A newer version of this document is available. Customers should click here to go to the newest version.
Programming Principles
To achieve good performance with implicit scaling, cross-stack memory accesses must be minimized but it is not required to eliminate all cross-stack accesses. A certain amount of cross-stack traffic can be handled by stack-to-stack interconnect if performed concurrently with local memory accesses. For memory bandwidth bound workload the amount of acceptable cross-stack accesses is determined by ratio of local memory bandwidth and cross-stack bandwidth (see Cross-Stack Traffic).
The following principles should be embraced by workloads that use implicit scaling:
Kernel must have enough work-items to utilize both stacks.
The minimal number of work-items needed to utilize both stacks is: <number of VEs> * <hardware-threads per VE> * <SIMD width>.
2 stack Intel® Data Center GPU Max with 1024 VE and SIMD32 requires at least 262,144 work-items.
Device time must dominate runtime to observe whole application scaling.
Minimize cross-stack memory accesses by exploiting locality in algorithm.
Slowest moving dimension should be large to avoid stack load imbalance.
Cross-stack memory accesses and local memory accesses should be interleaved.
Avoid stride-1 memory access in slowest moving dimension for 2D and 3D kernel launches.
If memory access pattern changes dynamically over time, a sorting step every nth iteration should be performed to minimize cross-stack memory accesses.
Don’t use a memory pool based on a single allocation (see Memory Coloring).
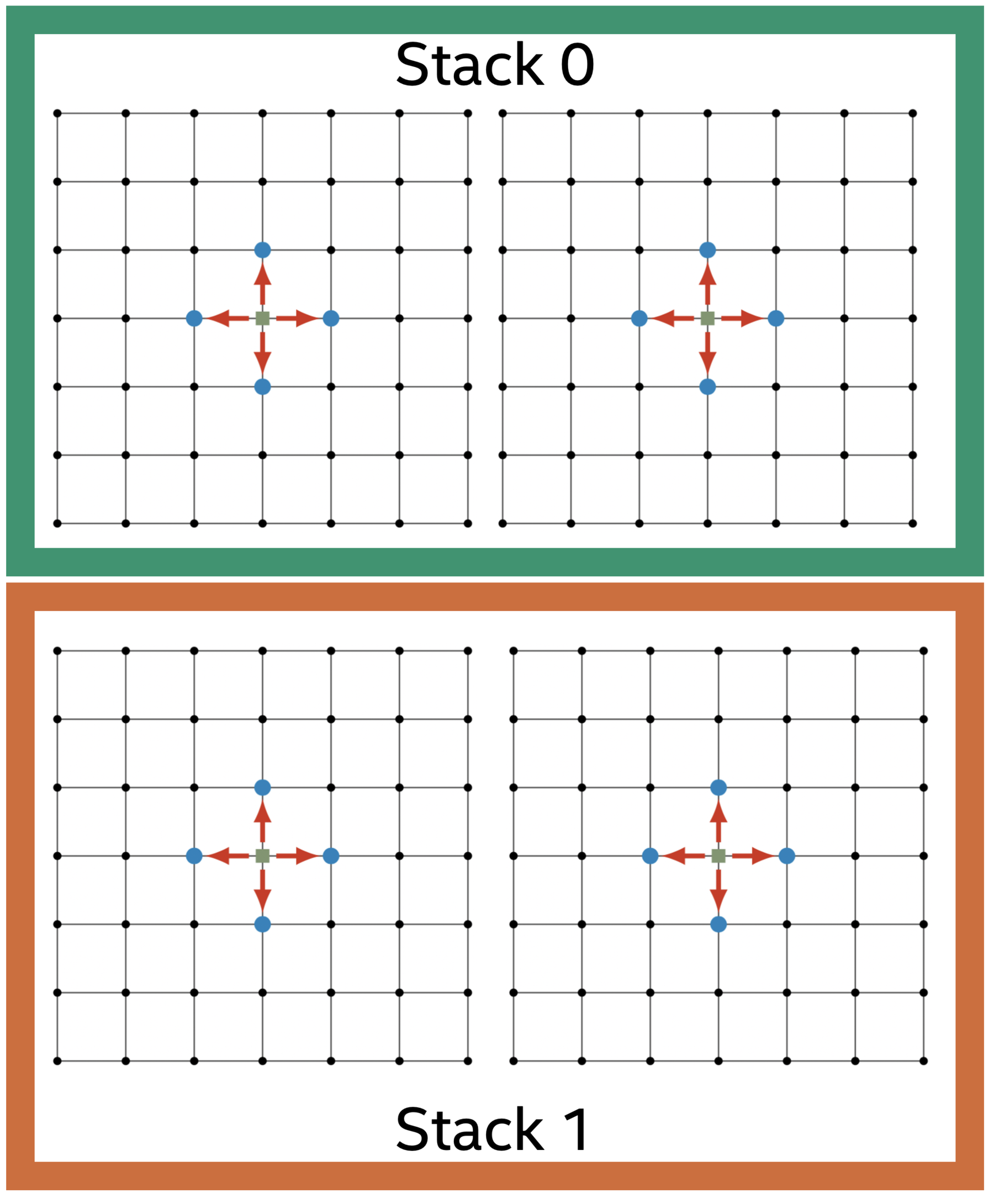
Many applications naturally have a concept of locality. These applications are expected to be a good fit for using implicit scaling due to low cross-stack traffic. To illustrate this concept, let’s use a stencil kernel as an example. A stencil operates on a grid which can be divided into blocks where majority of stencil computations within a block use stack local data. Only stencil operations that are at border of the block require data from another block, i.e. on another stack. The amount of these cross-stack/cross-border accesses are suppressed by halo to local volume ratio. This concept is illustrated below:
Cross-Stack Traffic
As mentioned in last section, it is crucial to minimize cross-stack traffic. To guide how much traffic can be tolerated without significantly impacting application performance we can benchmark STREAM kernel with varying amount of cross-stack traffic and compare to stack-local STREAM performance. The worst case is 100% cross-stack traffic. This is generated by reversing loop order in STREAM kernel (see STREAM):
#pragma omp target teams distribute parallel for simd
for (int i = N - 1; i <= 0; --i)
{
c[i] = a[i] + b[i];
}
Here, each stack has 100% cross-stack memory traffic as work-groups on stack-0 access array elements N-1 to N/2 which are located in stack-1 memory. This kernel essentially benchmarks stack-to-stack bi-directional bandwidth. This approach can be generalized to interpolate between 0% cross-stack accesses and 100% cross-stack accesses by modified STREAM below:
