Overview
This article demonstrates how to use the SYCL_EXTERNAL macro to invoke C++ host functions inside a SYCL* kernel.
The host (CPU) code in an application manages data movement and offloads the computation onto devices (GPU, FPGA, or any accelerator).
Compile C++ and SYCL* source files for CPUs and a wide range of accelerators (such as GPUs and FPGAs) with the Intel® oneAPI DPC++ Compiler.
SYCL_EXTERNAL is an optional macro that enables external linking of SYCL functions and methods to be included inside a SYCL kernel.
The SYCL applications follow a default behavior: All definitions and declarations of C++ functions are available in the same translation unit for the compiler. To link the functions that are defined in a different translational unit, they must be preceded with the SYCL_EXTERNAL macro.
A translation unit is the actual input to the compiler. It is made from the source file after it is processed by the C preprocessor to inline the header files and expand macros.
To access the host (CPU) functions from the device (GPU), we need to label that function with the SYCL_EXTERNAL macro.
This article demonstrates how to use the SYCL_EXTERNAL macro and provides the steps to build the application on Linux* and Windows* environments.
Prerequisites
To build a DPC++ application, you need to install the Intel® oneAPI DPC++ Compiler.
This compiler is available in the Intel® oneAPI Base Toolkit and Intel® oneAPI HPC Toolkit. It is also available as a stand-alone product.
Hardware Requirements
Systems based on the following Intel® 64 architectures are supported both as host and target platforms:
- Intel® Core™ processor family
- Intel® Xeon® processor family
- Intel® Xeon® Scalable processor family
Requirements for Accelerators:
Examples Using SYCL_EXTERNAL
You can now build a DPC++ example. This section explains the example code that includes the SYCL_EXTERNAL macro with buffer and Unified Shared Memory (USM) models.
Environment Setup
To compile and run the DPC++ programs, initialize the oneAPI environment before building any DPC++ application.
Set up the environment by running the appropriate script:
- Linux: source /opt/intel/oneapi/setvars.sh
- Windows:
- Intel oneAPI command prompt: Environment variables are set by default.
- Windows command prompt: Drive:\Program Files (x86)\Intel\oneAPI\setvars.bat
Without SYCL_EXTERNAL Macro
If a C++ function is directly invoked in a SYCL kernel, the following appears:
error: SYCL kernel cannot call an undefined function without SYCL_EXTERNAL attribute
To resolve the error, label the C++ functions with the SYCL_EXTERNAL macro in the header file as described in the following example.
Examples
The code in this example adds the corresponding elements of two vectors. Vector addition is a fundamental computation used in many linear algebraic algorithms.
This section demonstrates adding two vectors using SYCL buffers and a USM model.
Sample 1: SYCL* Buffers
Use buffers and accessors to store and access the data inside a SYCL kernel. SYCL runtime takes care of moving data between the host and the device.
For more information on the buffer model, see the Developer Guide.
Step 1
Create a header file, and then declare the function as SYCL_EXTERNAL to invoke this function in the SYCL kernel:
Header.h
#pragma once
#include<CL/sycl.hpp>
extern SYCL_EXTERNAL void vectorAdd (cl::sycl::accessor<int, 1, cl::sycl::access::mode::read> A, cl::sycl::accessor<int, 1, cl::sycl::access::mode::read> B, cl::sycl::accessor<int, 1, cl::sycl::access::mode::write> C, int numElement, cl::sycl::item<1> item_ct1);
#pragma once
The pragma gives instructions to the compiler to include the header file once. The compiler does not open nor read the header file again after the first #include of the file in the translation unit.
Step 2
Define the body of the function that is declared in header.h. Include this header file in your main file (Main.cpp) and also in the function definition file kernel.cpp (described next).
Kernel.cpp
The following is the example code that computes adding two vectors using accessors.
