Solution at a Glance
With QCT* DevCloud, Quanta Cloud Technology (QCT) enables developers to easily build compute-intensive high performance computing (HPC) applications in a cloud-based environment, allowing users to build, evaluate, and test workloads on the latest Intel® Xeon® Scalable processor platform.
The results:
- With the Intel® oneAPI Base Toolkit and Intel® HPC Toolkit, QCT DevCloud users can profile and optimize their code to its full potential on heterogeneous cross-architecture converged HPC and AI platforms.
- SYCL* provides highly efficient parallel implementations and on-par performance compared to CUDA* on NVIDIA* v100 Tensor Core GPUs for calculating solutions of the heat equation.
- Using Intel® VTune™ Profiler with QCT improved the SYCL enabled PolyBench-ACC benchmark performance by 38% compared to the OpenMP* baseline implementation
Increasing Workload Demand and Complexity
HPC workloads are essential for modeling complex phenomena. They are used for weather prediction, computational fluid dynamics, quantum chemistry, and molecular dynamics in scientific research. HPC workloads are revolutionizing how organizations optimize business operations, increase efficiency, and drive innovation to stay ahead of the competition. The compute power demand for HPC and AI has grown at an unprecedented rate over the past decade. With the rapidly increasing volume, throughput requirements, and variety of available data being processed, the challenge to process this data efficiently only increases. To meet the challenge of processing and analyzing vast amounts of data quickly and accurately, HPC workloads become increasingly complex. Traditional infrastructure and technologies struggle to support these workloads cost-effectively.
Ready to Meet the Challenge
QCT is well-positioned to meet the ever-increasing demand. As a cloud solution provider, QCT is looking for more efficient ways to integrate and maintain multiple software stacks for its developer-focused cloud solution. More software development kits, libraries, and utility integration offer a more flexible development environment, offering tools and solutions for even the most challenging software development projects. This flexibility does, however, also increase the complexity and maintenance cost. Intel® toolkits provide the means to achieve the desired level of flexibility and scale by offering hassle-free code conversion and optimization across different processor architectures and programming paradigms. Having a common, comprehensive, feature-rich set of development tools backed by the oneAPI initiative and its ecosystem helps QCT to enable more efficient ways to manage diverse developer solution requirements within QCT DevCloud.
oneAPI Provides the Solution
The Intel toolkits are based on the oneAPI initiative. oneAPI is an open, cross-architecture programming model that frees developers to use a single code base across multiple architectures. One key feature of oneAPI is that it provides compatibility tools for automatic code conversion and optimization across different processor architectures and programming paradigms. A CUDA-based program targeting GPU offload acceleration can be migrated to C++ with SYCL using the Intel® DPC++ Compatibility Tool or its open source initiative counterpart, SYCLomatic. The resulting codebase can then be compiled against a SPIR-V* specification-compliant device back-end runtime using the Intel® oneAPI DPC++/C++ Compiler. This way, code can run on third-party-vendor CPUs and GPUs. The Codeplay* oneAPI plug-in for NVIDIA GPUs is an example of this. Therefore, oneAPI not only eases the burden of programming but also delivers optimized codes without vendor lock-in.
QCT Platform On Demand for HPC Using Intel Toolkits
QCT DevCloud is an implementation of the QCT POD reference architecture, a cloud testbed for evaluating the performance of heterogeneous processor architectures. It is a cloud-based environment for developers offering a comprehensive infrastructure to develop and test their converged HPC and AI workload-driven applications. QCT DevCloud’s remotely accessible development cluster includes precompiled workloads and development toolkit support across a range of hardware platforms such as a server platform based on 3rd and 4th generation Intel Xeon Scalable processors with predeployed Intel oneAPI Base Toolkit and Intel HPC Toolkit.
