Thread Mapping and GPU Occupancy
This section will explain how kernel execution will map to the Intel GPU hardware building blocks (Xe-Core, Vector Engine, Vector Engine threads) and explains how to setup the kernel parameters to efficiently utilize all the hardware resources to achieve highest occupancy.
GPU Execution Model and Mapping
The SYCL execution model exposes an abstract view of GPU execution. The SYCL thread hierarchy consists of a 1-, 2-, or 3-dimensional grid of work-items. A collection of work-items forms a sub-group, and a collection of sub-groups forms a work-group (see the following illustration).
Each work-item is mapped to SIMD lane.
Sub-group is mapped to Vector Engine hardware thread.
Work-group is executed in a Xe-Core.
Work-item
A work-item represents one of a collection of parallel executions of a kernel.
Sub-group
A sub-group represents a short range of consecutive work-items that are processed together as a SIMD vector of length 16 or 32.
Work-group
A work-group is a 1-, 2-, or 3-dimensional representation of a collection of related work-items that are executed on a single Xe-Core. In SYCL, synchronization across work-items is only possible with barriers for the work-items within the same work-group.
nd_range
An nd_range divides the thread hierarchy into 1-, 2-, or 3-dimensional grids of work-groups. It is represented by the global range, the local range of each work-group.
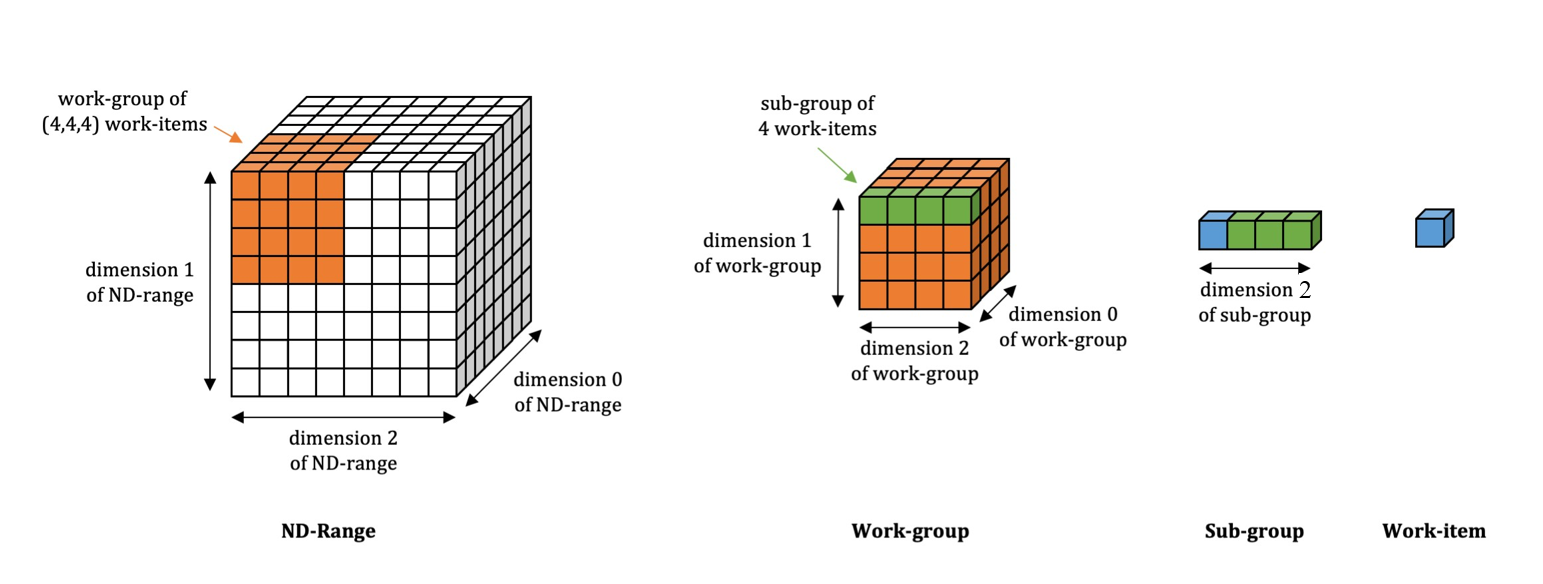
The diagram above illustrates the relationship among ND-Range, work-group, sub-group, and work-item.
