SYCL* is a programming model based on open standards and C++ that heralds the arrival of a new age of heterogeneous compute. With SYCL, you can seamlessly integrate your code across diverse hardware architectures and achieve the best mix of computational capabilities for your workload.
At Intel® Innovation 2022, the story of SYCL was delivered from the unique perspective of Andrew Richards, CEO of Codeplay Software Ltd. In this short blog, I’m leveraging his point of view to help illustrate the history and motivation behind SYCL and, more importantly, how it applies to you.
How It All Started
Like so many things in modern software development, it all started from a passion for video game development. Video game developers loved using ever more powerful processors because they enabled incredible and fun things in terms of graphics.
This very quickly evolved to a point where the programming methods used in video games were actually so powerful, you could build supercomputers or self-driving cars using them.
As the compute power of gaming machines and computers (as well as GPUs) increased, it became ever more challenging to tweak games and write all of the advanced physics engines underpinning modern games in a reasonable amount of time. Time-to-market suddenly turned into a pain point.
So what did developers do? They started to experiment, using and abusing C++ to the fullest possible extent.
It turned out that C++ has many inherent properties that make it very suitable for writing highly parallel high-performance software. Developers and researches in science and artificial intelligence started stumbling into the same kind of problems and pursuing similar or even identical C++ based solutions.
Codeplay’s and Intel’s interest is in bringing these new C++ techniques to the mainstream. And to do that, we needed to support a wider range of hardware along with a wide range of workloads. Additionally, the solution needed to be very easy to use, have community support, and be well documented.
SYCL and The Khronos Group*
The best way to do this was to define a standard within The Khronos Group*. We weren't sure whether it was going to end up as big as it did. But indeed, the industry and academia started adopting it at scale.
Watch Andrew Richards describe the journey towards open-standards-based heterogenous compute and the creation of SYCL in his own words:
Once the adoption of SYCL started, we experimented with more and more codebases. We realized modern software is written with so many different library routines—we not only have to consider C++, but also all the standard library packages that modern software consumes.
That realization implied that we had to stick to standard languages and ensure API compatibility across the board. We became convinced that the answer was to define an industry standard, which would allow developers to write code once and then distribute it across their entire set of compute configurations.
The oneAPI programming model was born.
When you're looking at extending existing languages instead of inventing your own, you have to ask, what value are you adding?
So What is SYCL?
It is a C++ programing model. A SYCL program is an entirely legal C++ program, but it is also designed to target heterogeneous architectures. With SYCL, a mixture of CPUs and GPUs and other processing units can work seamlessly together taking advantage of a wide range of architectures.
What Does SYCL Mean for You?
If you write code in SYCL, your code will be entirely based on industry standards. It is industry standard C++ with the additional freedom of choice to run on any hardware that you want.
The SYCL standard is being adopted by a wide ecosystem of software solution providers and silicon vendors as well as high performance computing centers of excellence. This is depicted in Figure 1 below. Already a very diverse set of hardware is being targeted with the number of supported platforms continuing to grow.
The freedom to target the combination of hardware you choose with a common programming model is real.