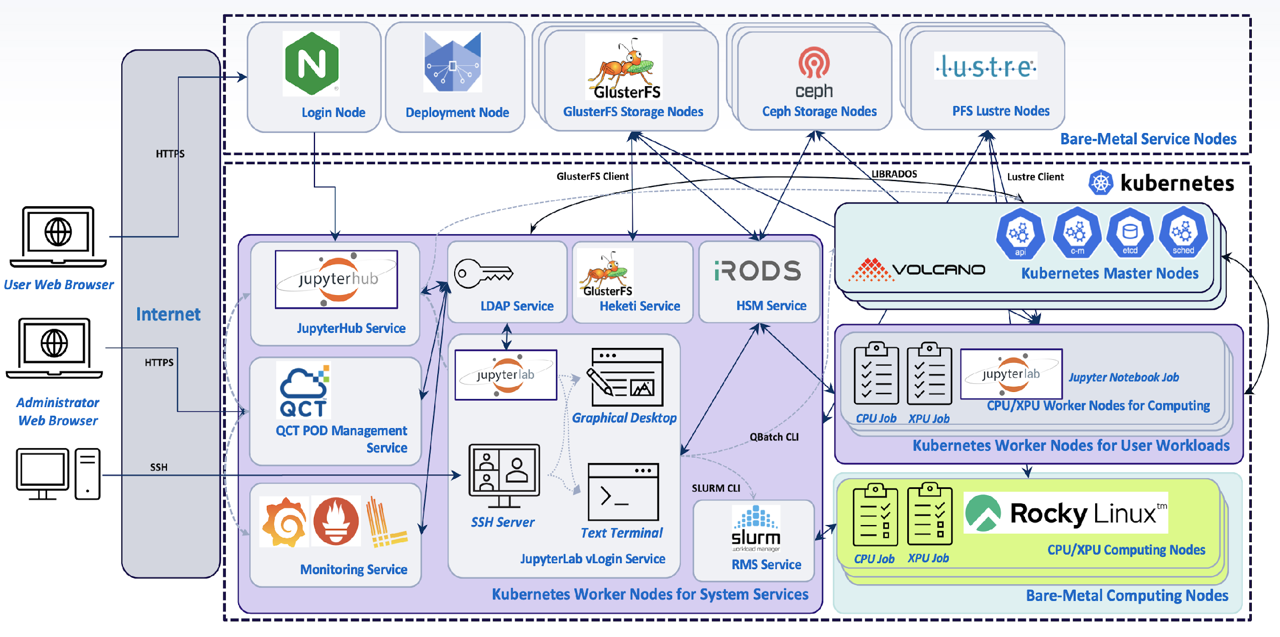
Figure 1. QCT DevCloud System Architecture
QCT DevCloud is a heterogeneous system supporting bare-metal development without containers, as well as Kubernetes*-based containerization environments. Users can access resources and services in the QCT DevCloud using a web browser over HTTPS to access JupyterHub Jupyter* Notebook services. Alternatively, SSH-based terminal access is also available for traditional X11 terminal-based HPC bare-metal environments. This helps end users develop their HPC as well as AI applications and run their workloads on both bare-metal compute nodes and Kubernetes worker nodes.
Performance Analysis Method
Applications Used for Performance Evaluation:
- Heat:
A heat conduction simulation, which mainly simulates the process of heat conduction in an object to a local equilibrium. The heat equation is a parabolic partial differential equation describing heat distribution in a given space over time. Since this process is quite regular, the simulation time can be accelerated through parallelization. - SYCL Benchmark Suite and PolyBench-ACC:
SYCL Bench is a benchmark suite that includes 39 numerical calculations commonly used in different fields, such as linear algebra, image processing, physical simulation, dynamic programming, and statistics. Of these numerical calculation workloads, we chose 15 that are available in both projects and, therefore, as both CUDA and SYCL implementations, so the benchmark data can be used to compare the performance of oneAPI-generated SYCL code and hand-written SYCL code.
For each of these, the performance experiment is then carried out using:
- The Intel DPC++ Compatibility Tool to migrate SYCL code based on the Polybench-ACC GitHub* project originally written using CUDA.
- Direct-programming SYCL version of the equivalent SYCL Benchmark Suite project.
In Figure 2, the problem size of each experiment is described by an integer number in brackets.
Results
In our tests, the initial performance of code ported from CUDA to SYCL using the Intel DPC++ Compatibility Tool is compared with handwritten SYCL code created and optimized by a software developer. The compatibility tool helps developers easily migrate their CUDA codes to SYCL and unlock their workload from just running on a specific proprietary hardware platform. As the results in Figure 2 show, auto-migrated SYCL codes can reach performance comparable to hand-tuned code for some test cases. The performance of the tool-migrated version of the fdtd-2d 2-D Finite Different Time Domain Kernel even exceeds the hand-optimized code performance out of the box. So, in a few scenarios, migrated SYCL code performance may even exceed the code an experienced developer might write.
