Registerization and Avoiding Register Spills
Registers and Performance
Register is the fastest storage in the memory hierarchy. Keeping data in registers as long as possible is critical to performance. However, register space is limited and much smaller than memory space. The current generation of Intel® GPUs, for example, has 128 general-purpose registers, each 32 bytes wide by default for each XVE thread. Though the compiler aims to assign as many variables to registers as possible, the limited number of registers can be allocated only to a small set of variables at any point during execution. A given register can hold different variables at different times because different sets of variables are needed at different times. If there are not enough registers to hold all the variables, register can spill, or some variables currently in the registers can be moved to memory to make room for other variables.
In SYCL, the compiler allocates registers to private variables in work items. Multiple work items in a sub-group are packed into one XVE thread. By default, the compiler uses register pressure as one of the heuristics to choose SIMD width or sub-group size. High register pressures can result in smaller sub-group size (for example 8 instead of 16) if a sub-group size is not explicitly requested. It can also cause register spilling or cause certain variables not to be promoted to registers.
The hardware may not be fully utilized if sub-group size or SIMD width is not the maximum the hardware supports. Register spilling can cause significant performance degradation, especially when spills occur inside hot loops. When variables are not promoted to registers, accesses to these variables incur significant increase of memory traffic.
Though the compiler uses intelligent algorithms to allocate variables in registers and to minimize register spills, optimizations by developers can help the compiler to do a better job and often make a big performance difference.
Optimization Techniques
The following techniques can reduce register pressure:
Keep live ranges of private variables as short as possible.
Though the compiler schedules instructions and optimizes the distances, in some cases moving the loading and using the same variable closer or removing certain dependencies in the source can help the compiler do a better job.
Avoid excessive loop unrolling.
Loop unrolling exposes opportunities for instruction scheduling optimization by the compiler and thus can improve performance. However, temporary variables introduced by unrolling may increase pressure on register allocation and cause register spilling. It is always a good idea to compare the performance with and without loop unrolling and different times of unrolls to decide if a loop should be unrolled or how many times to unroll it.
Prefer USM pointers.
A buffer accessor takes more space than a USM pointer. If you can choose between USM pointers and buffer accessors, choose USM pointers.
Recompute cheap-to-compute values on-demand that otherwise would be held in registers for a long time.
Avoid big arrays or large structures, or break an array of big structures into multiple arrays of small structures.
For example, an array of sycl::float4:
sycl::float4 v[8];
can be broken into 4 arrays of float:
float x[8]; float y[8]; float z[8]; float w[8];
All or part of the 4 arrays of float have a better chance to be allocated in registers than the array of sycl::float4.
Break a large loop into multiple small loops to reduce the number of simultaneously live variables.
Choose smaller sized data types if possible.
Do not declare private variables as volatile.
Share registers in a sub-group.
Use sub-group block load/store if possible.
Use shared local memory.
The list here is not exhaustive.
The rest of this chapter shows how to apply these techniques, especially the last five, in real examples.
Choosing Smaller Data Types
constexpr int BLOCK_SIZE = 256;
constexpr int NUM_BINS = 32;
std::vector<unsigned long> hist(NUM_BINS, 0);
sycl::buffer<unsigned long, 1> mbuf(input.data(), N);
sycl::buffer<unsigned long, 1> hbuf(hist.data(), NUM_BINS);
auto e = q.submit([&](auto &h) {
sycl::accessor macc(mbuf, h, sycl::read_only);
auto hacc = hbuf.get_access<sycl::access::mode::atomic>(h);
h.parallel_for(
sycl::nd_range(sycl::range{N / BLOCK_SIZE}, sycl::range{64}),
[=](sycl::nd_item<1> it) [[intel::reqd_sub_group_size(16)]] {
int group = it.get_group()[0];
int gSize = it.get_local_range()[0];
auto sg = it.get_sub_group();
int sgSize = sg.get_local_range()[0];
int sgGroup = sg.get_group_id()[0];
unsigned long
histogram[NUM_BINS]; // histogram bins take too much storage to be
// promoted to registers
for (int k = 0; k < NUM_BINS; k++) {
histogram[k] = 0;
}
for (int k = 0; k < BLOCK_SIZE; k++) {
unsigned long x =
sg.load(macc.get_pointer() + group * gSize * BLOCK_SIZE +
sgGroup * sgSize * BLOCK_SIZE + sgSize * k);
#pragma unroll
for (int i = 0; i < 8; i++) {
unsigned int c = x & 0x1FU;
histogram[c] += 1;
x = x >> 8;
}
}
for (int k = 0; k < NUM_BINS; k++) {
hacc[k].fetch_add(histogram[k]);
}
});
});
This example calculates histograms with a bin size of 32. Each work item has 32 private bins of unsigned long data type. Because of the large storage required, the private bins cannot fit in registers, resulting in poor performance.
