
A recent blog post I wrote about the ESA Schiaparelli crash, triggered a discussion about testing, execution tools for testing, and the right mindset for testing. If you look back at what I have written in the past on this blog and the Wind River blog, there is a recurring theme of expanding testing beyond the obvious and testing what cannot be easily tested in the real world (by using simulation). In this two-part series of blog posts about testing theory, I will attempt to summarize my thoughts on testing, and share some anecdotes along the way.
This is part 1, and you can find part 2 here.
The Testing Landscape
In general, the software in a computer system (including cars, aircraft, robots, servers, laptops, rockets, toasters, mobile phones and nuclear power plants) is designed to work assuming certain situations, inputs, states, and environmental conditions. Software testing tends to focus on showing that the software works as advertised and that it gives the right results for expected and well-formed inputs within the design space of the system.
Expected and well-formed inputs can mean valid commands in a command-line interface, reasonable values to a computational function, sensor values within expected bounds in a control systems, network packets following the format specified by a protocol, clicks in the right order in a GUI, et cetera. Most of the time, this is where programmers focus their efforts, to make sure the software does the right thing and performs as expected. After all, if the software does not perform the task it was built to do, it has little value to anyone.
Beyond the space of expected inputs, we enter into the realm of invalid or abnormal states and inputs. Software really must handle such states too, in a graceful manner. That’s why we get syntax error messages from a compiler and not just random garbage binaries. If you are told to enter your age on a web form, and enter letters, you rightfully expect the system to give you an error message rather than accept that you age is “none of your business” or “ABC”. Error handling is a key part of software development, or at least it should be.
The abnormal states can be divided into two parts as I see it: abnormal values that happen in an otherwise functioning system, and faults where something is decidedly broken. For example, if you design a control system for an airplane that is supposed to go no faster than 500 km/h, but the plane manages to exceed that in a deep dive, you have an abnormal situation - but the system as such is still intact. If instead the speed sensing system breaks down and starts to report random values that have nothing to do with the actual state of the system, you have a fault.
While both situations are anomalous or abnormal, they need to be dealt with in different ways. Abnormal states reflect an actual state of the system, and the algorithms have to be extended to cover such cases in a graceful way. The world is a tough place, and the system has to deal with it. Faults, in the other hand, require paranoid logic that can detect that there are faults in the system. When faults are detected, fallback strategies have to be used that do not depend on the faulty component. In many cases, dealing with faults comes down to physical redundancy and using multiple different sensors to detect if any one sensor develops a fault.
In summary, here is how I have come to think of the space of states that a software system can encounter, with a typical statement from an engineer when they see the system operating in the given state:
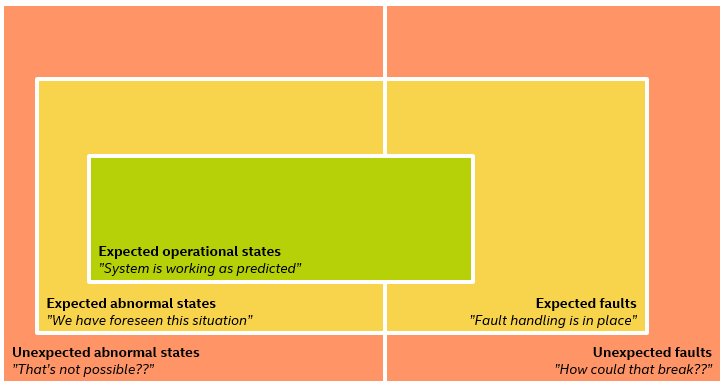
The innermost green box represents the set of states that the system was designed to deal with. The expected inputs, the well-formed programs, the normal operational states of a control system, the designed speed of an aircraft, etc.
The yellow box represents the expected abnormal states and expected faults. For these cases, there should be logic in place that can deal with the situation in a reasonably safe way. For the expected abnormal states, the situations is foreseen and we know that the software is still going to work – even if working means printing an error message. This is the space that is handled by typical error handling in software. For the expected faults, I can hear a programmer confidently telling their users that “yes, we were already aware that such things can break, and the software is designed to work even in the presence of a fault”.