One common reason why code auto-migrated from CUDA to SYCL commonly does not achieve the same performance as hand-tuned code is that a migration tool might choose the original block and grid size from the original CUDA implementation that is however, not the best workgroup size for running SYCL code on an Intel Xeon Scalable processor or an Intel® Data Center GPU Max Series. This type of optimization requires the developer to fine-tune the right workgroup size according to the workloads and intended target platform.
The direct SYCL programming version of the benchmark suite involved a developer’s knowledge about the use of prefetch buffer type memory. There are scenarios where the human touch and more intricate use case scenario knowledge cannot be substituted. That is why hand-tuned SYCL performs better than the migration tool-assisted code in most cases. Nevertheless, the results in Figure 2 show that the Intel DPC++ Compatibility Tool not only provides an easy way to migrate CUDA code to SYCL code at a good starting point but also can even exceed hand-tuned versions.
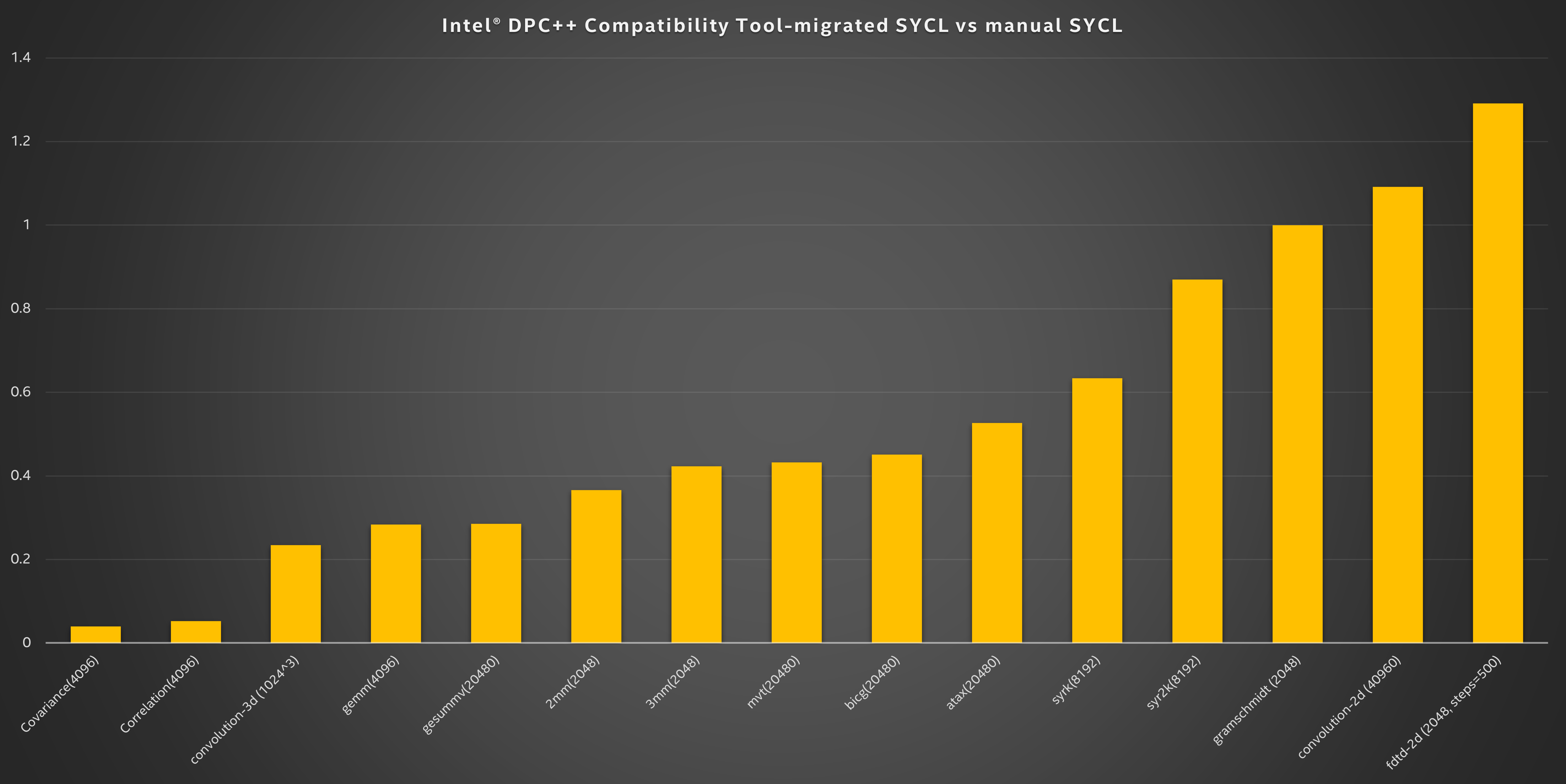
Figure 2. Performance comparison between auto-migrated SYCL and hand-tuned SYCL code on a 4th generation Intel Xeon Scalable processor.
