Automatic speech recognition (ASR) is the ability to convert human speech to written text. The idea is to take a piece of recorded audio and transcribe it into written words in the same language, or first translate it to another language and then transcribe it in that new target language. Whisper is a popular series of open source automatic speech recognition and translation models from OpenAI*.
I grew up in Canada and happen to speak English and French. In this article, I will give you a practical hands-on example, with code, that I used to perform transcription and translation from English to English, English to French, French to French, and French to English. The idea is to equip you with the tools to run inference yourself for all of your translation or transcription needs. The example will also enable you to deploy the code without the need for a GPU and instead use more widely available CPUs.

Figure 1. Whisper architecture diagram. A transformer model "is trained on many different speech processing tasks, including multilingual speech recognition, speech translation, spoken language identification, and voice activity detection. All of these tasks are jointly represented as a sequence of tokens to be predicted by the decoder, allowing for a single model to replace many different stages of a traditional speech processing pipeline." (Diagram and quote source: Radford et al, 2022).
Whisper Models
Whisper models, at the time of writing, are receiving over one million downloads per month on Hugging Face* (see whisper-large-v3). Whisper was trained on an impressive 680 K hours (or 77 years) of labeled audio data. Table 1 gives a summary of the current Whisper models. We will be focused on the latest large-v3 model in this article, which shows a big gain in accuracy of 10%–20% over large-v2.
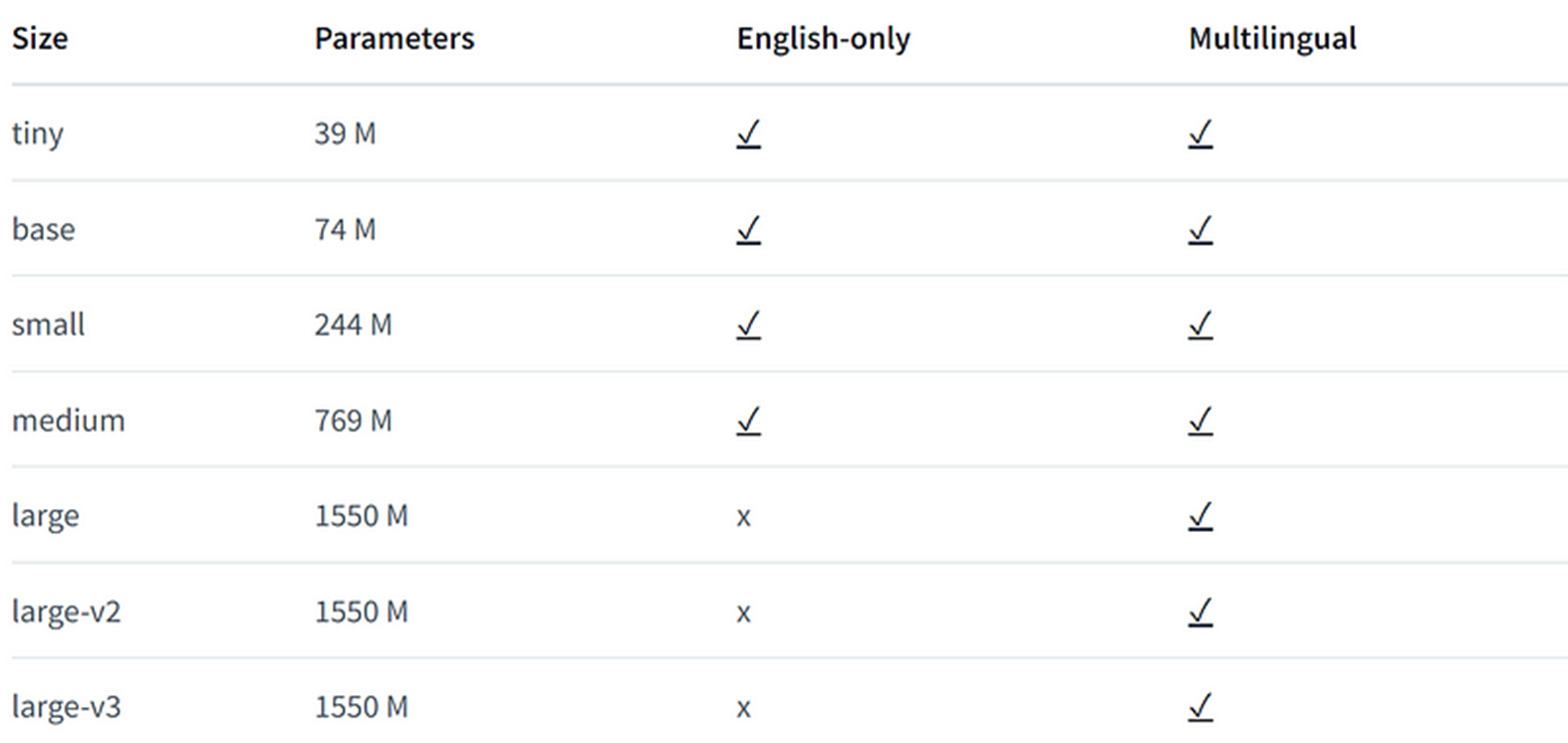
Table 1: Whisper models, parameter sizes, and available languages. The large-v3 model is used in this article (source: openai/whisper-large-v3).
