Introduction
Intel has been at the forefront of hardware-based server security for confidential computing since 2018 with the introduction of Intel® Software Guard Extensions (Intel® SGX) in the Intel® Xeon® E processors, extending into multi-socket processors with the 3rd generation Intel® Xeon® Scalable processors (formerly code named Ice Lake). With the 4th generation Intel Xeon Scalable processor (formerly code named Sapphire Rapids), Intel introduced Intel® Trust Domain Extensions (Intel® TDX).3 Intel TDX provides a hardware-isolated virtualization-based trusted execution environment (TEE) called Trust Domain (TD) that helps to provide isolation from the host operating system, hypervisor, BIOS, SMM, non-TD software, and platform administrators, which include cloud service providers (CSPs). Intel TDX requires no application modification, which makes application deployment in the TEE straightforward. While Intel TDX on 4th generation Intel Xeon Scalable processors is only available to select CSPs, Intel plans to make this technology broadly available with the 5th generation Intel® Xeon® Scalable processor (code named Emerald Rapids).
Security-Related Performance Considerations
To help protect the private memory and CPU state of the TD from untrusted software, BIOS, and firmware access, Intel TDX relies on the following solutions to aid in ensuring data confidentiality and integrity:
- Intel TDX Transitions: TDX supports a new CPU mode, known as the Secure Arbitration Mode (SEAM), that is used to support Trust Domains. In SEAM a new software module, known as the TDX Module runs that supports the TDX architecture. Like Virtual Machine Extensions (VMX) transitions between the VMM and legacy guests, Intel TDX transitions (that is, TD-exit/TD-entry) between the TDX Module and TDs. However, the CPU state of the TD (that is, general purpose registers, control registers, and MSRs) may contain sensitive data, and so, to prevent any TD CPU state data inference, the Intel TDX module saves a TD's CPU state and scrubs the state when passing control to the VMM. Similarly, when the TD resumes, the state of the TD is restored from the state-save area.3 As shown in Figure 1, with Intel TDX, the VM entry path now additionally includes SEAMCALL—an instruction used by the host VMM to invoke host-side Intel TDX interface functions—and the VM exit path includes SEAMRET—an instruction executed by the TDX module to transfer control back to the VMM. This along with other precautions taken by the Intel TDX module causes Intel TDX transitions to take more time compared to VMX transitions, and thus may cause extra overhead for some workloads inside the TD, particularly those that incur frequent Intel TDX transitions. To reduce the effect of Intel TDX transitions, one could tune software to reduce the Intel TDX transition rates, for example, by using polling mode I/O threads or by reducing timer ticks. To reduce the effect of memory copy overhead and to improve overall I/O performance, Intel will introduce TDX Connect5 in future Intel CPU generations. Please refer to section "Future Performance Enhancements" in this article for more information.
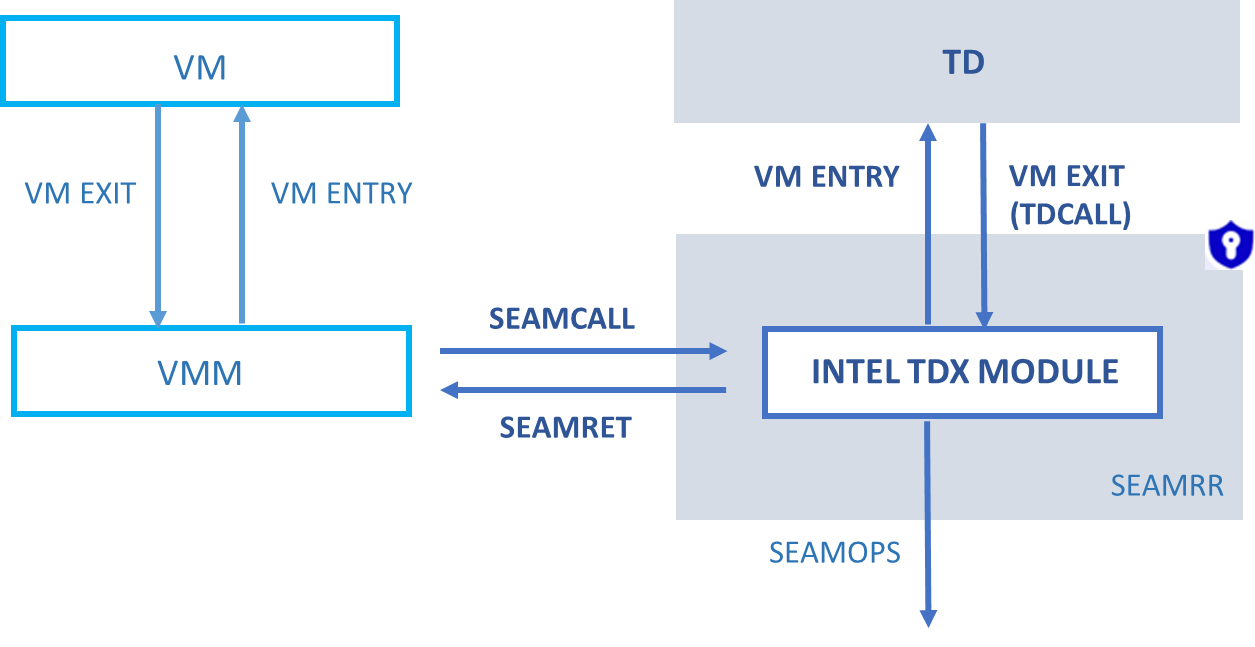
Figure 1. Basic Intel TDX architecture
- Encryption outside the SoC: While data within the SOC (System-on-a-Chip) remains in plain text, any data entering or leaving the SoC is encrypted via two means:
- Memory encryption: Both Intel SGX and TDX are built on top of Intel® Total Memory Encryption – Multi-Key (Intel® TME-MK) which provides multiple ephemeral keys that are hardware generated but inaccessible by software or external interfaces. To support this feature, the processor has an AES-XTS encryption engine in the memory subsystem that encrypts and decrypts data to and from DRAM outside the SoC. A read operation can experience additional latencies depending on the DRAM speed while the overhead in write operations is less apparent due to the write back nature of the CPU cache.