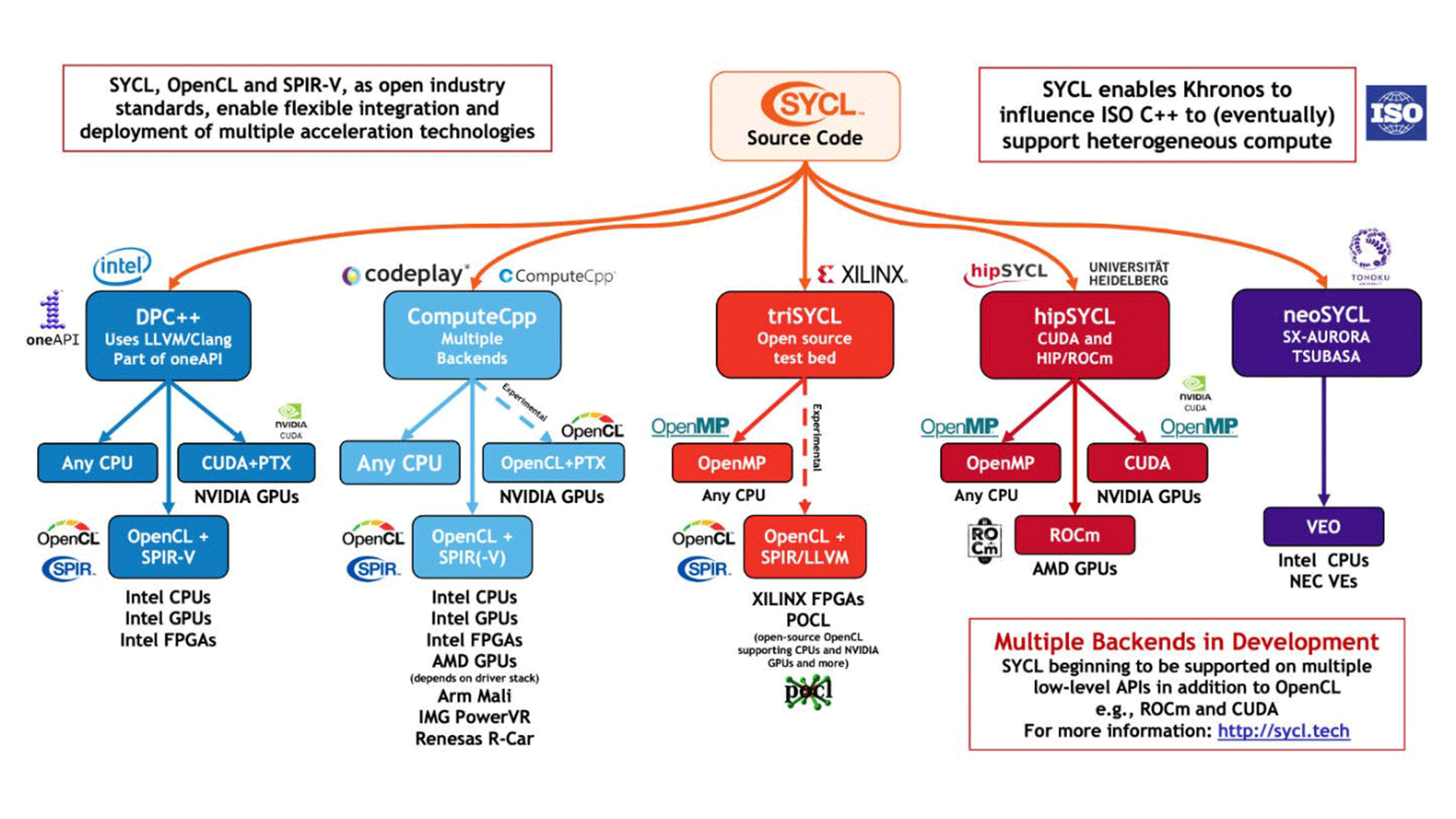
Figure 1. SYCL Implementations Targeting Multiple Backends
Open Standards Simplify Development
oneAPI’s open-industry standards-based approach to compute on CPUs, GPUs, FPGAs, and other devices enables a straightforward programming model with ongoing input from the developer community.
The open source DPC++ compiler project, which is implementing SYCL in LLVM*, takes advantage of this new flexibility to support GPUs from a variety of vendors. Thus, SYCL delivers on being truly open for cross-architecture and cross-vendor software development.
As a result, SYCL gains the broad perspective needed to find answers in a clear and consistent way for the 2 key questions of heterogeneous compute:
- Does a program know which accelerators are available on a system?
When a program starts up, how does it find out what accelerators are available on the system it is running on? Wouldn’t it be great if, as a next step, a program could adjust to the runtime environment it encounters.