With BLOCK_SIZE 256, the maximum value of each private histogram bin will not exceed the maximum value of an unsigned integer. Instead of unsigned long type for private histogram bins, we can use unsigned integers to reduce register pressure so the private bins can fit in registers. This simple change makes significant performance difference.
constexpr int BLOCK_SIZE = 256;
constexpr int NUM_BINS = 32;
std::vector<unsigned long> hist(NUM_BINS, 0);
sycl::buffer<unsigned long, 1> mbuf(input.data(), N);
sycl::buffer<unsigned long, 1> hbuf(hist.data(), NUM_BINS);
auto e = q.submit([&](auto &h) {
sycl::accessor macc(mbuf, h, sycl::read_only);
auto hacc = hbuf.get_access<sycl::access::mode::atomic>(h);
h.parallel_for(
sycl::nd_range(sycl::range{N / BLOCK_SIZE}, sycl::range{64}),
[=](sycl::nd_item<1> it) [[intel::reqd_sub_group_size(16)]] {
int group = it.get_group()[0];
int gSize = it.get_local_range()[0];
auto sg = it.get_sub_group();
int sgSize = sg.get_local_range()[0];
int sgGroup = sg.get_group_id()[0];
unsigned int histogram[NUM_BINS]; // histogram bins take less storage
// with smaller data type
for (int k = 0; k < NUM_BINS; k++) {
histogram[k] = 0;
}
for (int k = 0; k < BLOCK_SIZE; k++) {
unsigned long x =
sg.load(macc.get_pointer() + group * gSize * BLOCK_SIZE +
sgGroup * sgSize * BLOCK_SIZE + sgSize * k);
#pragma unroll
for (int i = 0; i < 8; i++) {
unsigned int c = x & 0x1FU;
histogram[c] += 1;
x = x >> 8;
}
}
for (int k = 0; k < NUM_BINS; k++) {
hacc[k].fetch_add(histogram[k]);
}
});
});
Do Not Declare Private Variables as Volatile
Now we make a small change to the code example:
constexpr int BLOCK_SIZE = 256;
constexpr int NUM_BINS = 32;
std::vector<unsigned long> hist(NUM_BINS, 0);
sycl::buffer<unsigned long, 1> mbuf(input.data(), N);
sycl::buffer<unsigned long, 1> hbuf(hist.data(), NUM_BINS);
auto e = q.submit([&](auto &h) {
sycl::accessor macc(mbuf, h, sycl::read_only);
auto hacc = hbuf.get_access<sycl::access::mode::atomic>(h);
h.parallel_for(sycl::nd_range(sycl::range{N / BLOCK_SIZE}, sycl::range{64}),
[=](sycl::nd_item<1> it) [[intel::reqd_sub_group_size(16)]] {
int group = it.get_group()[0];
int gSize = it.get_local_range()[0];
auto sg = it.get_sub_group();
int sgSize = sg.get_local_range()[0];
int sgGroup = sg.get_group_id()[0];
volatile unsigned int
histogram[NUM_BINS]; // volatile variables will not
// be assigned to any registers
for (int k = 0; k < NUM_BINS; k++) {
histogram[k] = 0;
}
for (int k = 0; k < BLOCK_SIZE; k++) {
unsigned long x = sg.load(
macc.get_pointer() + group * gSize * BLOCK_SIZE +
sgGroup * sgSize * BLOCK_SIZE + sgSize * k);
#pragma unroll
for (int i = 0; i < 8; i++) {
unsigned int c = x & 0x1FU;
histogram[c] += 1;
x = x >> 8;
}
}
for (int k = 0; k < NUM_BINS; k++) {
hacc[k].fetch_add(histogram[k]);
}
});
});
The private histogram array is qualified as a volatile array. Volatile variables are not prompted to registers because their values may change between two different load operations.