To minimize the impact of memory encryption on non-confidential guests, the SoC supports a feature called Intel TME bypass (TME-bypass), where the memory accesses by the VMM and any other non-TD software bypass the memory encryption flows in the memory subsystem, thereby reducing the latency impacts on read and write operations. Later, when we refer to non-confidential workloads, we will assume that TME-bypass is enabled.
- Inter-socket encryption: Remote memory accesses, made by the CPU accessing memory attached to another socket, go over the Intel® Ultra Path Interconnect (Intel® UPI) connecting the sockets. With Intel SGX and Intel TDX enabled, such remote memory accesses are encrypted over Intel UPI and thus can experience additional latencies. To mitigate these extra latencies, we recommend an optimal platform and software configuration that ensures all the memory accesses are issued to the memory local to the processor or I/O device, in multisocket environments.
- Memory encryption: Both Intel SGX and TDX are built on top of Intel® Total Memory Encryption – Multi-Key (Intel® TME-MK) which provides multiple ephemeral keys that are hardware generated but inaccessible by software or external interfaces. To support this feature, the processor has an AES-XTS encryption engine in the memory subsystem that encrypts and decrypts data to and from DRAM outside the SoC. A read operation can experience additional latencies depending on the DRAM speed while the overhead in write operations is less apparent due to the write back nature of the CPU cache.
- I/O virtualization in Intel TDX: TD's memory contents cannot be accessed by untrusted software, BIOS, and firmware unless the TD explicitly shares a memory range with the untrusted entities, for example, to perform I/O operations or to invoke services of the VMM. That shared memory range is called TD shared memory, in contrast to TD private memory not shared with untrusted software. When the TD exchanges data with emulated devices like virtio device for KVM and vmbus for Hyper-V via TD shared memory, it is the responsibility of the TD to copy data from the shared memory used by devices to TD's private memory used by workloads running inside the TD and vice versa, as shown in Figure 2. This extra memory copy may cause some overhead to I/O intensive workloads that involve a large amount of data exchange with devices. To reduce the effect of memory copy overhead and to improve overall I/O performance, Intel will introduce Intel® Trust Doman Extensions Connect (Intel® TDX Connect)5 in future Intel CPU generations. Please refer to section "Future Performance Enhancements" in this article for more information.
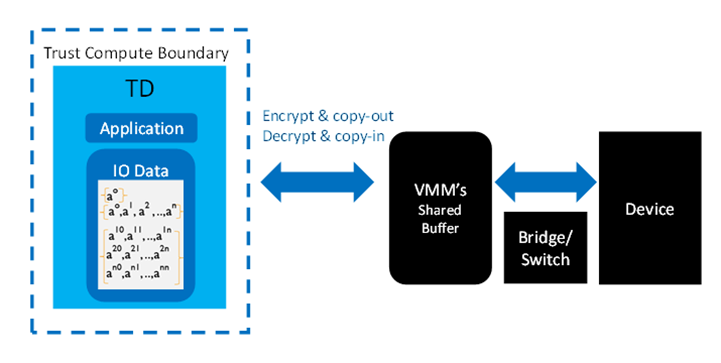
Figure 2. TDX with I/O bounce buffers
Workload Performance
Intel TDX performance varies depending on the workload. In this article, we will describe the performance of Intel TDX for two types of workloads:
- CPU and memory intensive:
- SPECrate 2017 Integer and Floating Point benchmark suite is part of Standard Performance Evaluation Corporation (SPEC) and considered industry standardized benchmarks for integer or floating-point compute intensive performance. Units of operations considered is rate of operations.
- SPECjbb 2015 is another benchmark from the SPEC for measuring performance of Java* application features. Units of operations considered is max-jOPs.
