In second generation Intel® Core™ processors and Intel® Xeon E3-1200 Series Processors and later processor families, Intel introduced a microarchitectural structure called the Decoded ICache (also called the Decoded Streaming Buffer or DSB) to decode instructions coming out of the legacy decode pipeline and speed program execution.
On some Intel® processors (see Affected Processors), conditional branch instructions may exhibit unpredictable behavior under complex microarchitectural conditions involving jump instructions that span 64-byte boundaries. More details can be found in the Intel® Xeon® Processor Scalable Family Specification Update under SKX102.
Intel has released a microcode update (MCU) to fix this issue, called the Jump Conditional Code erratum, but the update could cause a performance degradation ranging from 0-4% on certain industry-standard benchmarks.
Many applications will not see a significant performance impact from this MCU. If you suspect that the mitigation is affecting your app’s performance, the instructions below explain how you can determine whether this is the case, and then provide guidance to help you recover some or all of the performance loss.
Performance Monitoring
The JCC erratum MCU workaround will cause a greater number of misses out of the DSB and subsequent switches to the legacy decode pipeline. This occurs since branches that overlay or end on a 32-byte boundary are unable to fill into the Decoded ICache.
Intel has observed performance effects associated with the workaround ranging from 0-4% on many industry-standard benchmarks1. In subcomponents of these benchmarks, Intel has observed outliers higher than the 0-4% range. Other workloads not observed by Intel may behave differently. Intel has in turn developed software-based tools to minimize the impact on potentially affected applications and workloads.
The potential performance impact of the JCC erratum mitigation arises from two different sources:
- A switch penalty that occurs when executing in the Decoded ICache and switching over to the legacy decode pipeline.
- Inefficiencies that occur when executing from the legacy decode pipeline that are potentially hidden by the Decoded ICache.
Performance Monitoring Events to Look for
Tools like Intel® VTune™ Profiler can be used to locate performance bottlenecks, and more specifically can find locations in the code where the legacy decode pipeline is being used, rather than the DSB.
The list below describes critical events that can be used to compare performance before and after the MCU to determine whether the MCU causes any performance impact on your workloads.
Collect the following events to detect the performance effects of the MCU:
CPU_CLK_UNHALTED.THREAD= Core clock cycles in C0.IDQ.DSB_UOPS= μops coming from the Decoded ICache.DSB2MITE_SWITCHES.PENALTY_CYCLES= Penalty cycles introduced into the pipeline from switching from the Decoded ICache.FRONTEND_RETIRED.DSB_MISS_PS= Precise frontend retired DSB miss will tag within the 64-byte boundary where the DSB miss occurs.IDQ.MS_UOPS= μops coming from the microcode sequencer.IDQ.MITE_UOPS= μops coming from the legacy decode pipeline (also called the Micro Instruction Translation Engine)LSD.UOPS= μops coming from the Loop Stream Detector (LSD)
Note: The LSD is only available on some cores. The LSD.UOPS event can be excluded from calculations if not present as an event.
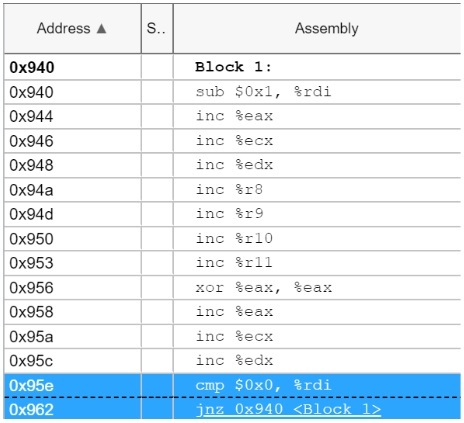
Figure 1 below is an example from Intel® VTune™ Profiler showing a disassembled function which contains a loop where the macrofused cmp + jnz is crossing a 32-byte boundary, causing a performance loss. This function shows an increase in IDQ.MITE_UOPS and a decrease in IDQ.DSB_UOPS.
To further understand how the legacy decode pipeline and DSB can impact the performance of the front end of the CPU pipeline, refer to Understanding the Instruction Pipeline and other articles in the Get Started with Intel® VTune™ Profiler guide.
Software Guidance and Optimization Methods
Software can compensate for the performance effects of the mitigation for this erratum with optimizations that align the code such that jump instructions (and macro-fused jump instructions) do not cross 32-byte boundaries or end on 32-byte boundaries. Aligning the code in this way can reduce or eliminate the performance penalty caused by execution transitioning from Decoded ICache to the legacy decode pipeline.
In the following code example, the two-byte jump instruction jae starting at offset 1f spans a 32-byte boundary and can cause a transition from the Decoded ICache to the legacy decode pipeline.
Code without JCC Mitigation
0000000000000000 <fn1>:
0: 55 push %rbp
1: 41 54 push %r12
3: 48 89 e5 mov %rsp,%rbp
6: c5 f8 10 04 0f vmovups (%rdi,%rcx,1),%xmm0
b: c5 f8 11 04 0a vmovups %xmm0,(%rdx,%rcx,1)
10: c5 f8 10 44 0f 10 vmovups 0x10(%rdi,%rcx,1),%xmm0
16: c5 f8 11 44 0a 10 vmovups %xmm0,0x10(%rdx,%rcx,1)
1c: 48 39 fe cmp %rdi,%rsi
1f: 73 09 jae 2a <fn1+0x2a>
21: e8 00 00 00 00 callq 26 <fn1+0x26>
26: 41 5c pop %r12
28: c9 leaveq
29: c3 retq
2a: e8 00 00 00 00 callq 2f <fn1+0x2f>
2f: 41 5c pop %r12
31: c9 leaveq
32: c3 retq
Intel’s advice to software developers is to align the jae instruction so that it does not cross a 32-byte boundary. In the example, this is done by adding the benign prefix 0x2e four times before the first push %rbp instruction so that the cmp instruction, which started at offset 1c, will instead start at offset 20. Hence the macro-fused cmp + jae instruction will not cross a 32-byte boundary.