Whisper Sample Code
I will walk you through the code I used to run inference on a CPU for Whisper. The PyTorch* code is largely taken from these samples with some slight modifications to run on CPU.
- Install dependencies. From the command line, install the PyTorch CPU version. At the time of writing, this is PyTorch version 2.2.1+cpu.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
Then install the requirements.txt file with other dependencies:transformers==4.37.2 datasets[audio]==2.17.0 accelerate==0.27.0 soundfile==0.12.1 librosa==0.10.1 accelerate==0.27.0 pip install -r requirements.txt
If you are running these in a notebook environment, and this is your first time installing these packages, you will need to shut down this notebook kernel by going to Kernel — Shut Down Kernel, and then reopen the kernel to make sure all the packages are recognized in the notebook. - Import the appropriate libraries for Whisper:
import warnings warnings.filterwarnings("ignore") from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline from datasets import load_dataset, Audio import torch from IPython.display import Audio as display_Audio, display import torchaudio - Model loading and sample inference: To set your device, load the Whisper model from Hugging Face, and then run a sample inference from the dataset distil-whisper/librispeech_long:
#English transcription full example from https://huggingface.co/openai/whisper-large-v3 device = torch.device('cpu') torch_dtype = torch.float32 model_id = "openai/whisper-large-v3" model = AutoModelForSpeechSeq2Seq.from_pretrained( model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True ) model.to(device) processor = AutoProcessor.from_pretrained(model_id) pipe = pipeline( "automatic-speech-recognition", model=model, tokenizer=processor.tokenizer, feature_extractor=processor.feature_extractor, max_new_tokens=128, chunk_length_s=30, batch_size=16, return_timestamps=True, torch_dtype=torch_dtype, device=device, ) dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation") sample = dataset[0]["audio"] result = pipe(sample) print(result["text"])
After running inference, you should see this output:
Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel. Nor is Mr. Quilter's manner less interesting than his matter. He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similes drawn from eating and its results occur most readily to the mind. He has grave doubts whether Sir Frederick Leighton's work is really Greek after all, and can discover in it but little of rocky Ithaca. Linnell's pictures are a sort of Upguards and Adam paintings, and Mason's exquisite idylls are as national as a jingo poem. Mr. Burkett Foster's landscapes smile at one much in the same way that Mr. Carker used to flash his teeth. And Mr. John Collier gives his sitter a cheerful slap on the back before he says, like a shampooer in a Turkish bath, Next man!
Languages Supported by OpenAI* Whisper
Whisper supports around 100 languages. A list is on GitHub*.
- Helper functions. This example of translation and transcriptions uses English and French recordings. I used an app called Hokusai Audio Editor to record directly in .wav format, which is easy for Torchaudio to recognize when loading audio files. But you can use any online converter tool to get to a .wav format.
I wrote to these short Python* functions:- Load the audio and convert the sample rate to what Whisper expects (16,000 Hz).
- Run inference with a target output language.