- Shared-memory (SMP) version of Intel® Distribution for LINPACK* Benchmark is a generalization of the LINPACK 1000 benchmark and is a high-performance computing workload. Units of operations considered is Giga floating point operations/sec (Gflops).
- TensorFlow* is an open source software library for machine learning and artificial intelligence. Bidirectional Encoder Representations from Transformers, or BERT is an open source machine learning framework for natural language processing (NLP). Units of operations considered is sentences processed per second.
- I/O intensive:
- Memtier workload issues get/set operations to Redis in-memory key-value store database server. Units of operation is number of get and/or set operations issued per second.
- HammerDB workload issues database queries to a MySQL relational database server with TPROC-C based database. Units of operation is transactions per minute (TPM)
Additionally, we also considered the impact of Intel TDX workloads on other non-TDX workloads on the same CPU package when run simultaneously, which is called the noisy neighbor effect.
In the following sections, we describe the test bed configuration used and Intel TDX performance observed with workloads in different scenarios.
Configuration
System under test for performance assessment is a 4th generation Intel Xeon Scalable processor with two sockets each with 56 cores with hyperthreading and turbo features enabled. CentOS* Stream 8 operating system is installed on the host with kernel 5.15. Guest is configured with 8vCPUs and 32 GB memory, with Ubuntu* 22.04 LTS. Not all the guest and host kernel patches used in these experiments are upstreamed into main line Linux* kernel as of today. For further details please read the "Notices and Disclaimers" section.
For performance reasons, Transparent Huge Pages (THP) are enabled on the host in all scenarios. Guest vCPUs are pinned on individual adjacent cores in the first socket. NUMA (non-uniform memory access) locality is ensured by pinning and allocating guest memory, QEMU I/O Threads, vhosts, device interrupts, and the device on the same first socket as the vCPUs of the guest.
For simplicity and representativeness, we considered a single 8vCPU guest for CPU/memory intensive and I/O intensive workload performance analysis. For the noisy neighbor study, we ran multiple guests on the same socket of the platform in different configurations as described in the "Noisy Neighbor" section.
Performance Results
To comprehend Intel TDX performance in the following sections, we have considered three types of guests:
- Confidential guests also known as Trust Domains (TD).
- Non-confidential guests are traditional guests that run on a platform where Intel TDX and Intel TME bypass is enabled.
- Legacy guests are traditional guests that run on a platform where Intel TDX is not enabled.
And to quantify Intel TDX performance, we consider two delta percentages used in the graphs below:
- Confidential to legacy delta %: Delta % of workload throughput run in a confidential guest versus workload throughput run in a legacy guest, that is (1-TD/LEGACY_VM)%
- Non-confidential to legacy delta %: Delta % of workload throughput run in a non-confidential guest versus workload throughput run in a legacy guest, that is (1-NON_CONFIDENTIAL_VM/LEGACY_VM)%
Workload throughput differential is not the only performance effect of Intel TDX, but CPU utilizations can also increase in the confidential guest case compared to a legacy guest case. To simplify the study, unless otherwise stated, all workloads were run to saturate all the vCPUs of the guest while meeting workload SLA wherever mentioned. And hence in such cases, any additional CPU overheads while running Intel TDX translate into corresponding drop in workload throughput.
For all the cases below each data point is the median of three runs and in cases where performance impacts are too low, we have captured the run-to-run variation percent to demonstrate the noise.
CPU/Memory Intensive Workloads
With CPU/memory intensive workloads, we tend to observe up to 5% performance difference with confidential guests as shown in Figure 3. For example, as shown in Figure 3, SPECrate* 2017 Integer and SPECrate 2017 floating point (FP) experience 3% performance drop, while SPC JBB (a memory latency sensitive workload) performance drops up to 4.5%. Similarly, we observe a throughput drop of 2.77% with HPC workload LINPACK and 3.81% with AI workload TensorFlow BERT.
The difference in performance shown in Figure 3 can be attributed to memory encryption and Intel TDX transitions due to local APIC timer interrupts in the guest. Performance impact from the timer ticks can be reduced further by some guest-level tunings like reducing its frequency via editing the kernel configuration or reducing host scheduling clock ticks via NO_HZ in Linux to reduce host timer interrupt related Intel TDX transitions for the TD guest.
