
This is part 2 of a two-part series on the theory and practice of software testing. In part 1 I discussed how to think about testing in terms of expected normal states, expected abnormal states and faults, and the entirely unexpected. In this post, I will elaborate on the practical tools of testing, and how they interact with reaching the various parts of the system state space.
Intermission: Poor Testing can be an Embarrassment
But first, something completely different.
I saw a perfect example of embarrassingly sloppy testing work recently. Visting an upscale mall in Stockholm, we noticed an ambitious-looking live video ad on some of their big display screens. The ad was counting down to the start of the new season of a television show called “Gladiatorerna”. This countdown appeared to work well enough – every so often the ad would be shown in the rotation, and each time the clock would have counted down towards zero (which was 20.00 CET). Seemed competently done.
Then the clock turned to 20.00… and the ad came up again. With a somewhat interesting concept of how much time there was left:

Oops. The numbers went negative, and in a way that is hard to make sense of. Clearly, there is some kind of display code that turns “about 2 minutes past the countdown target” into “minus 1 hour, minus 2 minutes, 28 seconds”. That’s a bug right there.
That this was shown at all must mean that nobody ever tested what happened beyond the end of the countdown – which is a rather embarrassing oversight for what is obviously a high-visibility campaign for a prime-time show in one of the leading television networks in Sweden. Maybe someone assumed that it wouldn’t be shown past 20.00? Still… testing what happens beyond the end of the countdown is an obvious thing to do and should fall inside the green box of the expected state as I see it… it is not like the clock has suddenly gone from 2017 to 1867 or whatever. But here, it fell into the red area of unexpected states. With an unexpected and not entirely satisfactory outcome.
Don’t let this happen to your code.
Random Testing
In the previous post, I discussed how creative testers can expand test coverage and bring more possibilities into the set of expected – and thus properly handled – states. In addition to smart people, we can use smart tools in smart ways to expand testing. In particular, test generation based on some kind of randomness.
Even the most elite testers like the Black Team have their limits, and while they expand on the yellow box, the red box is by definition beyond even them. That’s when we turn to test generation, randomness, and fuzzing. Such testing essentially boils down to setting up rules for how to generate tests, having a machine generate the tests, and then subject the system to these tests – no matter how nonsensical they would seem to a human.
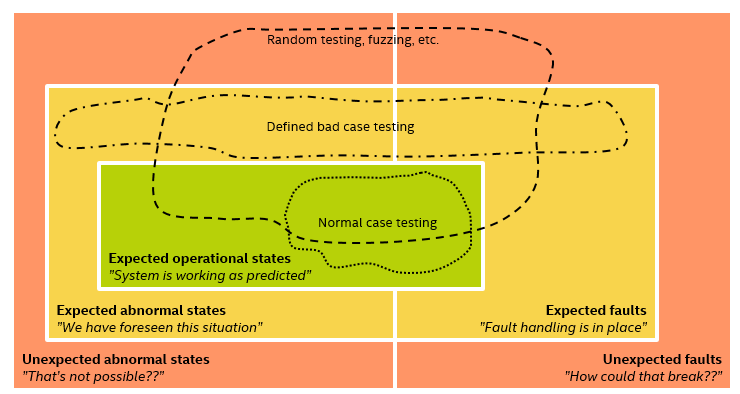
As shown in the picture above, random testing or fuzzing will typically generate tests all over the place – including inside the normal operation of a system. It will thus expand on the tests for all kinds of states. Most importantly, it will explore outside the box of expected states entirely, since humans are not directly involved in test generation.
In practice, fuzzing has proven to be an incredibly valuable tool for testing. I read a lot about how security breaches happen, and it is very common to see randomly generated input data (web requests, media files, network packets) being the tool that finds the cracks in a system that can be used to get a toe-hold. When used correctly, fuzzing creates input data and event sequences that a human would not consider or imagine – which is exactly what you want in order to plug the holes left open by the limits of human imagination.
Philosophically speaking, what I think is going on here is that it is easier to set up rules that will generate unexpected behaviors, than to generate the same behaviors directly. By using rules with randomness, we give our brains some leverage to generate something new.
Test Systems
There is one more aspect of testing that is often forgotten, and that is how the available test systems limit what kinds of tests can (and thus will) be run. In practice, if you do not have a test system that can get the system to a certain state or inject a certain input, you cannot test that state or input.