Testing Date: Performance results are based on testing by Intel as of July 27, 2023, and may not reflect all publicly available updates.
Configuration Details and Workload Setup
Intel DPC++ Compatibility Tool migrated SYCL vs. manual SYCL:
- Test by Quanta Cloud Technology Inc. as of 7/27/2023. QuantaGrid D54X-1U Quanta Cloud Technology Inc. S6X-MB-RTT, 2S Intel Xeon Platinum 8460Y+ (512GB (16x32GB DDR5 4800 MT/s) , ucode: 0x2b000111, Rocky Linux* 9.0, Kernel: 5.14.0-70.13.1.el9_0.x86_64, BIOS 3A11, Intel oneAPI Base Toolkit 2023.1, DPCT, GCC* 11.3.1 20220421 (Red Hat* 11.3.1-2), CUDA 12.0
- Workloads: PolyBench-ACC
- Tool-migrated CUDA to SYCL workload: icpx -fsycl-targets=spir64_x86_64 -Xs "--device=cpu --march=avx512" -O3
- Hand-tuned SYCL workload: icpx -fsycl-targets=spir64_x86_64 -Xs "--device=cpu --march=avx512" -O3
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See configuration disclosure for details. No product or component can be absolutely secure. Performance varies by use, configuration, and other factors. Learn more at www.Intel.com/PerformanceIndex. Your costs and results may vary.
Optimization Using Intel® VTuneTM Profiler
The SYCL benchmark suite we previously mentioned also contains OpenMP implementations of the workloads we evaluated. If you are not ready to move your HPC or AI workload implementation to C++ with SYCL and parallelism backed by natural C++ extensions in the form of templates and generic lambdas functions, QCT DevCloud . You can continue developing your current workload using more traditional OpenMP parallel programming and offload models. The beauty of adopting the Intel oneAPI Base Toolkit within QCT DevCloud is, indeed, the flexibility and choice it offers the cloud-based developer.
The development tools package deployed as part of QCT POD and QCT DevCloud does not only provide build toolchains and libraries but also powerful code analysis tools like Intel® Advisor and Intel VTune Profiler. When moving from CUDA to SYCL or simply improving the performance of existing OpenMP code, Intel VTune Profiler can help achieve the desired performance level for your application. It can provide the insight needed to apply those extra hand-tuning steps to your codebase. With its help, developers can identify potential performance bottlenecks and realize their application's performance potential for their targeted hardware configuration.
Within QCT DevCloud, Intel VTune Profiler can be used to identify opportunities to improve application performance, system performance, and system configuration for HPC, cloud, IoT, media, storage, and more on Intel CPUs, GPUs, and FPGAs.
For the covariance matrix (4096) test case in our benchmark evaluation, we found that SYCL code performance initially exceeds the performance of the same workload that uses the OpenMP compiler directive programming model.
Let us use Intel VTune Profiler to capture a performance snapshot data of Covariance* shown in Figure 3 and to see how it can help us improve performance not only for SYCL code but also for code using OpenMP.