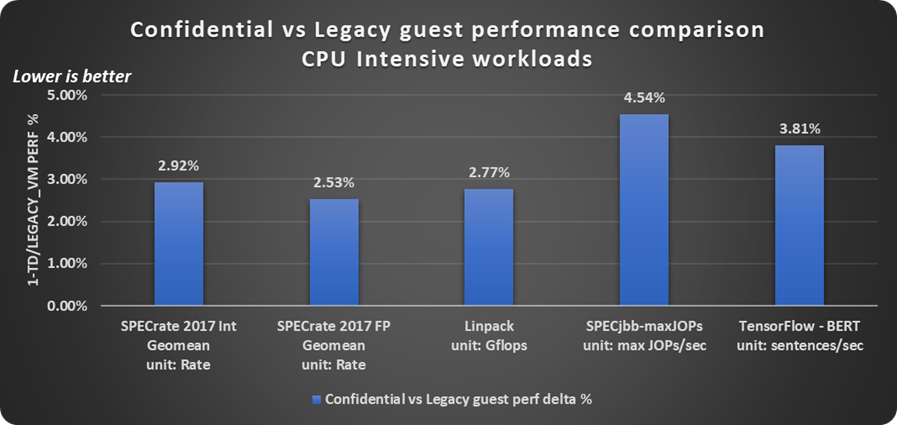
Figure 3. Confidential versus legacy guest performance comparison with CPU and memory intensive workloads
Non-confidential guests have a minimal impact on the workload throughput and are mostly within the noise of run-to-run variation of the workload as shown in Figure 4.
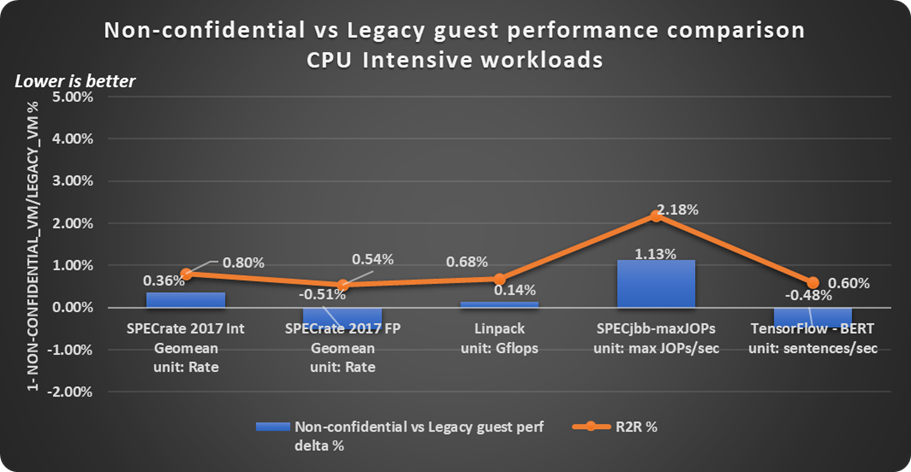
Figure 4. Non-confidential versus legacy guest performance comparison with CPU and memory intensive workloads
I/O Intensive Workloads
For I/O intensive workloads generally, we observe that the workloads with a higher number of I/O transactions and bytes of data transfer rate, experience lower Intel TDX performance. This is expected due to the increased number of Intel TDX transitions and the use of bounce-buffers outside the Intel TDX protected memory space.
With HammerDB workload, note that the Microsoft MySQL* database server was run suboptimally to capture the worst-case performance impact of Intel TDX by setting up a 50 GB database with only 5 GB for InnoDB buffer size in a 32 GB guest memory. As a result, this causes more disk operations to be issued than optimal configurations where larger buffer sizes are allocated for the database server. HammerDB virtual users were tuned to drive all the vCPUs of the guest to near CPU saturation, with an observed disk I/O bandwidth of ~130 megabytes/sec. Given that the vCPUs of both the legacy and confidential guests are operating at near 100% utilization, performance impact on confidential guests observed is 9.3%, as shown in Figure 5. If the workload is configured more optimally, then the performance overheads observed are expected to be lower.
Below data point of the Redis server with memtier workload was run with 2:8 get:set ratio where only 1 memtier instance was used to drive requests to the Redis server in both confidential and legacy guest cases, with 1k datagram size and pipeline of 64. While the legacy guest is not CPU saturated with this workload request command, the confidential guest is, thereby leading to an additional impact on workload throughout performance of 7.4% as shown in Figure 5. Redis-memtier workload is network I/O intensive with an observed network bandwidth >25 Gbps in this case.
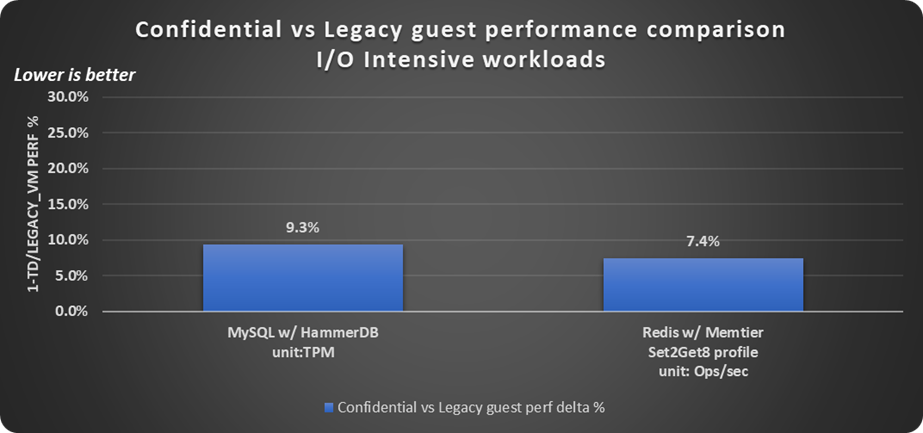
Figure 5. Confidential versus legacy guest performance comparison with I/O intensive workloads.
