1.3. Performance
- GPUs
-
- NVIDIA* Tesla* C2075 companion processor (C2075)
- NVIDIA* GeForce* GTX 760 graphics card (GTX760)
- NVIDIA* GeForce* GTX 960 graphics card (GTX960)
- CPUs
-
- Intel® Xeon® Processor E5-1650 V3 (E5-1650 V3)
- Intel® Core® i7-4960X Processor Extreme Edition (i7-4960X)
Thirty kernels were chained together in a feed-forward approach in order to perform 30 iterations of the stencil algorithm in parallel. Each individual kernel began execution as soon as it was sent enough information from the previous kernel.
| Processor | Execution Time (s) |
|---|---|
| A10GX1150 | 42.455 |
| C2075 | 232.4 |
| GTX760 | 176.5 |
| GTX960 | 111.7 |
| E5-1650 V3 | 258.9 |
| i7-4960X | 260.2 |
- Compiling with a newer version of Intel® Quartus® Prime Design Suite
- Fitting more calculation kernels in the chain
- Using an FPGA device that is larger, faster, or both
- Removing profiling hardware
| No. of Kernels | Data set 4088x65536 | Data set 4088x32760 | Data set 4088x4088 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Exec. Time (ms) | GFLOPS | Stall % (Worst) | Exec. Time (ms) | GFLOPS | Stall % (Worst) | Exec. Time (ms) | GFLOPS | Stall % (Worst) | |
| 1 | 151.34 | 7.081040518 | 29.9 | 75.75 | 7.0718352 | 29.25 | 9.71 | 6.8843 | 34.41 |
| 2 | 148.89 | 14.39511951 | 34.74 | 74.56 | 14.369408 | 34.67 | 9.62 | 13.898 | 38.03 |
| 3 | 150.16 | 21.41005605 | 32.45 | 75.1 | 21.399129 | 32.44 | 9.2 | 21.798 | 30.05 |
| 10 | 150.33 | 71.28614861 | 35.03 | 75.23 | 71.207167 | 34.99 | 9.51 | 70.291 | 35.23 |
| 20 | 164.24 | 130.4974028 | 19.78 | 82.12 | 130.46554 | 20.09 | 10.38 | 128.8 | 33.22 |
| 28 | 165.77 | 181.0101394 | 15.41 | 82.88 | 180.97686 | 15.13 | 10.45 | 179.11 | 22.77 |
| 29 | 162.62 | 191.1062322 | 22.53 | 81.4 | 190.84833 | 22.78 | 10.42 | 186.04 | 15.94 |
| 30 | 165.8 | 193.9043435 | 17.46 | 82.92 | 193.81025 | 17.35 | 10.43 | 192.27 | 12.03 |
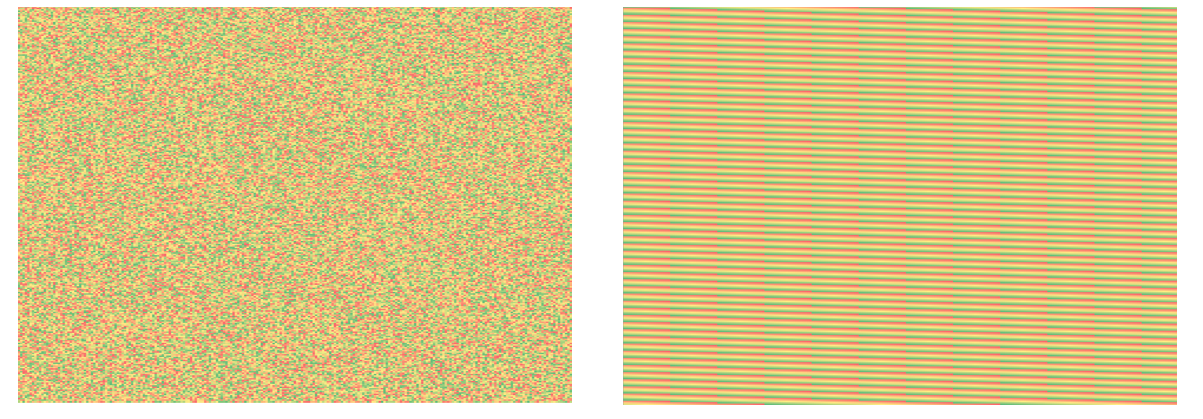
The following heat maps show the convergence of values after running the kernel. The first pair of images represents the unprocessed raw input. The heat maps illustrate 280x280 grids, where the values in the left maps were initially created with a pseudorandom function, and the values in the right maps were created by looping from 1 to 100.
To calculate the execution time for a system requiring more than 30 iterations, divide the desired number of iterations by 30 multiplied by the time it takes 30 iterations to run () For example, 300 iterations applied to a 4088x65536 data set should take around 1658 ms to run.
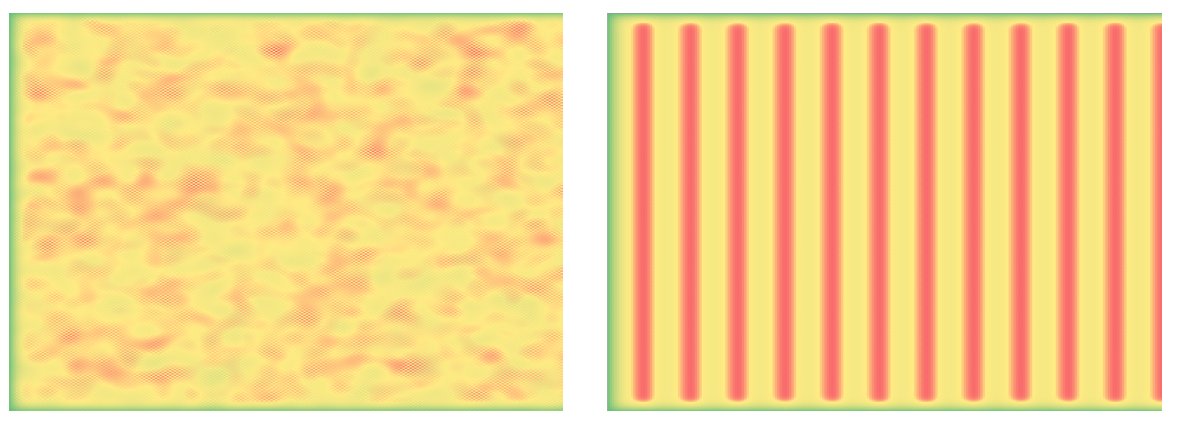
The following heat map shows the result of running the initial values through a kernel with 30 chained calculation CUs. You can see the beginnings of convergence emerge.
doi: 10.1109/TPDS.2016.2614981
URL: http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7582502&isnumber=7894348