Intel® High Level Synthesis Compiler Pro Edition: Best Practices Guide
ID
683152
Date
6/20/2022
Public
A newer version of this document is available. Customers should click here to go to the newest version.
1. Intel® HLS Compiler Pro Edition Best Practices Guide
2. Best Practices for Coding and Compiling Your Component
3. FPGA Concepts
4. Interface Best Practices
5. Loop Best Practices
6. fMAX Bottleneck Best Practices
7. Memory Architecture Best Practices
8. System of Tasks Best Practices
9. Datatype Best Practices
10. Advanced Troubleshooting
A. Intel® HLS Compiler Pro Edition Best Practices Guide Archives
B. Document Revision History for Intel® HLS Compiler Pro Edition Best Practices Guide
5.1. Reuse Hardware By Calling It In a Loop
5.2. Parallelize Loops
5.3. Construct Well-Formed Loops
5.4. Minimize Loop-Carried Dependencies
5.5. Avoid Complex Loop-Exit Conditions
5.6. Convert Nested Loops into a Single Loop
5.7. Place if-Statements in the Lowest Possible Scope in a Loop Nest
5.8. Declare Variables in the Deepest Scope Possible
5.9. Raise Loop II to Increase fMAX
5.10. Control Loop Interleaving
5.2.2. Unroll Loops
When a loop is unrolled, each iteration of the loop is replicated in hardware and executes simultaneously if the iterations are independent. Unrolling loops trades an increase in FPGA area use for a reduction in the latency of your component.
Consider the following basic loop with three stages and three iterations. Each stage represents the operations that occur in the loop within one clock cycle.
Figure 31. Basic loop with three stages and three iterations

If each stage of this loop takes one clock cycle to execute, then this loop has a latency of nine cycles.
The following figure shows the loop from Basic loop with three stages and three iterations unrolled three times.
Figure 32. Unrolled loop with three stages and three iterations
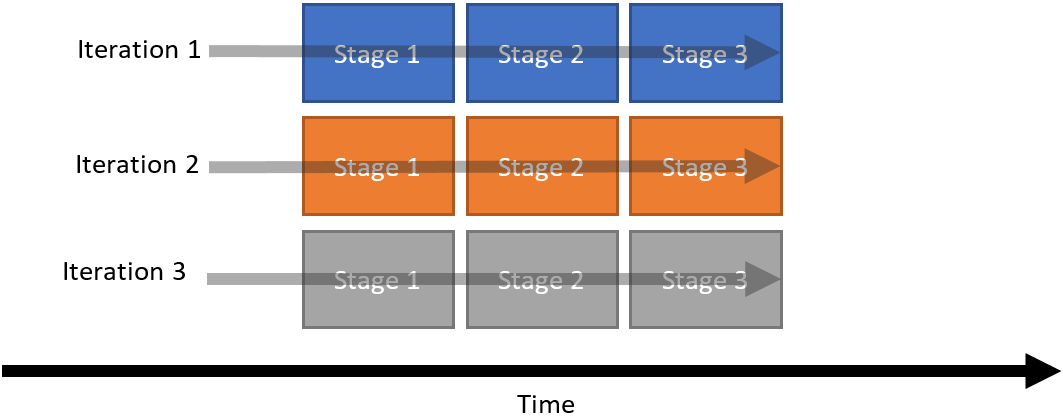
Three iterations of the loop can now be completed in only three clock cycles, but three times as many hardware resources are required.
You can control how the compiler unrolls a loop with the #pragma unroll directive, but this directive works only if the compiler knows the trip count for the loop in advance or if you specify the unroll factor. In addition to replicating the hardware, the compiler also reschedules the circuit such that each operation runs as soon as the inputs for the operation are ready.
For an example of using the #pragma unroll directive, see the best_practices/resource_sharing_filter tutorial.