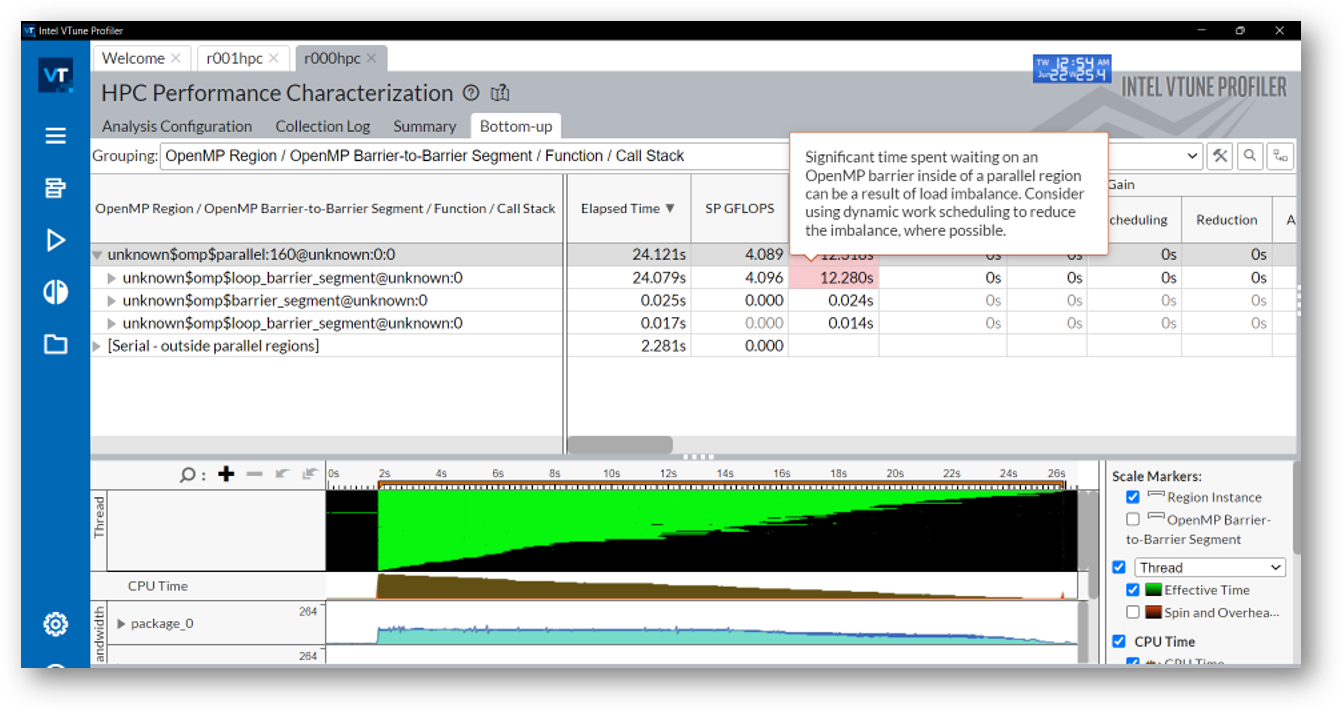
Figure 3. Collect performance snapshot analysis data of Covariance through Intel VTune Profiler.
The performance snapshot in Figure 3 not only reveals that there are three parallel regions, which map to three for-loops of the covariance matrix multiplication workload and a long wait on an OpenMP barrier caused by OpenMP load imbalance. It also provides guidance on the next steps that can be applied to reduce the load imbalance. It recommends that the OpenMP dynamic work scheduling directive could be used to resolve the performance issue. By reviewing the covariance source code in Figure 4, we can confirm that the parallel region of private (j2, i) contains chunks of imbalanced loads.

Figure 4. m*m Covariance matrix implementation using OpenMP
After applying the new directive #pragma omp for private (j2, i) with schedule(dynamic), the runtime of the covariance matrix improves by 28%. With the further tuning option OMP_PROC_BIND enabled, the overall performance will improve 37% by mapping the thread’s schedule task into the same physical core.
The Intel VTune Profiler included with the Intel toolkit provides the level of performance analysis and coding best-practices insight developers can leverage to get the best performance out of their QCT DevCloud hosted application:
omp for private (j2, i) schedule(dynamic):
Improve 28% performance, 17.15 seconds.
OMP_PROC_BIND=true + schedule (dynamic):
Improve 38% performance, 14.87 seconds.
Commitment to Open Standards and Freedom from Vendor-Lock
The performance data for SYCL in Figure 2 shows that it provides a highly efficient parallel implementation.