As stated before, depending on your workloads and their rate of I/O operations, the performance impact of Intel TDX may be heightened, due to corresponding increase in Intel TDX transitions, and that of data transfer rate copied back and forth between private and shared memory thereby increasing corresponding CPU overheads. And, to demonstrate this point, as shown below in Figure 6, Redis-memtier is run with multiple configurations:
- 100% get and 0% set operations with single memtier client thread: Throughput effect is only 3.6% when vCPU in TD has nearly enough headroom of additional 20% to accommodate Intel TDX related CPU overhead.
- 80% get and 20% set operations with single memtier client thread: Described previously, where TD vCPUs did not have enough headroom to accommodate Intel TDX related CPU overhead for I/O operations, leading to vCPU util% increase of 10% and another additional workload throughput drop of 7.4%.
- 0% get and 100% set operations with single memtier client thread: In this case legacy VM vCPUs were already saturated, leaving no CPU headroom in the TD guest for Intel TDX related overhead leading to a higher throughput drop of 25%.
- 80% get and 20% set operations with two memtier client threads: With higher client request rate than previous cases, legacy VM ran at CPU saturation, leaving no CPU headroom in the TD guest for Intel TDX related overhead leading to a higher throughput drop than before. As expected network bandwidth is higher in this case vs previous ones where only a single memtier thread drives requests to Redis server, i.e., around 40 Gbps vs 30 Gbps.
In all cases mentioned here Redis was run to meet the SLA requirements of <1 ms latency per operation.
In some cases, host related CPU utilizations can also be higher due to Intel TDX; for example, when KVM needs to invoke SEAMCALL to check if there are any pending interrupts when emulating HLT instruction executed by TDs. Since well-tuned guests and workloads are not supposed to incur frequent HLT exits, this overhead in most cases should be negligible. However to address an observed impact, one could change the workload and guest configuration to saturate TD vCPUs, or enable guest halt polling.4
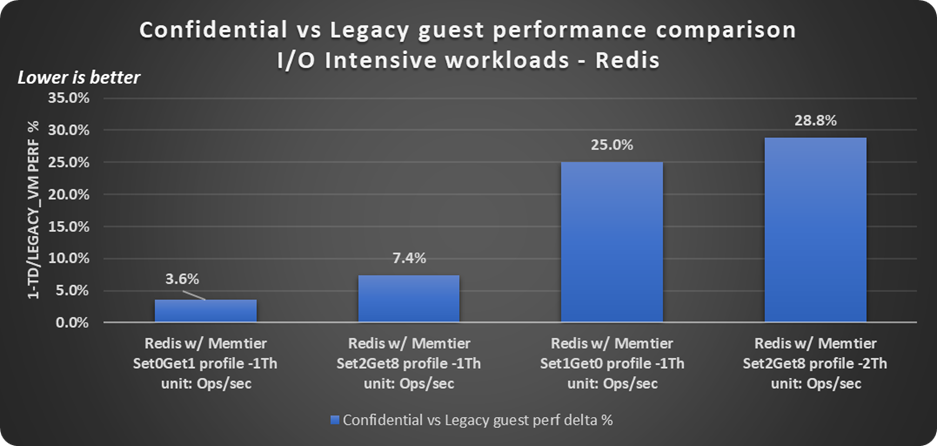
Figure 6. Confidential versus legacy guest performance comparison with Redis and memtier.
Non-confidential guests have a minimal impact on the workload throughput and are mostly within the noise of run-to-run variation of the workload as shown in Figure 7.
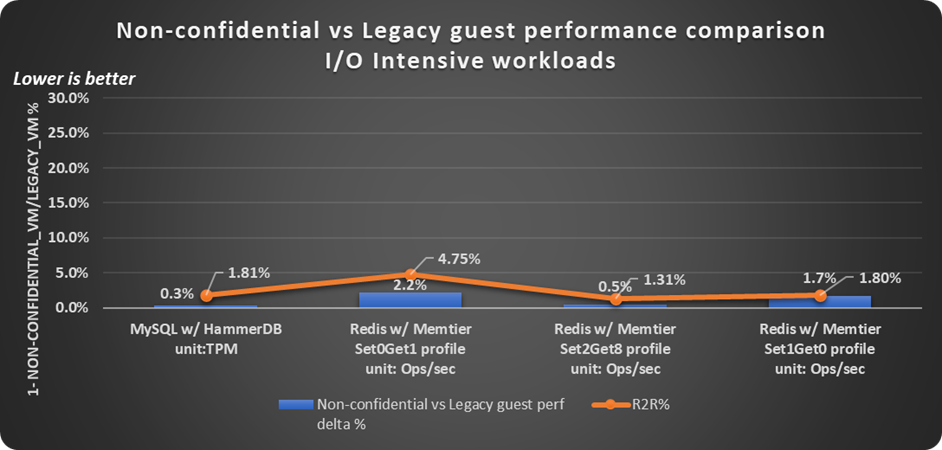
Figure 7. Non-confidential versus legacy guest performance comparison with I/O intensive workloads
Note that this article does not account for performance overheads from application or driver-level security protocols, which are recommended for end-to-end data security with first-generation Intel TDX on 4th generation Intel Xeon Scalable processors.