#include <CL/sycl.hpp>
#include<iostream>
#include "header.h"
void vectorAdd (cl::sycl::accessor<int, 1, cl::sycl::access::mode::read> A, cl::sycl::accessor<int, 1, cl::sycl::access::mode::read> B, cl::sycl::accessor<int, 1, cl::sycl::access::mode::write> C, int numElement, cl::sycl::item<1> item_ct1) {
int i = item_ct1.get_linear_id();
if(i<numElement)
{
C[i]=A[i]+B[i];
}
}
Main.cpp
To help you understand how each feature is used in SYCL, this section explains the flow of the DPC++ program using buffers and accessors.
The following is an example main.cpp file. It uses buffers and accessors to invoke a C++ host function inside a kernel.
#include <CL/sycl.hpp>
#include <iostream>
#include "header.h"
#define numElements 10
#define size 1024
using namespace std;
using namespace sycl;
int main(void)
{
cl::sycl::queue queue(cl::sycl::gpu_selector{});
std::cout<<"Running on " << queue.get_device().get_info<cl::sycl::info::device::name>() << "\n";
std::vector<int> A(size, size), B(size, size), C(size, 0);
{
range<1> R(size);
buffer<int,1> buffA(A.data(), R);
buffer<int,1> buffB(B.data(), R);
buffer<int,1> buffC(C.data(), R);
queue.submit([&](cl::sycl::handler& cgh) {
auto acc_buffA = buffA.get_access<access::mode::read>(cgh);
auto acc_buffB = buffB.get_access<access::mode::read>(cgh);
auto acc_buffC = buffC.get_access<access::mode::write>(cgh);
cgh.parallel_for(
R, [=](cl::sycl::item<1> item_ct1) {
vectorAdd(acc_buffA, acc_buffB, acc_buffC,size,item_ct1);
});
});
}
queue.wait();
for(int i=0;i<10;i++)
{
std::cout<<C[i]<<std::endl;
}
return 0;
}
Include the header file for the whole SYCL runtime:
#include <CL/sycl.hpp>
a. Create a Queue
Create a command queue with the device selector. Any data that you want to offload to a device is submitted to this queue.
The queue is created inside a main() using the gpu_selector(). If no compatible device is found, it falls back to the host or CPU.
cl::sycl::queue queue(cl::sycl::gpu_selector{});
Display the device information using the following API.
queue.get_device().get_info<cl::sycl::info::device::name>()
b. Create and Initialize the Vectors
Three vectors are created. Two vectors take inputs and one vector stores the results and is initialized with 1024.
std::vector<int> A(size, size);
buffer<int,1> buffB(B.data(), R);
buffer<int,1> buffC(C.data(), R);
To start the SYCL scope:
{ }
The SYCL scope communicates to the compiler that the device can access the code defined in scope({}).
When the scope ends, the memory returns to the host by destroying buffers.
c. Define a Range
Range describes the number of elements in the buffer with one, two, and three dimensions.
range<1> R(size);
d. Create Buffers
Buffers store data that is available on the host and device for read and write operations.
The buffers synchronize after the SYCL scope is destroyed.
buffer<int,1> buffA(A.data(), R);
e. Queue Submit
Submit the lambda function through a command group that contains data access and device computations.
SYCL creates the command group handler at runtime to keep track of data dependencies. A lambda defines the scope of the command group.
queue.submit([&](cl::sycl::handler& cgh)
f. Create Accessors
To give read and write access to the data on the device, create accessors for three buffers of vectors.
auto acc_buffA = buffA.get_access<access::mode::read>(cgh);
g. Parallel_for
Multiple threads on the device launch multiple iterations of parallel_for simultaneously. Parallel_for passes the range and lambda function that includes the computation to be performed on the device as parameters.
Call the C++ functions and methods in the parallel_for that is defined in the header file.
Queue.wait() is used for synchronization.
When the SYCL scope ends, the SYCL runtime copies the data back to the host.
handler::parallel_for(numWorkItems, rest)
Sample 2: USM Model
Use a pointer to write a USM model (a DPC++ application). USM is a pointer-based approach to manage the memory on the host and the device. It allows reading and writing of data using pointers (unlike buffers).
For more information on the model, see Unified Shared Memory.
Step 1
To call the header.h function in a SYCL kernel, create a header file declaring the C++ function with the SYCL_EXTERNAL macro.