Outside of the yellow box, we have the red box. This covers the unexpected abnormal states and unexpected faults, where we get into uncharted territory. We sailed off of the edge of the map, and we cannot predict what is going to happen next. Since by definition nobody thought of these situations, what happens will be hit-and-miss. In the best software (or just plain lucky software), such situations are handled gracefully by good limiters and logic and consistent design that behaves in a linear fashion even far outside of the designed state. Good “catch all” systems are very helpful – provided you do something that does bring the system to a safe state. There is a high likelihood that bad things will happen, however, as illustrated by countless examples over the years.
Creative Testing
Given this testing landscape, we can classify the tests we define for a system into the following categories:
- Tests that test the normal operation
- Tests for expected abnormal situations and expected faults, as imagined by the system designers
- Tests for the unexpected, beyond the imagination of the designers
However, can tests for the unexpected actually exist? After all, if we have a test for it, it falls within the imagined and expected. I will come back to the issue of testing for the unexpected in part 2 of this series.
Going back to the realm of the expected, the critical skill of a good tester is to be very imaginative and creative in terms of what a system could be subjected to. As tests are created, run, and most likely fail, developers will fix the software. This process should make the software better, in effect increasing the robustness of the system by breaking it.
A good tester thus has the effect of expanding the set of “expected abnormal” and “expected fault” states, increasing system reliability and the set of states and faults where we can feel confident in the system behavior. It also means that the set of unexpected states gets reduced, as illustrated below:
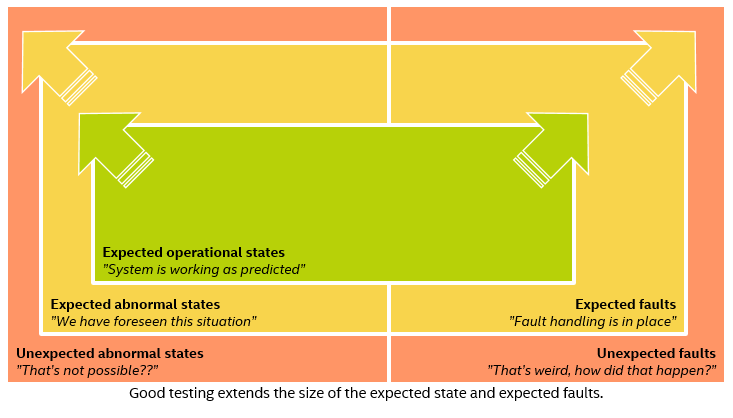
Ideally, the red box gets eliminated – but I wonder if that is realistic for a real system operating in the real world. Experience has told us that the world is terribly inventive in coming up with new situations. As sometimes said, if you think your software is fool-proof, you just have not found the right fool yet.
Let me tell a story about creative testing from annals of the history of computing.
The Black Team
I think that a good tester thinks like a hacker –looking for the ways that a system can break, finding the cracks that can be leveraged into breakage. We can expect a programmer to do a decent job of testing the normal operation of a system and how it works – that is part of the regular quick development tests. As stated above, the job of a tester is to push beyond the obvious cases where things work into the states the programmer might not have thought too much about – and bring that into the testing regime.
There was a legendary test group at IBM in the 1960’s called the Black Team that I think embodies the epitomy of creative testing. IBM was very concerned about the quality of their software, and put their best testers into a team with the idea that talented people working together can have a tremendous effect on the effectiveness. They succeeded beyond their dreams!
From http://t3.org/tangledwebs/07/tw0706.html:
“…and they began to view their jobs not as testing software, but as breaking software. Team members took a well-deserved pride in their abilities and began to cultivate an image of villainous destroyers. As a group, they began coming to work dressed in black and took to calling themselves "The Black Team."”
The Black Team got so good at testing code that programmers were scared of them – and this in turn led to a dramatic increase in code quality. Since the programmers knew that sloppy work would be detected, they were tougher on themselves and their code
Torturing software, like these individuals did, is an art that we still need. Especially when we consider the pervasiveness of software in our lives and the very concrete threats posed by security flaws, hacking into systems, and safety-critical control software.
Anyway.
This is the end of part 1. In part 2, I will look at some more practical aspects of testing, and how the nature and availability of tools and systems affect the testing effort.