Kernel Execution Mapping to GPU
The work load is divided into equal sized work-groups.
A work-group can be dispatched to idle Vector Engines if there are sufficient hardware resources available.
A work-group executes on one or more Vector Engine threads within a single Xe-Core.
Multiple work-groups can execute simultaneously on the same Xe-Core if there are sufficient Vector Engine hardware resources and Shared Local Memory (SLM) resources available.
A GPU has multiple Xe-Cores that can execute multiple work-groups simultaneously.

Terminology
As described above, the workload offloaded onto the GPU is divided into work-groups, sub-groups, and work-items. The ND-range represents the total execution range, which is divided into work-groups of equal size. A work-group is a 1-, 2-, or 3-dimensional set of work-items. Each work-group can be divided into sub-groups. A sub-group represents a short range of consecutive work-items that are processed together as a SIMD vector.
The following table shows how SYCL concepts map to OpenMP and CUDA concepts.
SYCL |
OpenMP |
CUDA |
|---|---|---|
Work-item |
OpenMP thread or SIMD lane |
CUDA thread |
Work-group |
Team |
Thread block |
Work-group size |
Team size |
Thread block size |
Number of work-groups |
Number of teams |
Number of thread blocks |
Sub-group (size = 8, 16, 32) |
SIMD chunk (size = 8, 16, 32) |
Warp (size = 32) |
Maximum number of work-items per work-group |
Thread limit |
Maximum number of CUDA threads per thread block |
GPU Occupancy
To obtain optimal performance, you need to make sure that all Vector Engine hardware threads available in the GPU are efficiently utilized.
Xe-Core Occupancy is the ratio of number of hardware threads utilized in the Xe-Core to the total hardware threads available in the Xe-Core.
The GPU Occupancy is the ratio of number of hardware threads utilized in the GPU to the total hardware threads available in the GPU.
The Xe-Core Occupancy and GPU Occupancy can change from time to time during the kernel execution.
The two most important GPU resources that limit the Xe-Core and GPU Occupancy are:
Number of Vector Engine threads: The kernel should be designed so that work-groups dispatched to the Xe-Core can utilize all the Xe-Core’s hardware threads.
Note that using a large register file will bring down the Xe-Core Occupancy by 50%. Learn more about Small Register Mode vs. Large Register Mode
Size of Shared Local Memory (SLM): The kernel should be designed so that all work-groups executing in the Xe-Core can efficiently share the SLM.
Mapping Work-Groups to Xe-Cores for Maximum Occupancy
This section explains how to pick a proper work-group size to maximize the occupancy of the GPU resources.
The following table shows the latest Intel® Xe GPU families. The Xe-HPC (Intel® Data Center GPU MAX 1550) GPU is used as an example to analyze how the kernel maps work-group executions to Xe-Core and to understand GPU Occupancy.
Architecture |
Xe2-HPG |
Xe2-LPG |
Xe-LPG |
Xe-HPC |
Xe-HP |
Xe-HPG |
Xe-LP |
|---|---|---|---|---|---|---|---|
GPU Name |
Intel® ArcTM B580 |
Intel® CoreTM Ultra 7 Processor 265 |
Intel® CoreTM Ultra 7 Processor 155H |
Intel® Data Center GPU MAX 1550 |
Intel® Data Center GPU Flex 170 |
Intel® ArcTM A770 Graphics |
Intel® Iris® Xe Graphics |
Xe-Core count |
20 |
8 |
8 |
64 x 2 |
32 |
32 |
6 |
Vector Engines per Xe-Core |
8 |
8 |
16 |
8 |
16 |
16 |
16 |
Hardware Threads per Vector Engine |
8 |
8 |
8 |
8 |
8 |
8 |
7 |
Hardware Threads per Xe-Core |
64 |
64 |
128 |
64 |
128 |
128 |
112 |
SLM size per Xe-Core |
128 KB |
128 KB |
128 KB |
128 KB |
128 KB |
128 KB |
128 KB |
Max SLM size per Work-Group |
128 KB |
128 KB |
64 KB |
128 KB |
64 KB |
64 KB |
64 KB |
Max Work-Group Size |
1024 |
1024 |
1024 |
1024 |
1024 |
1024 |
512 |
Supported SIMD Sizes |
16, 32 |
16, 32 |
8, 16, 32 |
16, 32 |
8, 16, 32 |
8, 16, 32 |
8, 16, 32 |
In a SYCL kernel, you can affect the work distribution by structuring the kernel with proper work-group size, sub-group size, and organizing the work-items for efficient vector execution. Writing efficient vector kernels is covered in a separate section. This section focuses on work-group and sub-group size selection.