Header.h
#pragma once
#include<CL/sycl.hpp>
extern SYCL_EXTERNAL void vectorAdd(float *A, float *B, float *C, int numElement, cl::sycl::item<1> item_ct1);
Step 2
Include a header file (header.h) in your main file (main.cpp) and in the function definition file (kernel.cpp).
Kernel.cpp
To compute the addition of two vectors using pointers, use the following code:
#include <CL/sycl.hpp>
#include"header.h"
void vectorAdd(float *A, float *B, float *C, int numElement, cl::sycl::item<1> item_ct1)
{
int i = item_ct1.get_linear_id();
if (i < numElement)
{
C[i] = A[i] + B[i];
}
}
Main.cpp
In this model, use pointers to store and access the data on the host and device. The following example code computes adding two vectors that use pointers to invoke a host function inside a kernel.
#include <CL/sycl.hpp>
#include <iostream>
#include "header.h"
#define numElements 10
using namespace std;
int main(void){
size_t size = numElements * sizeof(float);
cl::sycl::queue queue( cl::sycl::gpu_selector{});
std::cout << "Running on " <<
queue.get_device().get_info<cl::sycl::info::device::
name>() << "\n";
float *d_A = static_cast<float*>(malloc_shared(size, queue));
float *d_B = static_cast<float*>(malloc_shared(size, queue));
float *d_C = static_cast<float*>(malloc_shared(size, queue));
for (int i = 0; i < numElements; ++i)
{
d_A[i] = 1024.0f;
d_B[i] = 1024.0f;
d_C[i]=0.0f;
}
{
queue.submit(
[&](cl::sycl::handler &cgh) {
cgh.parallel_for<class vectorAdd_e83213>(
cl::sycl::range<1>{numElements}, [=](cl::sycl::item<1> item_ct1) {
vectorAdd(d_A, d_B, d_C, numElements, item_ct1); //defined in other file
});
});
}
queue.wait();
for(int i=0;i<numElements;i++)
cout<<d_A[i]<<" "<<d_B[i]<<" "<<d_C[i]<<" "<<endl;
cout<<endl;
free(d_A,queue);
free(d_B,queue);
free(d_C,queue);
return 0;
}
a. Create a Queue
Create a command queue with the device selector. Any data that is offloaded to a device is submitted to this queue.
The queue is created inside a main() using the gpu_selector(). If no compatible device is found, the queue falls back to the host or CPU.
cl::sycl::queue queue(cl::sycl::gpu_selector{});
Display the device information using the following API:
queue.get_device().get_info<cl::sycl::info::device::name>()
b. Create and Initialize the Vectors
This USM model uses different memory allocation methods to store and copy the data between the host and the device.
This example initializes vectors using malloc_shared() so that the data is available on the host and device. There is no need to copy the data between the host and the device.
float *d_A = static_cast<float*>(malloc_shared(size, queue));
You can also use different memory allocation methods by coping the data from:
- The host to the device
- The device to the host
c. Queue Submit
To define an asynchronous task, create a command group.
There is no need to use accessors to access the data on the device because you created vectors using the malloc_shared allocation. This ensures that the data is available on the host and device.
queue.submit([&](cl::sycl::handler& cgh)
d. Parallel_for
handler::parallel_for(numWorkItems, rest)
Multiple threads on the device simultaneously launch multiple iterations of parallel_for. Parallel_for passes the range and lambda functions that include computation to be performed on the device as parameters.
Invoke the C++ function or method by passing the pointer as an argument in the kernel.
vectorAdd(d_A, d_B, d_C, numElements, item_ct1);
Queue.wait() is invoked for the synchronization purpose.
To release the memory assigned to the variable, free the device variables:
free(d_B,queue);
Note If you have many functions similar to vectorAdd(), it's difficult to label the SYCL_EXTERNAL macro on all those functions in the header and kernel files. To make adding SYCL_EXTERNAL easier, use macro definitions in the header file:
#if defined __INTEL_LLVM_COMPILER && SYCL_LANGUAGE_VERISON
#include <CL/sycl.hpp>
#else
#define SYCL_EXTERNAL
#endif
Extern SYCL_EXTERNAL void Vectoradd();
Build the Application
On Linux*
To enable the oneAPI environment, source the setvars.sh script:
>source /opt/intel/oneapi/setvars.sh
Method 1
Generate the object file for the kernel.cpp file.
