Overview
The remarkable size of large language models (LLMs) has brought about a groundbreaking transformation in human-language applications. Nonetheless, AI developers and researchers often encounter obstacles stemming from the massive size and latency associated with these models. These challenges can hamper collaboration and hinder progress in building robust applications. In this article, we show how to take advantage of weight-only quantization (WOQ) to improve LLM inference using Intel® Extension for PyTorch* on AI PCs featuring Intel® Core™ Ultra processors (formerly code named Meteor Lake).
Intel Extension for PyTorch extends PyTorch with up-to-date optimizations for an extra performance boost on Intel® hardware. Optimizations take advantage of Intel® Xe Matrix Extensions (Intel® XMX) AI engines on Intel discrete GPUs. Moreover, recently Intel Extension for PyTorch provides easy GPU acceleration for all Intel GPUs through Explicit SIMD capabilities. Explicit SIMD SYCL* extension (or simply ESIMD) is a collection of APIs close to the Intel GPU Instruction Set Architecture (ISA) introduced in an optimized version of SYCL. ESIMD, as available in the Intel® toolkits, provides APIs like Intel's GPU ISA, but it enables you to write explicitly vectorized device code. This explicit enabling gives you more control over the generated code and allows you to depend less on compiler optimizations. Regular SYCL and ESIMD kernels can coexist in the same translation unit and in the same application.
Weight-quantization in Intel Extension for PyTorch
Generally speaking, LLM inference is a memory bandwidth bounded task for weight loading. Weight-only quantization (WOQ) is an effective performance optimization algorithm to reduce the total amount of memory access without losing accuracy. int4 GEMM with a weight-only quantization (WOQ) recipe specifies the weight of the kernel in int4 datatype, while the input and output are in float point, specified as FP16 datatype in our implementation.
Intel Extension for PyTorch provides customized GEMM kernels with int4 weight by ESIMD implementation to manipulate microbehaviors precisely. These customized GEMMs are implemented by reusable C++ templates at different levels from operator and kernel to workgroup and subgroup, allowing developers to optimize and specify kernels based on data types, tiling policies, algorithms, and fusion policies.
The int4 kernel workflow is shown in Figure 1. We first load a small tiling block of int4 weight (represented as a large green block) from the DRAM to SRAM in each workgroup, which is much more efficient than FP16 weight loading. Then, the int4 tiling block in SRAM will be dequantized into F16 datatype, followed up by the common matrix multiplied by F16 activation with FPU instructions. To reduce the dequantization overhead on the tiling block of weight, the pipeline recipe is adapted by overlapping the weight loading and dequantization computation.
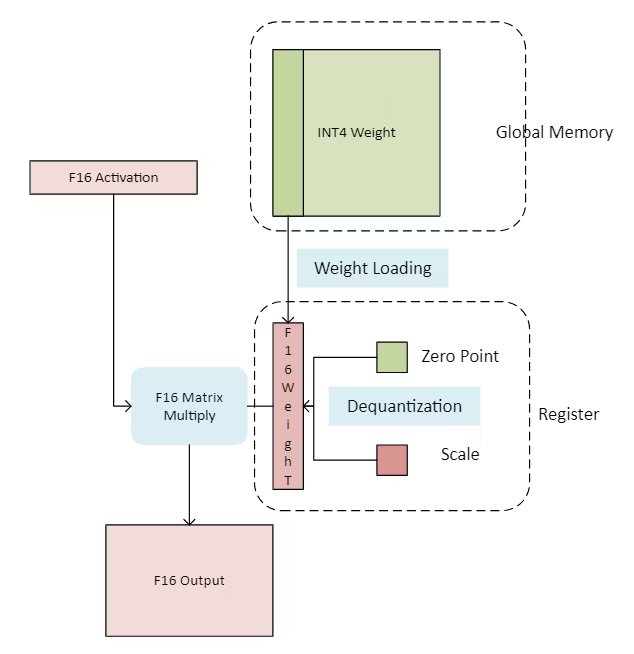
Figure 1. int4 GEMM workflow
You can use Intel Extension for PyTorch int4 capabilities by directly calling:
```python
out = torch.ops.torch_ipex.mm_bias_int4(input, weight, bias, scales, zps, group_size) # general INT4 GEMM
out = torch.ops.torch_ipex.mm_qkv_int4(input, weight, bias, scales, zps, group_size) # merged QKV INT4 GEMM
```
Run WOQ LLM with Intel Extension for PyTorch
The complete workflow is demonstrated in Figure 2. You can use either a pure PyTorch-like API to do inference or a transformer-like API based on Intel Extension for PyTorch.