There is really no reason for the private histogram array to be volatile, because it is only accessible by the local execution thread. In fact, if a private variable really needs to be volatile, it is not private any more.
Sharing Registers in a Sub-group
Now we increase the histogram bins to 256:
constexpr int BLOCK_SIZE = 256;
constexpr int NUM_BINS = 256;
std::vector<unsigned long> hist(NUM_BINS, 0);
sycl::buffer<unsigned long, 1> mbuf(input.data(), N);
sycl::buffer<unsigned long, 1> hbuf(hist.data(), NUM_BINS);
auto e = q.submit([&](auto &h) {
sycl::accessor macc(mbuf, h, sycl::read_only);
auto hacc = hbuf.get_access<sycl::access::mode::atomic>(h);
h.parallel_for(
sycl::nd_range(sycl::range{N / BLOCK_SIZE}, sycl::range{64}),
[=](sycl::nd_item<1> it) [[intel::reqd_sub_group_size(16)]] {
int group = it.get_group()[0];
int gSize = it.get_local_range()[0];
auto sg = it.get_sub_group();
int sgSize = sg.get_local_range()[0];
int sgGroup = sg.get_group_id()[0];
unsigned int
histogram[NUM_BINS]; // histogram bins take too much storage to be
// promoted to registers
for (int k = 0; k < NUM_BINS; k++) {
histogram[k] = 0;
}
for (int k = 0; k < BLOCK_SIZE; k++) {
unsigned long x =
sg.load(macc.get_pointer() + group * gSize * BLOCK_SIZE +
sgGroup * sgSize * BLOCK_SIZE + sgSize * k);
#pragma unroll
for (int i = 0; i < 8; i++) {
unsigned int c = x & 0x1FU;
histogram[c] += 1;
x = x >> 8;
}
}
for (int k = 0; k < NUM_BINS; k++) {
hacc[k].fetch_add(histogram[k]);
}
});
});
With 256 histogram bins, the performance degrades even with smaller data type unsigned integer. The storage of the private bins in each work item is too large for registers.
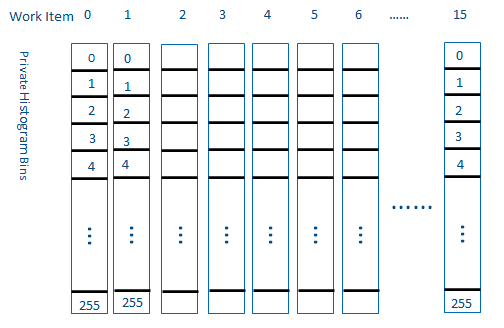
If the sub-group size is 16 as requested, we know that 16 work items are packed into one EU thread. We also know work items in the same sub-group can communicate and share data with each other very efficiently. If the work items in the same sub-group share the private histogram bins, only 256 private bins are needed for the whole sub-group, or 16 private bins for each work item instead.
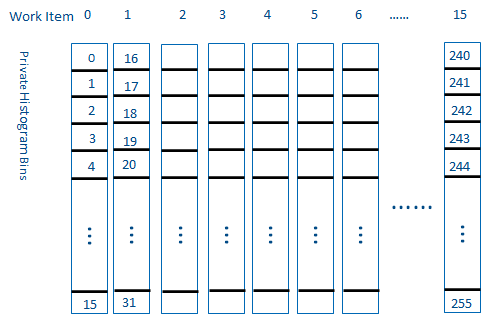
To share the histogram bins in the sub-group, each work item broadcasts its input data to every work item in the same sub-group. The work item that owns the corresponding histogram bin does the update.