The commitment to open standards Intel demonstrates through the oneAPI initiative is, however not limited to SYCL. The move of the latest Intel oneAPI DPC++/C++ Compiler and the Intel® Fortran Compiler to embrace the open modular LLVM* compiler and toolchain framework also contributes to the freedom of choice of the oneAPI initiative. It gives developers options to use different backend runtimes for a variety of hardware as long as a oneAPI Level Zero or OpenCL™ platform compliant runtime library implementation exists. Furthermore, the Intel oneAPI DPC++/C++ Compiler comes out of the box with support for two programming models, SYCL and OpenMP, to maximize choice in parallel accelerated compute solutions. With the Codeplay NVIDIA and AMD* plug-ins, SYCL code can run on cross-vendor hardware, including non-Intel architectures.
Figure 5 shows SYCL code running the heat equation workload on NVIDIA V100 hardware using the Codeplay oneAPI for NVIDIA GPU plug-in. oneAPI and SYCL do not introduce any significant performance overhead. It achieves comparable performance to the built-in CUDA code. SYCL is a highly efficient programming model that can provide performance portability even on non-Intel hardware architectures.
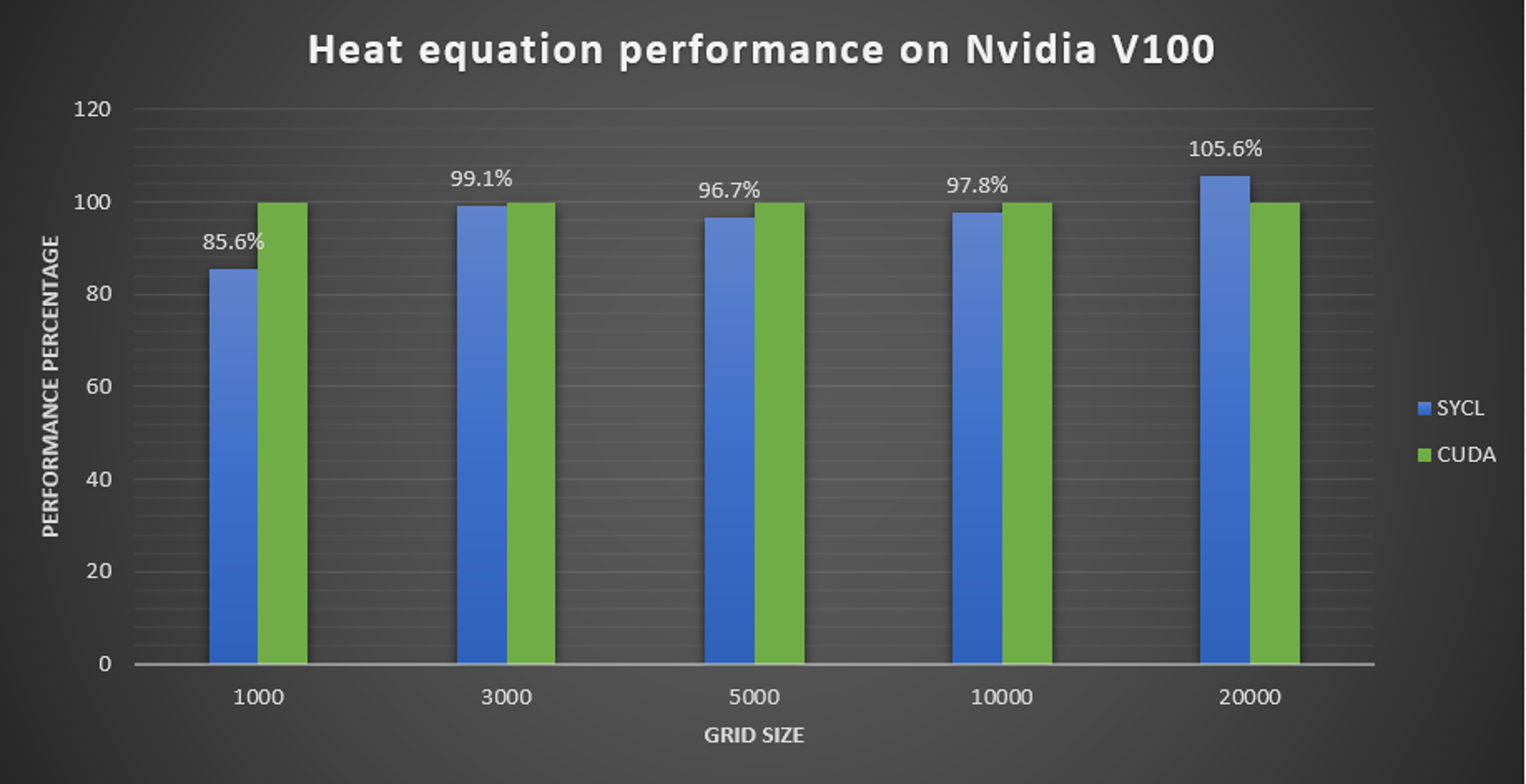
Figure 5. SYCL performance compared to CUDA running on the same NVIDIA hardware.