Practical test execution is limited to the expressive power of available test systems. We end up testing what we can test rather than what we want to test – there is often a wish-list of things you know you would like to test, but just cannot implement on the existing test systems and infrastructure.
The situation is essentially this (exaggerated to make the point clear):
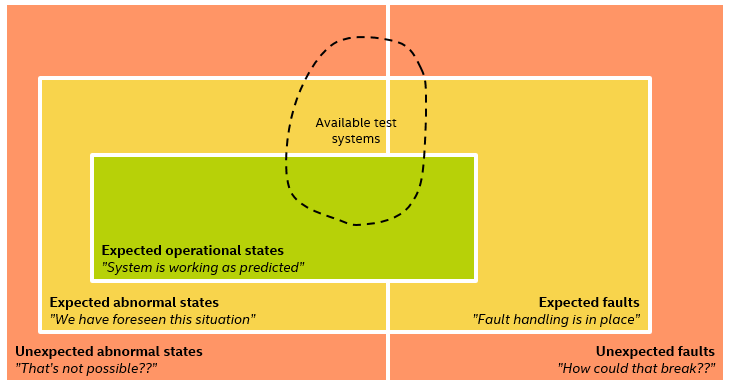
If we combine this insight with the previous illustration of the different test cases available to us, we realize that testing will only cover the intersection of the available test cases and test execution systems. Not all tests that we can imagine can necessarily be implemented given the constraints of the test systems we have available, and there will be cases that the test systems could exercise but where no tests were created.
For example, to take a really simple example, we might want to test the scaling and behavior of a parallel algorithm over a large range of processor core counts. However, such testing will be limited to the core counts present on the test systems available to us. We cannot expect to be able to procure all possible types of systems – and thus there will always be some users running the software on an untested core count.
In order to expand testing to cover more different cases, we need to innovate not just in terms of how we come up with test cases, but also in how we run the tests. In the embedded systems world, and in particular in the aerospace world, this is something where a lot of effort is typically spent. The physical test rig I talked about in my blog post about the Schiaparelli lander is fairly typical of the effort that is needed to run such tests – large specialized machines that expand testing beyond the easy case of a stationary system, into the realm of shaking and moving.
This is where computer system simulation comes in as a powerful test execution platform – both to test normal states that might not be available in physical form, to test abnormal situations that cannot be achieved in hardware, and to inject faults into the hardware. The use of simulation expands the area that can be covered by tests in my diagram, along these lines:
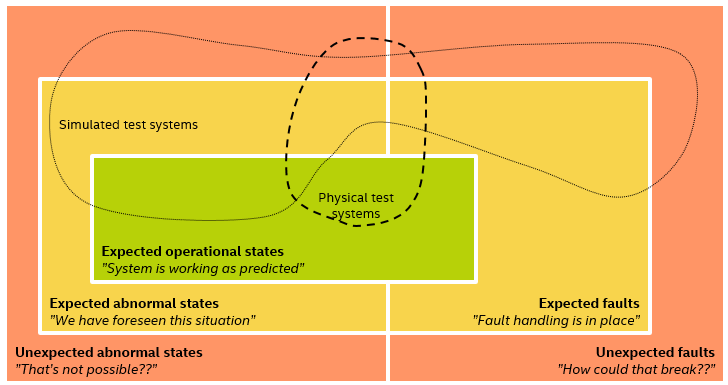
Note that simulation does not necessarily provide a superset of the tests afforded by the physical test systems – after all, there are some things that can only be tested on hardware since they are not represented in the simulation.
For an idea for what simulation can do, here are some links to previous articles on the matter:
- A Xen bug related to how it checks features in Intel® Memory Protection Extensions (Intel® MPX), which also mentions some other examples of bugs that was only evident when the execution platform changed.
- Testing IoT systems at node count scales not available in hardware, or with ridiculously large memories.
- Injecting hardware events into a system to test operating system robustness
- Hardware-level fault injection using Simics, to test software behavior in the presence of faulty hardware
- A Wind River white paper on security testing using simulation
Disclaimer: remember that final testing on physical hardware is always needed. You have to test what you fly and fly what you test. Simulation will help you test more and build more robust systems, but it never replaces testing on physical systems entirely.
Acknowledgements
I must say a big thanks to Richard Osibanjo in the Evangelists team who inspired me to draw a diagram of my thoughts on testing… which turned into quite a few diagrams and a plethora of words.