constexpr int BLOCK_SIZE = 256;
constexpr int NUM_BINS = 256;
std::vector<unsigned long> hist(NUM_BINS, 0);
sycl::buffer<unsigned long, 1> mbuf(input.data(), N);
sycl::buffer<unsigned long, 1> hbuf(hist.data(), NUM_BINS);
auto e = q.submit([&](auto &h) {
sycl::accessor macc(mbuf, h, sycl::read_only);
auto hacc = hbuf.get_access<sycl::access::mode::atomic>(h);
h.parallel_for(
sycl::nd_range(sycl::range{N / BLOCK_SIZE}, sycl::range{64}),
[=](sycl::nd_item<1> it) [[intel::reqd_sub_group_size(16)]] {
int group = it.get_group()[0];
int gSize = it.get_local_range()[0];
auto sg = it.get_sub_group();
int sgSize = sg.get_local_range()[0];
int sgGroup = sg.get_group_id()[0];
unsigned int
histogram[NUM_BINS / 16]; // histogram bins take too much storage
// to be promoted to registers
for (int k = 0; k < NUM_BINS / 16; k++) {
histogram[k] = 0;
}
for (int k = 0; k < BLOCK_SIZE; k++) {
unsigned long x =
sg.load(macc.get_pointer() + group * gSize * BLOCK_SIZE +
sgGroup * sgSize * BLOCK_SIZE + sgSize * k);
// subgroup size is 16
#pragma unroll
for (int j = 0; j < 16; j++) {
unsigned long y = sycl::group_broadcast(sg, x, j);
#pragma unroll
for (int i = 0; i < 8; i++) {
unsigned int c = y & 0xFF;
// (c & 0xF) is the workitem in which the bin resides
// (c >> 4) is the bin index
if (sg.get_local_id()[0] == (c & 0xF)) {
histogram[c >> 4] += 1;
}
y = y >> 8;
}
}
}
for (int k = 0; k < NUM_BINS / 16; k++) {
hacc[16 * k + sg.get_local_id()[0]].fetch_add(histogram[k]);
}
});
});
Using Sub-group Block Load/Store
Memory loads/stores are vectorized. Each lane of a vector load/store instruction has its own address and data. Both addresses and data take register space. For example:
constexpr int N = 1024 * 1024;
int *data = sycl::malloc_shared<int>(N, q);
int *data2 = sycl::malloc_shared<int>(N, q);
memset(data2, 0xFF, sizeof(int) * N);
auto e = q.submit([&](auto &h) {
h.parallel_for(sycl::nd_range(sycl::range{N}, sycl::range{32}),
[=](sycl::nd_item<1> it) {
int i = it.get_global_linear_id();
data[i] = data2[i];
});
});
The memory loads and stores in the statement
data[i] = data2[i];
are vectorized and each vector lane has its own address. Assuming the SIMD width or the sub-group size is 16, total register space for addresses of the 16 lanes is 128 bytes. If each GRF register is 32-byte wide, 4 GRF registers are needed for the addresses.
Noticing the addresses are contiguous, we can use sub-group block load/store built-ins to save register space for addresses:
constexpr int N = 1024 * 1024;
int *data = sycl::malloc_shared<int>(N, q);
int *data2 = sycl::malloc_shared<int>(N, q);
memset(data2, 0xFF, sizeof(int) * N);
auto e = q.submit([&](auto &h) {
h.parallel_for(
sycl::nd_range(sycl::range{N}, sycl::range{32}),
[=](sycl::nd_item<1> it) [[intel::reqd_sub_group_size(16)]] {
auto sg = it.get_sub_group();
int x;
using global_ptr =
sycl::multi_ptr<int, sycl::access::address_space::global_space>;
int base = (it.get_group(0) * 32 +
sg.get_group_id()[0] * sg.get_local_range()[0]);
x = sg.load(global_ptr(&(data2[base + 0])));
sg.store(global_ptr(&(data[base + 0])), x);
});
});
The statements
x = sg.load(global_ptr(&(data2[base + 0]))); sg.store(global_ptr(&(data[base + 0])), x);
each loads/stores a contiguous block of memory and the compiler will compile these 2 statements into special memory block load/store instructions. And because it is a contiguous memory block, we only need the starting address of the block. So 8, instead of 128, bytes of actual register space, or at most 1 register, is used for the address for each block load/store.
Using Shared Local Memory
If the number of histogram bins gets larger than, for example, 1024, there will not be enough register space for private bins even the private bins are shared in the same sub-group. To reduce memory traffic, the local histogram bins can be allocated in the shared local memory and shared by work items in the same work-group. Refer to the “Shared Local Memory” chapter and see how it is done in the histogram example there.