// Code for cross stack stream
#include <iostream>
#include <omp.h>
// compile via:
// icpx -O2 -fiopenmp -fopenmp-targets=spir64 ./stream_cross_stack.cpp
// run via:
// EnableWalkerPartition=1 ZE_AFFINITY_MASK=0 ./a.out
template <int cross_stack_fraction>
void cross_stack_stream() {
constexpr int64_t size = 256*1e6;
constexpr int64_t bytes = size * sizeof(int64_t);
int64_t *a = static_cast<int64_t*>(malloc( bytes ));
int64_t *b = static_cast<int64_t*>(malloc( bytes ));
int64_t *c = static_cast<int64_t*>(malloc( bytes ));
#pragma omp target enter data map( alloc:a[0:size] )
#pragma omp target enter data map( alloc:b[0:size] )
#pragma omp target enter data map( alloc:c[0:size] )
for ( int i = 0; i < size; ++i ) {
a[i] = i + 1;
b[i] = i - 1;
c[i] = 0;
}
#pragma omp target update to( a[0:size] )
#pragma omp target update to( b[0:size] )
#pragma omp target update to( c[0:size] )
const int num_max_rep = 100;
double time;
for ( int irep = 0; irep < num_max_rep+10; ++irep ) {
if ( irep == 10 ) time = omp_get_wtime();
#pragma omp target teams distribute parallel for simd
for ( int j = 0; j < size; ++j ) {
const int cache_line_id = j / 16;
int i;
if ( (cache_line_id%cross_stack_fraction) == 0 ) {
i = (j+size/2)%size;
}
else {
i = j;
}
c[i] = a[i] + b[i];
}
}
time = omp_get_wtime() - time;
time = time/num_max_rep;
#pragma omp target update from( c[0:size] )
for ( int i = 0; i < size; ++i ) {
if ( c[i] != 2*i ) {
std::cout << "wrong results!" << std::endl;
exit(1);
}
}
const int64_t streamed_bytes = 3 * size * sizeof(int64_t);
std::cout << "cross_stack_percent = " << (1/(double)cross_stack_fraction)*100
<< "%, bandwidth = " << (streamed_bytes/time) * 1E-9 << " GB/s" << std::endl;
}
int main() {
cross_stack_stream< 1>();
cross_stack_stream< 2>();
cross_stack_stream< 4>();
cross_stack_stream< 8>();
cross_stack_stream<16>();
cross_stack_stream<32>();
}
The kernel on line 48-65 accesses every cross_stack_fraction'th cache line cross-stack by offsetting array access with (j+N/2)%N. For cross_stack_fraction==1, we generate 100% cross-stack memory accesses. By doubling cross_stack_fraction we decrease cross-stack traffic by a factor of 2. Note that this kernel is written such that cross-stack and local memory accesses are interleaved within work-groups to maximize hardware utilization. Measured performance on 2-stack Intel® Data Center GPU Max with 2 GB array size can be seen below:
Partial cross-stack STREAM bandwidth [GB/s] |
cross_stack_fraction |
% of cross-stack accesses |
% of max local 2-stack STREAM bandwidth |
|---|---|---|---|
355 |
1 |
100% |
17% |
696 |
2 |
50% |
33% |
1223 |
4 |
25% |
58% |
1450 |
8 |
12.5% |
69% |
1848 |
16 |
6.25% |
87% |
2108 |
32 |
3.125% |
99% |
As can be seen in above table, applications should try to limit cross-stack traffic to be less than 10% of all memory traffic to avoid a significant drop in sustained memory bandwidth. For STREAM with of 12.5% cross-stack accesses we measure about 69% of the bandwidth of a local STREAM benchmark. These numbers can be used to estimate impact of cross-stack memory accesses on application kernel execution time.