learning?
This is a technique for training a large neural network in which the model's parameters are stored in datatypes of different precision (most commonly floating point 16 and floating point 32) to allow it to run faster and use less memory.
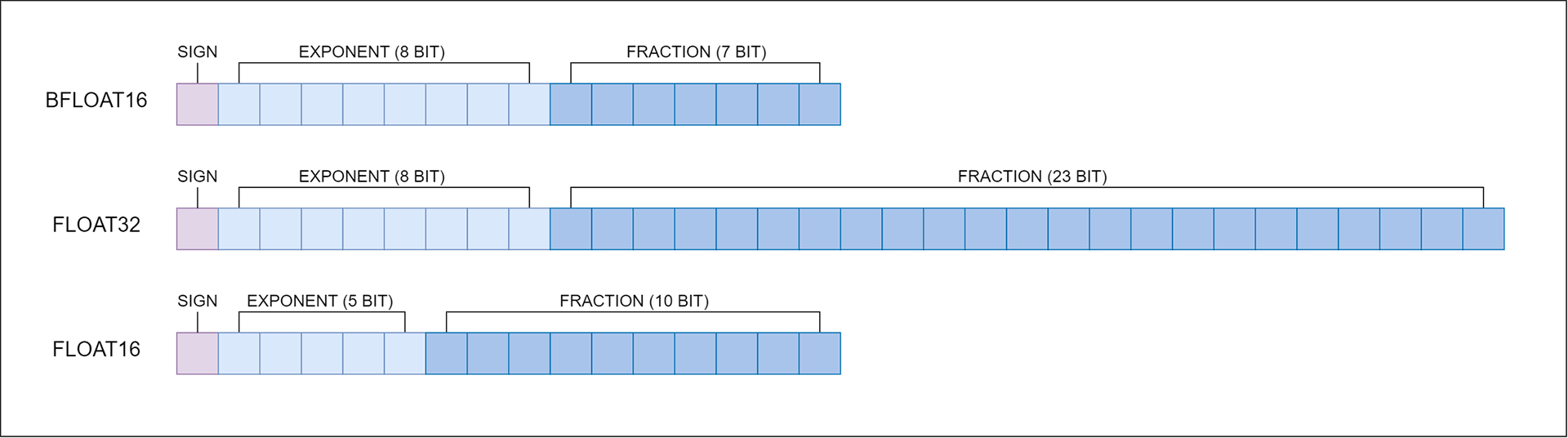
Most models today use the single precision floating-point (FP32) data type, which requires 32 bits of memory. There are, however, two lower-precision data types, float16 and bfloat16 (BF16), which each require only 16 bits of memory. Bfloat16 is a floating-point format that occupies 16 bits of computer memory but represents the approximate dynamic range of 32-bit floating-point numbers. Bfloat16 format is as follows:
- 1 bit - sign,
- 8 bits - exponent,
- 7 bits - fraction.
The comparison between float16, float32 and bfloat16 is shown in the figure:
Intel® Extension for PyTorch*
The Intel extension expands PyTorch with the most up-to-date features and optimizations for an extra performance boost on Intel® hardware. Most of these new features are upstreamed into future versions of the stock implementation of PyTorch. The extension is available as a stand-alone component or as part of the Intel® AI Analytics Toolkit. (Check out the installation guide to install Intel’s extension.)
The extension can be loaded as a Python* module or linked as a C++ library. Python users can enable it dynamically by importing intel_extension_for_pytorch.
- The CPU tutorial gives detailed information about Intel Extension for PyTorch for Intel® CPUs. Source code is available at the master branch.
- The GPU tutorial gives detailed information about Intel Extension for PyTorch for Intel® GPUs. Source code is available at the xpu-master branch.
How to Enable Intel® AMX bfloat16 Mixed Precision Learning on a PyTorch Model
The first step is to check if Intel AMX is enabled on your hardware. On the bash terminal, enter the following command:
cat /proc/cpuinfo
Alternatively, you can use:
lscpu | grep amx
Check the “flags” section for amx_bf16 and amx_int8. If you do not see them, consider upgrading to Linux kernel 5.17 or newer. Your output should look something like this:

Intel Extension for PyTorch automatically detects and dispatches code during runtime. And it does this similarly to Intel® oneAPI Deep Neural Network Library (oneDNN) which, by the way, is an open source and cross-platform library that provides optimized implementations of deep learning building blocks and improves performance of frameworks that you already use. The environment variable ONEDNN_MAX_CPU_ISA can be set during runtime to change the instruction set architecture (ISA), but it is not needed because the default is Intel AMX, the newest one available. The oneDNN documentation on CPU Dispatcher Control will list out all options.
Steps to enable Intel AMX BF16 on PyTorch:
This takes only a few lines of code. It involves importing the Intel Extension for PyTorch library and then passing the torch.bfloat16 datatype into the optimize() function. The last step is to use the torch.cpu.amp.autocast() function. Check out the following examples for training and inference on ResNet50.