Start with selecting the number of hardware threads required to execute a work-group. Each Xe-Core has 64 hardware threads, you can use work-group size and sub-group size to get the number of hardware threads required to execute the work-group:
Number of Hardware Threads required to execute a work-group = Work-group size / Sub-group size
Number of Hardware Threads required to execute the kernel = Number of Hardware Threads required to execute a work-group x Number of Work-groups
In general, choosing a larger work-group size has the advantage of reducing the number of rounds of work-group dispatching. Increasing sub-group size can reduce the number of hardware threads required for a work-group, possibly at the expense of higher register pressure for each sub-group execution.
Xe-Core Utilization per Work-group can be computed by using the following formula:
Xe-Core Utilization = (Work-group size / Sub-group size) / (Maximum available hardware thread per Xe-Core)
For Intel® Data Center GPU MAX 1550, the maximum available hardware threads per Xe-Core = 64 (8 Vector Engines x 8 hardware threads). For example, if you use work-group size = 1024 and sub-group size = 32:
Xe-Core Utilization = (Work-group size / Sub-group size) / 64
Xe-Core Utilization = (1024 / 32) / 64 = 0.5
One work-group execution, Xe-Core Occupancy = 50%
If 2 work-groups are dispatched, Xe-Core Occupancy = 100%
Work-group size of 1024 and Sub-group size of 32 will result is 100% Xe-Core utilization.
Impact of Work-group size on Xe-Core Occupancy
The following example shows a simple basic kernel:
This kernel contains 983040 work-items structured as a 3D range of (64, 120, 128). It leaves the work-group and sub-group size selection to the compiler.
q.parallel_for(
sycl::range(64, 120, 128) // global range
), [=](sycl::nd_item<3> item) {
// (kernel code)
});The next example shows a ND-range kernel, with work-group size and SIMD sub-group size explicitly specified:
This kernel contains 983040 work-items structured as a 3D range of (64, 120, 128). You can specify the work-group size using the sycl::nd_range function, and the sub-group size is selected using [[sycl::reqd_sub_group_size(32)]]. The local range or work-group size used in this example is (1, 1, 128) and the sub-group size used is 32.
q.parallel_for(sycl::nd_range(
sycl::range(64, 120, 128), // global range
sycl::range(1, 1, 128) // work-group size
), [=](sycl::nd_item<3> item) [[sycl::reqd_sub_group_size(32)]] { // sub-group size
// (kernel code)
});The maximum work-group size is a constraint imposed by the hardware and GPU driver. You can query the maximum work-group size by using the device.get_info<sycl::info::device::max_work_group_size>() function.
The supported sub-group size is a constraint imposed by the hardware and GPU driver. You can query the supported sub-group size by using the device.get_device().get_info<sycl::info::device::sub_group_sizes>() function.
All the work-items of a work-group must be allocated to the same Xe-Core, which affects Xe-Core occupancy and kernel performance.
In the kernel, the local range of a work-group is given as range(1, 1, 128) and the sub-group size is explicitly set to 32. The following examples show how the Xe-Core occupancy is affected by varying work-group size (1, R, 128), where the R value is changed from 1~10.