Noisy Neighbor
When running workloads simultaneously on the same CPU socket, accesses by one workload can inadvertently affect the performance of another workload. This is known as the noisy neighbor impact. Ideally, we want this noise to be as minimal as possible, and our work shows that confidential guests have minimal noisy neighbor impact on non-confidential guest performance. To comprehend the noise, the following study was conducted.
On a platform running multiple guests, for optimal performance and to meet predefined service level agreements (SLA), a minimum number of CPUs should be reserved for the host to handle virtualization and system level operations in order to prevent any resource contention with the guests running on the platform. For this experiment, 15% CPU resources of the platform were reserved for the host operations, while the remaining 85% of the CPUs were distributed evenly amongst guests.
Hence, on a 56-core Intel Xeon Scalable processor, we reserved 8 cores for the host and evenly distributed 48 cores between 6 of the 8vCPU guests. With 512 GB total memory in the platform, and each guest configured with 32 GB memory, the host has enough memory to operate.
To study the noise, we use the workload SPECrate CPU 2017 and consider the following three cases as shown in Figure 8:
- Case 1: Workload throughput of first non-confidential guest, when all six guests on the platform are non-confidential.
- Case 2: Workload throughput of first non-confidential guest, when remaining five guests on the platform are confidential TDs.
- Case 3: Average of the workload throughput of first two non-confidential guests, when remaining four guests on the platform are confidential TDs.
While there are several ways to conduct this study and quantify noise, we considered the following ratios to simplify our analysis:
- Single guest delta %: Delta % of workload throughput of first non-confidential guest in case 2 versus workload throughput of first non-confidential guest in Case 1.
- Two guest delta %: Delta % of average workload throughput of first and second non-confidential guests in Case 3 versus average workload throughput of first and second non-confidential guests in Case 1.

Figure 8. TD and VM guest distribution in a CPU socket
The noise effect of multiple TDs on single non-confidential guest when run with SPECrate CPU 2017 (VM Perf impact % as shown in the Figure 9) was found to be within run-to-run noise of first non-confidential guest's performance (VM1 R2R), and average of all non-confidential guest performance on the platform (VM R2R).
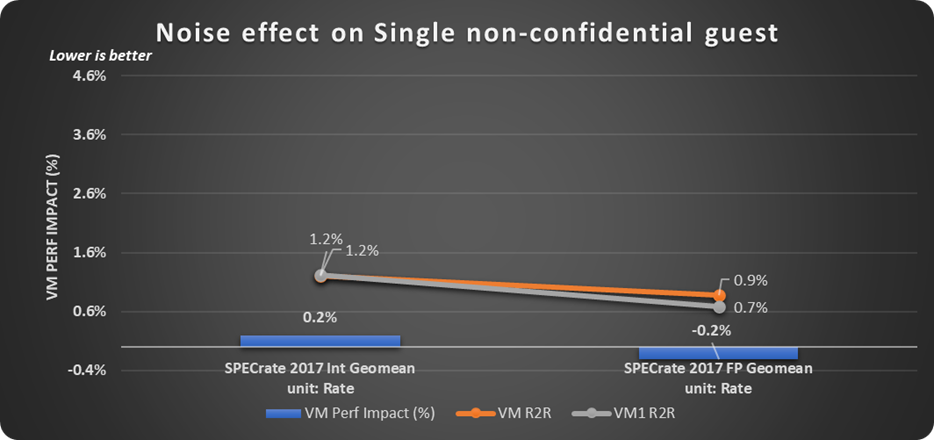
Figure 9. Noise effect of TDs on a single non-confidential guest
Similarly, the noise effect of multiple TDs on two non-confidential guests when run with a SPECrate CPU 2017 (VM PERF IMPACT is shown in Figure 10) was found to be within run-to-run noise of average of first and second non-confidential guests' performance (VM1_VM2 R2R), and that of an average of all non-confidential guest performance on the platform (VM R2R).