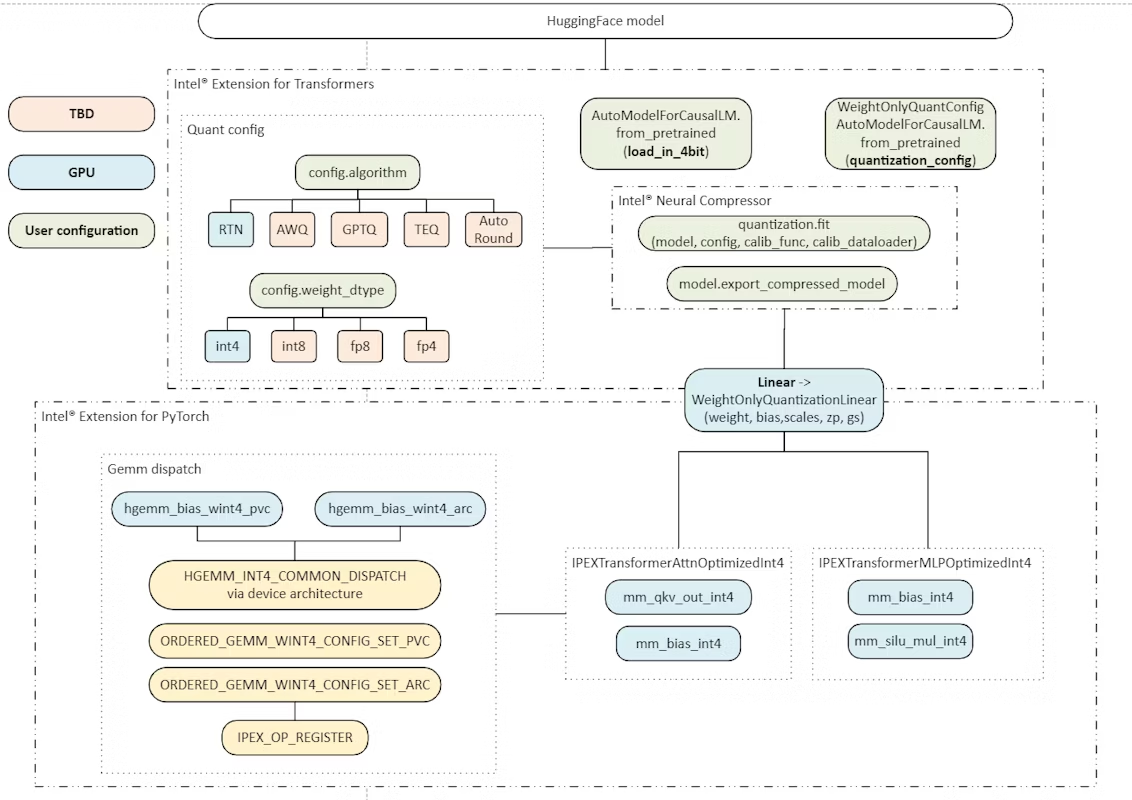
Figure 2. WOQ workflow
Step 1: Install Intel® Toolkits
Weight-only quantization ops is available in the dev/MTL branch on Intel Extension for PyTorch. It needs to be compiled with the oneAPI DPC++/C++ Compiler.
For instructions to install the Intel toolkits to the /opt/Intel folder, see the Installation Guides for Intel® Toolkits.