The idea is that the available devices are being recognized and enumerated at startup. All you may need in this forward-looking scenario are additional custom libraries targeting the hardware vendor of your choice. Ideally, they can even be available as part of the SYCL and oneAPI framework.
Already today, a C++ program itself is flexible enough to incorporate possible offload queues into a variety of platforms. As long as the SYCL-based program encompasses the available hardware platforms of your choice, they can then be automatically called. Thus the program can take advantage of platforms from Intel, AMD, Nvidia, or perhaps even ARM.
- How do you share data with a device?
At its core, SYCL has the concept of a queue and you use a C++ constructor to create it. This queue is the mechanism by which you are able to asynchronously talk to the device. You tell the queue that you want to share data, or you tell the queue that you want to have computation offloaded.
Per the table below, there are a range of predefined SYCL device selectors that can be used directly:
|
default_selector |
Selects device according to implementation-defined heuristic or host device if no device can be found. |
|
gpu_selector |
Select a GPU. |
|
accelerator_selector |
Select an accelerator. |
|
cpu_selector |
Select a CPU device. |
|
host_selector |
Select the host device. |
New devices can be derived from these with the help of a device selector operator.
Using the device selector is then as easy as the following example in Figure 2:
// Standard SYCL header
#include <CL/sycl.hpp>
int main() {
sycl::device d;
// Exception checking for GPU availability
try {
d = sycl::device(sycl::gpu_selector());
} catch (sycl::exception const &e) {
std::cout << "Cannot select a GPU\n" << e.what() << "\n";
std::cout << "Using a CPU device\n";
d = sycl::device(sycl::cpu_selector());
}
std::cout << "Using " << d.get_info<sycl::info::device::name>();
}
Figure 2. The SYCL Queue Concept
For data input and output parameter sharing, one common approach is the use of buffers (see Figure 3). Buffers give you a control over data management as part of the program-execution flow, allowing you to answer the following questions:
- Which exact data do you want to share?
- Which method do you want to use for data sharing?
- When and how would you like to receive the return data?
#include <CL/sycl.hpp>
#include <iostream>
int main() {
sycl::queue Q;
std::cout << "Running on: " << Q.get_device().get_info<sycl::info::device::name>() << std::endl;
int sum;
std::vector<int> data{1, 1, 1, 1, 1, 1, 1, 1};
sycl::buffer<int> sum_buf(&sum, 1);
sycl::buffer<int> data_buf(data);
Q.submit([&](sycl::handler& h)
{
sycl::accessor buf_acc{data_buf, h, read_only};
h.parallel_for(sycl::range<1>{8},
sycl::reduction(sum_buf, h, std::plus<>()),
[=](sycl::id<1> idx, auto& sum)
{
sum += buf_acc[idx];
});
});
sycl::host_accessor result{sum_buf, read_only};
std::cout << "Sum equals " << result[0] << std::endl;
return 0;
}
Figure 3. The Use of Buffers for Data Sharing
A frequently favored concept is also the use of universal shared memory (USM). As the name suggests, this becomes a virtual, common memory location. Multiple devices (CPU, GPU, FPGA, accelerator) have access to this memory and can write to, as well as copy from, it. This idea of a common area that various devices can point to fits organically and naturally into the pointer mentality of C++.
Summary and Next Steps
SYCL gives you the basis for a complete open-standards-based ecosystem and an open oneAPI framework for the future of heterogeneous software development on the basis of C++.
It gives you all of this fully in sync with C++ programming philosophy.
Come and join us in making this future happen. Check out how SYCL and oneAPI fit into your next heterogeneous software development project.
Related Content
Get the Software
Test it for yourself today by downloading and installing the Intel® oneAPI Base Toolkit with Priority Support.
Priority Support provides you with direct, confidential, and in-depth professional software support and guidance for oneAPI Developer Toolkits. Priority Support provides access to all of your 1:1 support database-tracked interactions with dedicated Intel software engineers, architecture consulting at a reduced cost, and more. Learn more about Priority Support for Intel oneAPI Developer Toolkits.