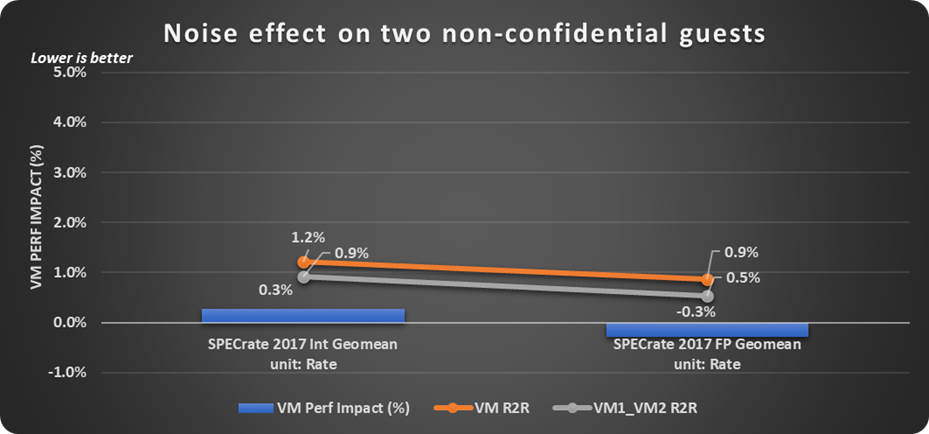
Figure 10: Noise effect of TDs on two confidential guests
Future Performance Enhancements
Intel continues to work with operating system vendors, CSPs, and the open source community to continually improve the performance of Intel TDX. On the hardware front, Intel has announced Intel® Trust Doman Extensions Connect (Intel® TDX Connect), which enables trusted devices to access TDX-protected memory directly as shown in Figure 11, thereby improving TDX performance related to I/O. With Intel TDX Connect, both performance overheads due to memory copying between shared and private memory and, TDX transitions are minimized. Additionally, since Intel TDX Connect is built on top of Intel® Virtualization Technology (Intel® VT) for Directed I/O (Intel® VT-d), any performance overheads due to software-based paravirtual devices could also be replaced with efficient direct device I/O transfer of data from the trusted device to TD private memory.5
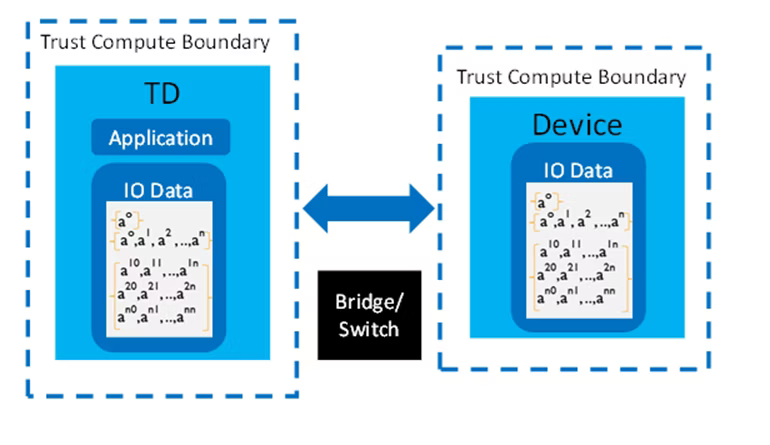
Figure 11: TDX Connect data transfer
Conclusion
With Intel Trust Domain Extensions introduced in 4th generation Intel Xeon Scalable processors, Intel made a giant leap in progressing confidential computing and anticipating customer end-to-end security needs. Intel TDX relies on features like Intel TDX transitions, data encryption outside SoC via memory and UPI encryption and I/O virtualization related shared versus private memory isolation, which may have some effects on performance of workloads. Based on various studies, while we conclude that the performance impact depends on the nature of the workload, we generally observe about 5% performance effect of Intel TDX on CPU and memory intensive workloads and varying but higher range for I/O intensive workloads. The performance effect of Intel TDX on non-confidential guests and the noise of TDs on non-confidential guest workload throughput are observed to be minimal and within run-to-run throughput variation of the workload, when run with TME-Bypass enabled. While software optimizations can help mitigate performance effect of Intel TDX enabled workload throughput, with Intel TDX-Connect in the future, Intel hopes to improve Intel TDX performance for I/O intensive workloads with trusted devices.
References
5. Intel TDX Connect White Paper
Notices and Disclaimers
Code names are used by Intel to identify products, technologies, or services that are in development and not publicly available. These are not "commercial" names and not intended to function as trademarks.
Performance varies by use, configuration and other factors. Learn more on the Performance Index site. Real world performance impacts may vary, and any stated figures herein are estimates.
For workloads and configurations, see the following resource. Results may vary.
Configurations:
- Systems under test:
- Host Platinum 8481C: 1-node, 2x Intel Xeon Platinum 8481C processor on a Reference Platform from Intel (formerly code named Archer City) with 512 GB (16 slots/ 32GB/ 4800) total DDR5 memory, ucode X2b000161, HT on, Turbo on, HugePages enabled, CentOS Stream 8, 5.19.0-tdx.v1.11.mvp 11.el8.x86_64, 1x INTEL SSDSC2KG960G7, 2x Ethernet Controller E810-C for QSFP (100G), test by Intel on December 16, 2022.