Step 2: Build and Install PyTorch and Intel Extension for PyTorch
```Shell
python -m pip install torch==2.1.0a0 -f https://developer.intel.com/ipex-whl-stable-xpu
source /opt/intel/oneapi/setvars.sh
# will update once external branch available
git clone https://github.com/intel-innersource/frameworks.ai.pytorch.ipex-gpu.git ipex-gpu
cd ipex-gpu
git checkout -b dev/MTL origin/dev/MTL
git submodule update --init --recursive
pip install -r requirements.txt
python setup.py install
```
Step 3: Install Intel® Extension for Transformers* and Intel® Neural Compressor
```shell
pip install neural-compressor
pip install intel-extension-for-transformers
```
Intel Extension for PyTorch relies on Intel® Neural Compressor and Intel® Extension for Transformers* for quantization as demonstrated in Figure 2. For accuracy, you can refer to the supported model list.
Step 4: Quantization Model and Inference Using PyTorch-like API
Option 1:
```
import torch
import intel_extension_for_pytorch as ipex
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "xpu"
model_name = "Qwen/Qwen-7B"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
prompt = "Once upon a time, there existed a little girl,"
inputs = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="xpu", trust_remote_code=True)
qconfig = ipex.quantization.get_weight_only_quant_qconfig_mapping(weight_dtype, lowp_mode, act_quant_mode, group_size)
qmodel = ipex.optimize_transformers(model, inplace=True, dtype=amp_type, quantization_config=qconfig, device=device)
output = qmodel.generate(inputs)
```
Option 2:
```python
import intel_extension_for_pytorch as ipex
from intel_extension_for_transformers.transformers.modeling import AutoModelForCausalLM
from transformers import AutoTokenizer
device = "xpu"
model_name = "Qwen/Qwen-7B"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
prompt = "Once upon a time, there existed a little girl,"
inputs = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
# woq_quantization_config = WeightOnlyQuantConfig(compute_dtype="fp16", weight_dtype="int4_fullrange", scale_dtype="fp16", group_size=64)
# qmodel = AutoModelForCausalLM.from_pretrained(model_name, device_map="xpu", quantization_config=woq_quantization_config, trust_remote_code=True)
qmodel = AutoModelForCausalLM.from_pretrained(model_name, load_in_4bit=True, device_map="xpu", trust_remote_code=True)
# optimize the model with ipex, it will improve performance.
qmodel = ipex.optimize_transformers(qmodel, inplace=True, quantization_config=”woq”, dtype=torch.float16, device="xpu")
output = qmodel.generate(inputs)
```
Note If your device memory is not enough, quantize and save the model first, and then rerun the example while loading the model as shown in the following example. If your device memory is enough, you can skip the following instructions, and just perform quantization and inference.
Save and Load a Quantized Model
```python
from intel_extension_for_transformers.transformers.modeling import AutoModelForCausalLM
qmodel = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", load_in_4bit=True, device_map="xpu", trust_remote_code=True)
# Please note, saving model should be executed before ipex.optimize_transformers function is called.
model.save_pretrained("saved_dir")
# Load model
loaded_model = AutoModelForCausalLM.from_pretrained("saved_dir", trust_remote_code=True)
```
Conclusion
In this article, we showed how to run WOQ LLM inference using Intel Extension for PyTorch. We also demonstrated the following:
- Intel Extension for PyTorch extends PyTorch with the latest performance optimizations for Intel hardware via ESIMD capabilities to run WOQ inference.
- To enable WOQ LLM with Intel Extension for PyTorch, simply add a few additional lines of code to use Intel Neural Compressor and Intel Extension for Transformers for quantization.
Similarly, you can run other LLMs models on any Intel GPUs.
Next Steps
Try out the Intel Extension for PyTorch on built-in Intel® Arc™ graphics drivers in Intel Core Ultra processors to run LLM inference on Windows* and Windows Subsystem for Linux* 2 (WSL 2).
Check out and incorporate Intel’s other AI and machine learning framework optimizations and end-to-end portfolio of tools into your AI workflow.
Learn about the unified, open, standards-based oneAPI programming model that forms the foundation of the Intel® AI Portfolio to help you prepare, build, deploy, and scale your AI solutions.
References
Data Parallel C++: the oneAPI Implementation of SYCL*
PyTorch* Optimizations from Intel
Intel is one of the largest contributors to PyTorch*, providing regular upstream optimizations to the PyTorch deep learning framework that provide superior performance on Intel® architectures. The AI Tools includes the latest binary version of PyTorch tested to work with the rest of the kit, along with Intel® Extension for PyTorch*, which adds the newest Intel optimizations and usability features.