To generate the executable, link the object file with the main.cpp file.
Use the following commands to build and run the DPC++ program:
>dpcpp -c kernel.cpp
>dpcpp kernel.o main.cpp
>./a.out
Method 2
To generate the executable, compile the main.cpp and kernel.cpp files separately, and then link them:
dpcpp -c kernel.cpp
dpcpp -c main.cpp
dpcpp kernel.co main.o
./a.out
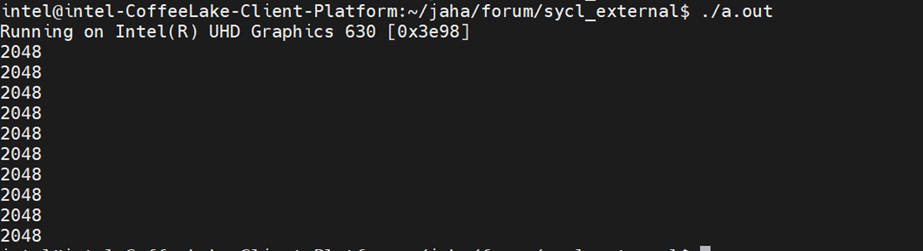
The following image displays the output from the DPC++ application:
On Windows*
You can build the application using Microsoft Visual Studio* or a command prompt in Intel oneAPI.
Use Visual Studio*
Note To run the DPC++ application, you must install a supported version of Visual Studio. For supported versions, see Compatibility.
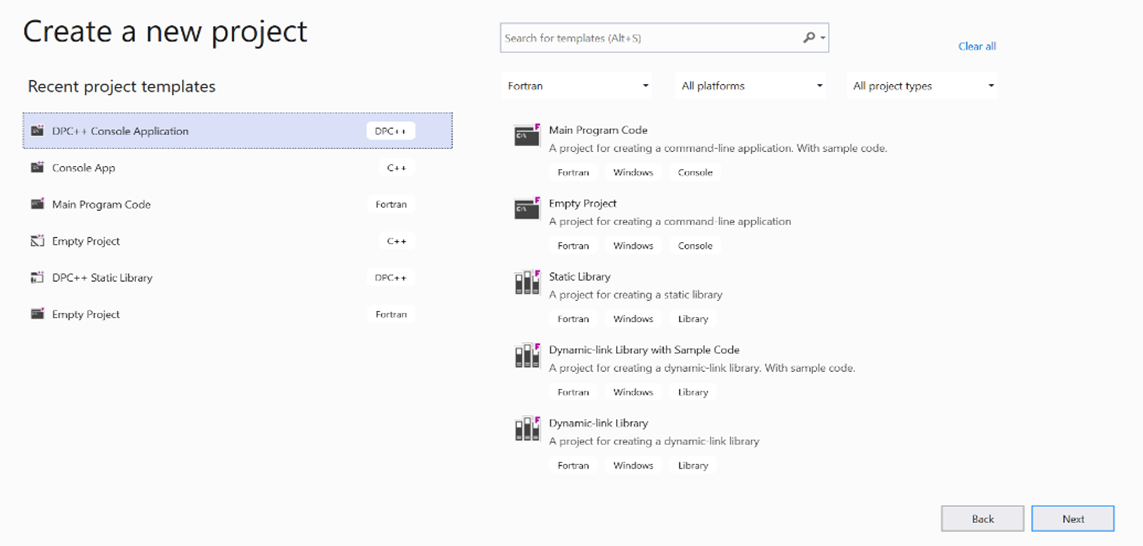
To create a DPC++ console application in Visual Studio:
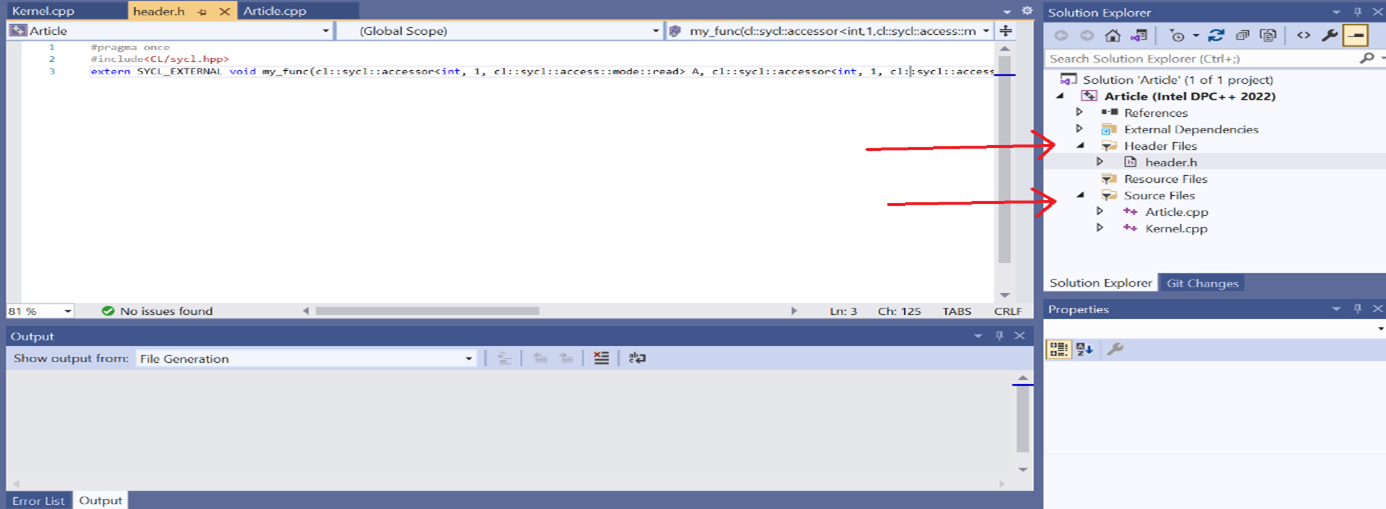
- To add the header file:
- Right-click on the Header section, select Add, and then select a new Item.
- Select Header File, and then add the source code.
- To add the kernel.cpp file in the source files:
- Right-click Source Files, select Add, and then select a new Item.
- Select a .cpp file from the options, and then add the code to that file.