In the case of R=1, the local group range is (1, 1, 128) and work-group size is 128. The Xe-Core allocated for a work-group contains only 4 threads out of 64 available hardware threads (i.e., very low occupancy). However, the system can dispatch 16 work-groups to the same Xe-Core to reach full occupancy.
In the case of R>8, the work-group size will exceed the system-supported maximum work-group size of 1024, and the kernel will fail to launch.
In the case of R=3, the local group range is (1, 3, 128) and work-group size is 384. The Xe-Core allocated for a work-group contains 12 threads out of 64 available hardware threads. However, the system can dispatch 5 work-groups to the same Xe-Core to reach maximum occupancy of 93.75%.
In the case of R=7, the local group range is (1, 7, 128). This is an invalid work-group size since the second dimension of global size (64, 120, 128) which is 120 does not divide equally by 7. The kernel will fail to launch with exception.
In the case of R=8, the local group range is (1, 8, 128) and work-group size is 1024. The Xe-Core allocated for a work-group contains 32 threads out of 64 available hardware threads. However, the system can dispatch 2 work-groups to the same Xe-Core to reach full occupancy. This is the best occupancy with the least number of dispatches.
The following table summarizes the tradeoffs between group size, number of threads, Xe-Core utilization, and occupancy.
Utilization for various configurations
Work-items |
Work-Group Size |
Threads = Work-group / Sub-group |
Xe-Core Utilization |
Xe-Core Occupancy |
|---|---|---|---|---|
(64, 120,128) |
(1, 1, 128) = 128 |
4 |
4 / 64 = 6.25% |
100% with 16 work-groups |
(64, 120,128) |
(1, 2, 128) = 256 |
8 |
8 / 64 = 12.5% |
100% with 8 work-groups |
(64, 120,128) |
(1, 3, 128) = 384 |
12 |
12 / 64 = 18.75% |
93.75% with 5 work-groups |
(64, 120,128) |
(1, 4, 128) = 512 |
16 |
16 / 64 = 25% |
100% with 4 work-groups |
(64, 120,128) |
(1, 5, 128) = 640 |
20 |
20 / 64 = 31.25% |
93.75% with 3 work-groups |
(64, 120,128) |
(1, 6, 128) = 768 |
24 |
24 / 64 = 37.5% |
75% with 2 work-groups |
(64, 120,128) |
(1, 7, 128) = 896 |
28 |
Kernel fails to launch (Invalid: Non-uniform work-groups) |
N/A |
(64, 120,128) |
(1, 8, 128) = 1024 |
32 |
32 / 64 = 50% |
100% with 2 work-groups |
(64, 120,128) |
(1, 9, 128) = 1152 |
36 |
Kernel fails to launch (> maximum allowed work-group size) |
N/A |
Impact of Shared Local Memory Usage on Xe-Core Occupancy
The following example shows how a kernel allocates Shared Local Memory (SLM) for a work-group:
This kernel contains 983040 work-items structured as a 3D range of (64, 120, 128). You can specify the work-group size using the sycl::nd_range function and the sub-group size is selected using [[sycl::reqd_sub_group_size(32)]]. The local range or work-group size used in this example is (1, 1, 128) and the sub-group size used is 32. The value of M in the code determines the local memory allocation.
q.submit([&](sycl::handler &h){
sycl::local_accessor<float, 1> local_mem(sycl::range<1>(M), h); // SLM allocation
h.parallel_for(sycl::nd_range(
sycl::range(64, 120, 128), // global range
sycl::range(1, 8, 128) // work-group size
), [=](sycl::nd_item<3> item) [[sycl::reqd_sub_group_size(32)]] { //sub-group size
// (kernel code)
local_mem[item.get_local_linear_id()] = 1;
// (kernel code)
});
});The maximum SLM size per work-group is a constraint imposed by the hardware and GPU driver. You can query the maximum SLM size by using the device.get_info<sycl::info::device::max_local_mem_size>() function.