Sample code for training:
import torch
import torchvision
# Import the library, best if right after importing torch and/or torchvision
import intel_extension_for_pytorch as ipex
LR = 0.001
DOWNLOAD = True
DATA = 'datasets/cifar10/'
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((224, 224)),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = torchvision.datasets.CIFAR10(
root=DATA,
train=True,
transform=transform,
download=DOWNLOAD,
)
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=128
)
model = torchvision.models.resnet50()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr = LR, momentum=0.9)
model.train()
# ipex.optimize() is the main function to optimize your model. You can specify the data type as well
model, optimizer = ipex.optimize(model, optimizer=optimizer, dtype=torch.bfloat16)
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
# For working with mixed precision whether you are using Intel Extension for PyTorch or not, this line is required
with torch.cpu.amp.autocast():
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print(batch_idx)
torch.save({
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}, 'checkpoint.pth')
Sample code for inference:
import torch
import torchvision.models as models
model = models.resnet50(weights='ResNet50_Weights.DEFAULT')
model.eval()
data = torch.rand(1, 3, 224, 224)
#################### code changes ####################
import intel_extension_for_pytorch as ipex
model = ipex.optimize(model, dtype=torch.bfloat16)
######################################################
# For mixed precision, include torch.cpu.amp.autocast(). For inference, it is highly recommended to use TorchScript to run the model in graph mode for better performance
with torch.no_grad(), torch.cpu.amp.autocast():
model = torch.jit.trace(model, torch.rand(1, 3, 224, 224))
model = torch.jit.freeze(model)
model(data)
Passing in torch.bfloat16 into the optimize() function will cast the model parameters into BF16. torch.cpu.amp.autocast() will run the operations in mixed precision, BF16 in this case.
Training and Inference Optimizations with Intel AMX
Training
This code sample demonstrates how to train a ResNet50 model using the CIFAR10 dataset with Intel Extension for PyTorch. It features the performance improvement of Intel AMX BF16 over FP32.
The following steps are implemented in the code sample:
- Check if the hardware supports Intel AMX by checking the flags in cpuinfo.
- Load the CIFAR10 dataset.
- Set the environment variable ONEDNN_MAX_CPU_ISA:
- DEFAULT if running with Intel AMX
- AVX512_CORE_BF16 if running with Intel AVX-512
- Instantiate the ResNet50 model and use Intel Extension for PyTorch’s optimize() function on the model and training optimizer of choice.
- Train the model in the following run cases, using mixed precision when applicable. Record the training time.
- FP32 (baseline)
- BF16 with Intel AVX-512
- BF16 with Intel AMX
- Compare training times and compute the speedup of all run cases with respect to FP32, the baseline.
Try out the code sample on the Linux environment and on the Developer Clouds for Accelerated Computing using a 4th Gen Intel Xeon Scalable Processor.
Inference
This code sample will demonstrate how to perform inference using the ResNet50 and BERT models using Intel Extension for PyTorch. It features the performance improvement of Intel AMX BF16 and INT8 over FP32. There is also a comparison of Intel AMX INT8 with Intel AVX-512 Vector Neural Network Instructions (VNNI) INT8, the previous instruction set for INT8 operations.
The following steps are implemented in the code sample:
- Check if the hardware supports Intel AMX by checking the flags in cpuinfo.
- Instantiate the ResNet50 or BERT model.
- Set the environment variable ONEDNN_MAX_CPU_ISA:
- DEFAULT if running with Intel AMX
- AVX512_CORE_VNNI if running with Intel AVX512
- Perform inference on the model in the following run cases, using mixed precision when applicable. Record the inference time. For run cases with INT8, the original FP32 model is quantized using Intel Extension for PyTorch’s quantization feature. All models are then JIT-traced using TorchScript to take advantage of graph optimizations. This is useful when deploying models in production.
- FP32 (baseline)
- BF16 with Intel AMX
- INT8 with Intel AVX-512 VNNI INT8
- INT8 with Intel AMX
- Compare inference times and compute the speedup of all run cases with the FP32 baseline.
Try out the code sample on the Linux environment and on the Intel® DevCloud using a 4th Gen Intel Xeon Scalable Processor.
Watch
Watch the video to learn more about enhancing deep learning workloads on the latest Intel® Xeon processors.
What’s Next?
Get started with Intel Extension for PyTorch today and accelerate your PyTorch training and inference performance on 4th Gen Intel Xeon Scalable processors using Intel AMX.
We encourage you to also check out and incorporate Intel’s other AI/ML Framework optimizations and end-to-end portfolio of tools into your AI workflow and learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel’s AI Software Portfolio to help you prepare, build, deploy, and scale your AI solutions.
For more details about the new 4th Gen Intel Xeon Scalable processors, visit Intel's AI Solution Platform portal where you can learn how Intel is empowering developers to run end-to-end AI pipelines on these powerful CPUs.