Testing Date: Performance results are based on testing by Intel as of July 27, 2023, and may not reflect all publicly available updates.
Configuration Details and Workload Setup
SYCL* Heat Equation Performance on NVIDIA V100
- Test by Quanta Cloud Technology Inc. as of 07/27/2023. QuantaGrid D52BV-2U Quanta Cloud Technology Inc. S5BV-MB (LBG-1G), 2S Intel Xeon Platinum 8280L processor (384 GB (12 x 32 GB DDR4 2933 MT/s)), ucode: 0x400320a, NVIDIA Tesla V100-PCIE-32GB, CUDA 12.2, Rocky Linux 9.0, Kernel: 5.14.0-70.13.1.el9_0.x86_64, BIOS 3B19.Q104, Intel oneAPI Base Toolkit 2023.1, oneAPI DPC++ Compiler for LLVM nvptx64-nvidia-cuda plug-in, GCC 11.3.1 20221121 (Red Hat 11.3.1-4)
- Workload: heat_sycl
- CUDA workload: nvidia/cuda/12.0, Nvcc Built on Mon_Oct_24_19:12:58_PDT_2022 CUDA compilation tools, release 12.0, V12.0.76 Build Cuda_12.0.r12.0/compiler.31968024_0, compiler command: nvcc -std=c++11 -O3 heat_cuda.cu -arch=sm_70 -o a.out
- SYCL workload: Intel oneAPI Base Toolkit 2023.1.0, icpx compiler 2023.1.0, compiler-rt/2023.1.0, compiler command: icpx -fsycl -fsycl-targets=nvptx64-nvidia-cuda -Xsycl-target-backend --cuda-gpu-arch=sm_70 -o a.out heat_sycl.cpp
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See configuration disclosure for details. No product or component can be absolutely secure. Performance varies by use, configuration, and other factors. Learn more at www.Intel.com/PerformanceIndex. Your costs and results may vary.
Conclusion
Through our study, we saw that oneAPI not only supports a cross-architecture programming model but also has the strength to explore hardware-specific optimization for improving application performance. Given the growing diversity of processor architectures, the increasing complexity of application behavior, and the ever-increasing number of diverse computational units on a CPU, it has become a difficult task for users to identify the best-suited workload distribution for optimum performance on processors and compute accelerators. A cross-architecture programming model, like oneAPI, will be crucial in overcoming this challenge.
The QCT DevCloud Program provides access to the latest QCT QuantaGrid family of servers powered by Intel Xeon Scalable processors that deliver the performance and memory capacity for even the most compute-intensive workloads. Several key Intel technologies are supported on these server platforms, such as Intel® Software Guard Extensions (Intel® SGX) and Intel® Advanced Matrix Extensions (Intel® AMX), which enhance the security level and accelerate the development of HPC, AI, and data analytics workloads. Besides, Intel oneAPI offers a powerful set of development tools and utilities, increasing productivity for the development journey in a heterogeneous infrastructure.
Resources
Here are some additional useful resources for you to get started with using oneAPI on the QCT DevCloud:
- QCT Platform on Demand
- QCT DevCloud Program
- oneAPI Specification
- Intel oneAPI
- Intel Toolkits
- Intel oneAPI Base Toolkit
- Intel HPC Toolkit
- oneAPI Code Samples
Notices and Disclaimers
Intel technologies may require enabled hardware, software, or service activation.
Your costs and results may vary.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.