Since float uses 4 Bytes, SLM used per work-group in the code above = M x 4 Bytes
In the case of M=0, the SLM used per work-group is 0KB, and the Xe-Core allocated for a work-group contains 32 threads out of 64 available hardware threads. However, the system can dispatch two work-groups to the same Xe-Core to reach 100% occupancy.
In the case of M=16384, the SLM used per work-group is 64KB, and the Xe-Core allocated for a work-group contains 32 threads out of 64 available hardware threads. However, the system can dispatch two work-groups to the same Xe-Core. Since there is 128KB of SLM available, the two work-groups will use 64KB + 64KB SLM to reach 100% occupancy.
In the case of M=16640, the SLM used per work-group is 65KB,and the Xe-Core allocated for a work-group contains 32 threads out of 64 available hardware threads. However, the system can only dispatch one work-group to the same Xe-Core. Since there is 128KB of SLM available, not enough SLM is left for another work-group to be dispatched, resulting in 50% occupancy.
In the case of M=32768, the SLM used per work-group is 128KB, and the Xe-Core allocated for a work-group contains 32 threads out of 64 available hardware threads. However, the system can only dispatch one work-group to the same Xe-Core since there is 128KB SLM available, and no SLM will be left if one work-group is dispatched, resulting in 50% occupancy. This may not always mean performance will be worse than in cases where 100% occupancy is achieved by using less SLM per work-group. It is possible to get better performance with <100% occupancy with more SLM usage versus 100% occupancy with less SLM usage per work-group.
In the case of M=33792, the SLM used per work-group is 132KB. The kernel launch will fail since it is trying allocate more than the available 128KB of SLM.
Work-group local variables are allocated in a Xe-Core’s SLM because they are shared among its work-items. Therefore, this work-group must be allocated to a single Xe-Core, same as the intra-group synchronization. In addition, you must also weigh the sizes of local variables under different group size options such that the local variables fit within an Xe-Core’s 128KB SLM capacity limit.
The following table summarizes the tradeoffs between SLM usages, Xe-Core utilization, and occupancy.
Utilization for various configurations:
SLM Used per Work-group M x 4 (float uses 4 Bytes) |
SLM allocated in kernel |
Xe-Core Utilization per WG = (WG/SG) / threads per Xe-Core = (1024/32) / 64 |
Xe-Core Occupancy |
SLM Used in Xe-Core |
|---|---|---|---|---|
M=0, 0Bytes |
0 KB |
50% |
100% with 2 work-groups |
0 KB |
M=8192,(8192 x 4)Bytes |
32 KB |
50% |
100% with 2 work-groups |
64 KB with 2 work-groups |
M=16384,(16384 x 4)Bytes |
64 KB |
50% |
100% with 2 work-groups |
128 KB with 2 work-groups |
M=16640,(16640 x 4)bytes |
65 KB |
50% |
50% with 1 work-group |
*96 KB with 1 work-group |
M= 32768,(32768 x 4)Bytes |
128 KB |
50% |
50% with 1 work-group |
128 KB with 1 work-group |
M=33792,(33792 x 4)Bytes |
132 KB |
Kernel Fails to launch (> Maximum available SLM, ERROR_OUT_OF_RESOURCES) |
NA |
NA |
Allocated SLM Size
For efficient memory management, the GPU may allocate more memory than what is requested by kernel code depending on the size of the SLM allocation requested by kernel code. This memory fragmentation or overhead must be taken into account when calculating the Xe-Core occupancy and the number of work-groups that can be dispatched.
For example, the |intel_r| Data Center GPU MAX 1550 has 128KB SLM, the allocation may be rounded off to these numbers: [2, 4, 8, 16, 24, 32, 48, 64, 96,128].
This is why in the table above, when the kernel requests 65KB of SLM, it actually allocates 96KB of SLM.
Execution Mapping and Occupancy Example
Execution mapping for Intel® Data Center GPU MAX 1550:
Each Vector Engine has 8 hardware threads
Each Xe-Core has 8 Vector Engines = 8 x 8 = 64 hardware threads
The GPU has 128 Xe-Cores = 128 x 64 = 8192 hardware threads
Kernel work-load execution example:
The following example shows kernel work-load execution, where work-group size = 1024, sub-group size = 32 and SLM allocation = 64 KB.