- To build the program:
- To run the program:

To generate the executable, Visual Studio compiles main.cpp and kernel.cpp separately, and then links them.
The following image displays the output from the DPC++ application.

Use the Intel oneAPI Command Prompt
- Open the Intel oneAPI command prompt. By default, it sets the environment by sourcing the setvars.bat file.
Tip You can also build your application using the Windows command prompt, but you need to source the setvars.bat file: Drive:\Program Files (x86)\Intel\oneAPI\setvars.bat - To build and run the application, use the following commands:
Method 1
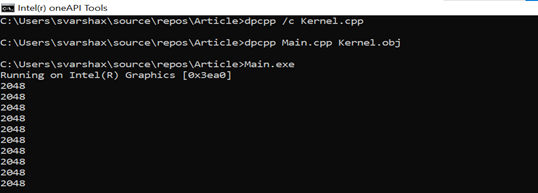
dpcpp /c kernel.cpp
dpcpp kernel.obj main.cpp
main.exe
Method 2
To generate the executable, compile main.cpp and kernel.cpp separately, and then link them:
dpcpp -c kernel.cpp
dpcpp -c main.cpp
dpcpp kernel.co main.o
./a.out
The following image shows the output from the DPC++ application:
Limitations to Using SYCL_EXTERNAL
- This macro can only be used on functions.
- Its functions cannot:
- Use raw pointers as parameter or return types. Explicit pointer classes must be used instead.
- Call a parallel_for_ work_item method.
- Be called from within a parallel_for_work_group scope.