#utility functions def load_recorded_audio(path_audio,input_sample_rate=48000,output_sample_rate=16000): # Dataset: convert recorded audio to vector waveform, sample_rate = torchaudio.load(path_audio) waveform_resampled = torchaudio.functional.resample(waveform, orig_freq=input_sample_rate, new_freq=output_sample_rate) #change sample rate to 16000 to match training. sample = waveform_resampled.numpy()[0] return sample def run_inference(path_audio, output_lang, pipe): sample = load_recorded_audio(path_audio) result = pipe(sample, generate_kwargs = {"language": output_lang, "task": "transcribe"}) print(result["text"])
- Performing inference. Let's move onto my recorded English and French statements and assess how well Whisper does on translation and transcription.
I recorded a statement in English that reads as follows: I am happy to be participating in this hackathon. I hope you come up with some great solutions throughout the day and perhaps also at night.
And the path of where I stored the file:
And I also recorded my translation of the statement in French:path_audio_en_2 = 'recordings/English_hackathon.wav'
Je suis heureux de participer à ce hackathon. J’espère que vous trouverez des excellentes solutions pendant la journée et peut-être aussi à la nuit.
And the path of the file:
I then tested the four possible transcription and translation tasks:path_audio_fr_2 = 'recordings/French_hackathon.wav'- English to English
The printed transcribed output looks like this: I am happy to be participating in this hackathon. I hope you come up with some great solutions throughout the day and perhaps also at night.path_audio = path_audio_en_2 output_lang = "en" run_inference(path_audio,output_lang, pipe)
In this case, Whisper did a perfect job at transcription, matching my original recorded statement.
- English-to-French: I asked Whisper to translate my recorded English statement to French, and then transcribe it.
path_audio = path_audio_en_2 output_lang = "fr" run_inference(path_audio, output_lang, pipe)
Here is the output: Je suis heureux de participer à ce Hackathon. J’espère que vous trouverez de grandes solutions au long du jour et peut-être aussi à la nuit.
The output closely matches how I would have translated the statement into French, even though there are slight differences. The reality with language translation is that multiple options can be valid and the meaning remains the same.
- French to French: I then asked Whisper to transcribe my French statement into French.
path_audio = path_audio_fr_2 output_lang = "fr" run_inference(path_audio, output_lang, pipe)
Here is the output: Je suis heureux de participer à ce hackathon. J’espère que vous trouverez des excellentes solutions pendant la journée et peut-être aussi à la nuit.
This is a perfect transcription of my recording.
- French to English: Here is how I tested the transcription:
Here is the output: I am happy to participate in this hackathon. I hope you will find excellent solutions during the day and maybe at night.path_audio = path_audio_fr_2 output_lang = "en" run_inference(path_audio, output_lang, pipe)
Again, the English translation has some slight differences from my own translation, but the meaning and grammar are accurate.
- English to English
One of the neat things about Whisper is that it automatically detects the original language, so I don't need to specify the input language—only the output language.
Conclusion
This article showed the code I used to complete four translation and transcription tasks with the latest Whisper model (large-v3) from OpenAI on a CPU. These language tasks were: English to English, English to French, French to French, and French to English.
Next Steps
To replicate the work, you can complete your development for free on the Intel® Tiber™ Developer Cloud. After signing in, select Training, and then Launch Jupyter* Lab to launch a free Jupyter environment with a 4th generation Intel® Xeon® CPU. You can also find the same CPUs on the cloud providers Amazon Web Services (AWS)* or Google Cloud Platform* service.
We encourage you to also check out and incorporate Intel’s other AI and machine learning framework optimizations and end-to-end portfolio of tools into your AI workflow and learn about the unified, open, standards-based oneAPI programming model that forms the foundation of the Intel® AI Software Portfolio to help you prepare, build, deploy, and scale your AI solutions.
Resources
To learn more on how to fine-tune training on Intel hardware and to upload your model to Hugging Face, visit Hugging Face training on GitHub.
Here is some other helpful documentation for Whisper:
- Fine-Tuning Whisper
- Google Colab Code
- Optimized (Smaller) Whisper Models from Intel
- Training the Whisper Model
To share your Hugging Face model and to join the community discussion, go to Intel® DevHub on Discord*. You can also share how you implemented your unique language combination.
Intel® Tiber™ Developer Cloud
Get what you need to build, test, and optimize your oneAPI projects for free.
AI Tools
Accelerate data science and AI pipelines—from preprocessing through machine learning—and provide interoperability for efficient model development.