- Confidential and non-confidential guest scenario BIOS settings: TME ON, TME-MT ON, TME bypass ON, SGX ON, TDX ON, TDX SEAM Loader Enabled.
- Legacy guest scenario BIOS settings: TME OFF, TME-MT OFF, TME bypass OFF, SGX OFF, TDX OFF.
- Guest 8vCPUs pinned to cores 20-27, 32 GB total memory, Ubuntu 22.04.1 LTS, 5.19.0-mvp10v1+11-generic, MVP-QEMU-7.0-v1.2, HugePages off, Disk 120GB, test by Intel on 12/16/2022. TD launched with launchsecuritytype = ‘tdx’
- Host Platinum 8481C: 1-node, 2x Intel Xeon Platinum 8481C processor on a Reference Platform from Intel (formerly code named Archer City) with 512 GB (16 slots/ 32GB/ 4800) total DDR5 memory, ucode X2b000161, HT on, Turbo on, HugePages enabled, CentOS Stream 8, 5.19.0-tdx.v1.11.mvp 11.el8.x86_64, 1x INTEL SSDSC2KG960G7, 2x Ethernet Controller E810-C for QSFP (100G), test by Intel on December 16, 2022.
- Workload Client platform:
- Platinum 8280: 1-node, 2x Intel Xeon Platinum 8280 processor on Intel Reference Platform (Wilson City) with 384 GB (12 slots/ 32GB/ 2934) total DDR4 memory, ucode X4003302, HT on, Turbo on, HugePages enabled, Ubuntu 20.04.4 LTS, 5.4.0-146-generic, 1x INTEL SSDSC2KG960G7, 2x Ethernet Controller E810-C for QSFP (100G), test by Intel on December 16, 2022.
- Workload version: SPECcpu17rate gcc 12.1 O2 config, SpecJBB2015: JAVA- jdk18.0.2.1, LINPACK: l_mklb_p_2018.2.010, Redis: server v=6.0.16, memtier_benchmark 1.3.0, HammerDB-MySQL: mysql-community- common-8.0.26-1.el7, HammerDB-4.3-Linux
- HammerDB for MySQL (TPROC-C): HammerDB is the leading benchmarking and load testing software for the world’s most popular databases supporting the Oracle* database, Microsoft SQL Server*, IBM* Db2, PostgreSQL*, MySQL, and MariaDB*. https://github.com/TPC-Council/HammerDB. TPROC-C is derived from TPC-C https://www.hammerdb.com/docs/ch03.html
- Redis and Memtier: Redis is an open source (BSD licensed), in-memory data structure store used as a database, cache, message broker, and streaming engine. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. Memtier_benchmark is a command-line utility developed by Redis Labs (formerly Garantia Data Ltd.) for load generation and benchmarking NoSQL key-value databases. https://github.com/RedisLabs/memtier_benchmark
- LINPACK: Intel distribution of LINPACK benchmark shared memory version is used for our analysis. As per the LINPACK definition, "Shared-memory (SMP) version of Intel® Distribution for LINPACK Benchmark is a generalization of the LINPACK 1000 benchmark which solves a dense (real*8) system of linear equations (Ax=b), measures the amount of time it takes to factor and solve the system, converts that time into a performance rate and tests the results for accuracy."
https://www.intel.com/content/www/us/en/developer/articles/technical/onemkl-benchmarks-suite.html
- SPECint / SPECfp Rate: This exercise used only for Rate benchmarks.
"Designed to provide performance measurements that can be used to compare compute-intensive workloads on different computer systems, SPEC CPU 2017 contains 43 benchmarks organized into four suites: SPECspeed 2017 Integer, SPECspeed 2017 Floating Point, SPECrate 2017 Integer, and SPECrate 2017 Floating Point. SPEC CPU 2017 also includes an optional metric for measuring energy consumption." Compiler GCC v9.1.
https://www.spec.org/products/
https://www.spec.org/cpu2017/Docs/overview.html#suites - SPECjbb: "The SPECjbb* 2015 benchmark has been developed from the ground up to measure performance based on the latest Java application features. It is relevant to all audiences who are interested in Java server performance, including JVM vendors, hardware developers, Java application developers, researchers and members of the academic community. Benchmark components: The benchmark consists of following three components:
A. Controller (Ctr): Controller directs the execution of the workload. There is always one controller.
B. Transaction Injectors (TxI): The TxI issues requests and services to back end(s) as directed by the Controller and measures end-to-end response time for issued requests.
C. Back ends: Back end contains business logic code that processes requests and services from TxI and notifies the TxI that a request has been processed." https://www.spec.org/jbb2015/
- TensorFlow: "TensorFlow is a free and open source software library for machine learning and artificial intelligence." And Bidirectional Encoder Representations from Transformers "BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pretrained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications."
https://github.com/intel/ai-reference-models/tree/main/benchmarks
with dataset SQuAD: https://github.com/intel/ai-reference-models/blob/main/datasets/bert_data/README.md#inference