If kernel workload is (64, 120, 128) and work-group size is (1, 8, 128), then there will be total of 960 work-groups that the kernel will execute. (64x120x128) / (8x128) = 960
Number of hardware threads used to execute each work-group = 1024/32 = 32
Number of work-groups that can execute simultaneously on one Xe-Core = 64/32 = 2, also considering the amount of SLM required (2 x 64KB) does not exceed the maximum available SLM of 128KB, resulting in 100% Xe-Core Occupancy
Number of work-groups that can execute simultaneously on GPU = 2 x 128 Xe-Cores = 256
There are 960 total work-groups, which will execute in 960/256 = 3.75 GPU waves
Three GPU waves with 100% GPU occupancy and one GPU wave with 75% GPU occupancy
Intel® GPU Occupancy Calculation
In summary, a SYCL work-group is typically dispatched to an Xe-Core. All the work-items in a work-group share the same SLM of an Xe-Core for intra work-group thread barriers and memory fence synchronization. Multiple work-groups can be dispatched to the same Xe-Core if there are sufficient Vector Engines, SLM, and hardware threads to accommodate them.
Factors affecting the GPU Occupancy
You can achieve higher performance by fully utilizing all available Xe-Cores. The parameters affecting a kernel’s GPU occupancy are work-group size, sub-group size and Shared Local Memory usage.
Work-group size: Choosing higher work-group size will result in fewer number of kernels dispatched to complete workload execution, which is ideal. A smaller work-group size will result in a greater number of work-groups and higher number of kernel dispatches which will result in added dispatch overhead.
Sub-group size: Increasing sub-group size can reduce the number of hardware threads required for a work-group, however larger sub-group size may require more registers resulting in higher register pressure for each thread.
Shared Local Memory size: Since all work-groups executing in a Xe-Core use the same SLM resource, higher SLM allocation in the kernel may not leave enough SLM for other work-groups to be dispatched concurrently, resulting in lower occupancy.
Note that higher occupancy does not always translate to higher performance.
The general recommendation is to start by choosing the highest possible work-group size since this will result in a smaller number of work-groups and a smaller number of dispatches required to complete the work-load. Intel GPUs usually support 2 or 3 sub-group sizes (8, 16, 32), it is recommended to test for performance by varying supported sub-group sizes since this affects the register pressure and may affect the performance. Finally, the SLM size allocation should also be varied and tested for performance, higher SLM allocation may result in a smaller number of concurrent work-group execution in a Xe-Core, resulting in lower occupancy.
Having 100% occupancy may be the right strategy for compute bound kernels, but for memory bound kernels you can use larger SLM at the cost of occupancy to improve the performance.
Intel® GPU Occupancy Calculator Tool
The Intel® GPU Occupancy Calculator can be used to calculate the theoretical occupancy on an Intel® GPU for a given kernel, and its work-group parameters.
The Intel® GPU Occupancy tool will compute the theoretical GPU Occupancy for Intel GPU devices based on GPU Kernel code parameters. The Occupancy value will determine whether the GPU is efficiently utilizing all the GPU hardware resources. The tool will also generate graphs that will help optimize GPU Occupancy.
The tool will allow you to pick an Intel GPU and will allow you to input the work load size, work-group size, sub-group size and SLM size used in the kernel. The tool will use these parameters to automatically calculate the following:
Xe-Core Occupancy value
Number of work-groups dispatched to each Xe-Core
Peak GPU Occupancy
Average GPU Occupancy
Number of GPU waves
Graph for Xe-Core Occupancy impact of varying work-group size
Graph for Xe-Core Occupancy impact of varying SLM size
The GPU Occupancy Calculator gives a theoretical estimate of GPU Occupancy, actual occupancy on the hardware may be slightly different due to many factors like kernel scheduling variations, cache hit/miss and other hardware conditions.
Actual GPU Occupancy can be measured using the profiling tools like Intel® VTune Profiler Profiler and unitrace