Code with JCC Mitigation
0000000000000000 <fn1>:
0: 2e 2e 2e 2e 55 cs cs cs cs push %rbp
5: 41 54 push %r12
7: 48 89 e5 mov %rsp,%rbp
a: c5 f8 10 04 0f vmovups (%rdi,%rcx,1),%xmm0
f: c5 f8 11 04 0a vmovups %xmm0,(%rdx,%rcx,1)
14: c5 f8 10 44 0f 10 vmovups 0x10(%rdi,%rcx,1),%xmm0
1a: c5 f8 11 44 0a 10 vmovups %xmm0,0x10(%rdx,%rcx,1)
20: 48 39 fe cmp %rdi,%rsi
23: 73 09 jae 2e <fn1+0x2e>
25: e8 00 00 00 00 callq 2a <fn1+0x2a>
2a: 41 5c pop %r12
2c: c9 leaveq
2d: c3 retq
2e: e8 00 00 00 00 callq 33 <fn1+0x33>
33: 41 5c pop %r12
35: c9 leaveq
36: c3 retq
Software Tools to Improve Performance
Intel has worked with the community on tools to help developers align branches, and has observed that recompiling software with the updated tools can help recover most of the performance loss that might be otherwise observed in selected applications.
There are two padding mechanisms for JCC mitigation alignment:
- Inserting
nopinstructions - Inserting meaningless prefixes before instructions (prefix padding)
Theoretically, prefix padding can provide better performance because it reduces the number of nop instructions, therefore raising the DSB hit rate. In our experiments, we observed that prefix padding is slightly better than nop padding in general, and may provide much better performance in some outliers.
In general, we suggest developers try nop padding first, as it’s easier to start with. Developers can make their own choice whether to use nop padding or prefix padding for their applications. If you still observe significant performance drops after recompiling the application with the JCC mitigation, Intel recommends aligning all branch types with -malign-branch=jcc+fused+jmp+call+return+indirect.
GNU assembler options are available in binutils 2.34. LLVM nop padding was implemented in LLVM 10.0.0, followed by prefix padding in the LLVM 11 main trunk. ICC has supported prefix padding since the 19.1 release.
In the following sections, we summarize some options you can use with the GNU assembler, and then compare the GNU assembler options with options available in the Intel and LLVM compilers.
Options for GNU Assembler
-mbranches-within-32B-boundaries
This is the recommended option for affected processors2. This option aligns conditional jumps, fused conditional jumps, and unconditional jumps within a 32-byte boundary with up to 5 segment prefixes on an instruction. It is equivalent to the following:
-malign-branch-boundary=32-malign-branch=jcc+fused+jmp-malign-branch-prefix-size=5
The default doesn't align branches.
-malign-branch-boundary=NUM
This option controls how the assembler should align branches with segment prefixes or NOP. NUM must be a power of 2. Branches will be aligned within the NUM byte boundary. The default -malign-branch-boundary=0 doesn't align branches.
-malign-branch=TYPE[+TYPE...]
This option specifies types of branches to align. TYPE is combination of the following:
jcc, which aligns conditional jumps.fused, which aligns fused conditional jumps.jmp, which aligns unconditional jumps.call, which aligns calls.ret, which aligns returns.indirect, which aligns indirect jumps and calls.
The default is -malign-branch-boundary=jcc+fused+jmp.
-malign-branch-prefix-size=NUM
This option specifies the maximum number of prefixes on an instruction to align branches. NUM should be between 0 and 5. The default NUM is 5.
Differences Between GNU Assembler, ICC, and Clang Options
There are some differences between the options available in GNU Assembler, ICC, and Clang because each compiler uses a different implementation. The table below lists the different options in each compiler. Refer to the descriptions of the GNU assembler options and the comparable options listed here to find the right options to use with your compiler.
| Prefix padding | NOP padding | Fined options | Override principle | |
|---|---|---|---|---|
| GNU Assembler | -mbranches-within-32B-boundaries |
-mbranches-within-32B-boundaries |
-malign-branch-prefix-size |
The latter option overrides the former option. |
| ICC | -mbranches-within-32B-boundaries |
None | None | None |
| Clang | -mbranches-within-32B-boundaries |
-mbranches-within-32B-boundaries |
-mpad-max-prefix-size |
The fined option overrides the general option. |
Affected Processors
To find the mapping between a processor's CPUID and its Family/Model number, refer to the Intel® 64 and IA-32 Architectures Software Developer Manuals, Vol 2A, table 3-8, and the INPUT EAX = 01H: Returns Model, Family, Stepping Information section.
| Family_Model | Stepping | Processor Families/Processor Number series |
|---|---|---|
| 06_8EH | 9 | 8th Generation Intel® Core™ Processor Family based on microarchitecture code name Amber Lake Y |
| 06_8EH | C | 8th Generation Intel® Core™ Processor Family based on microarchitecture code name Amber Lake Y |
| 06_55 | 7 | 2nd Generation Intel® Xeon® Scalable Processors based on microarchitecture code name Cascade Lake (server) |
| 06_9EH | A | 8th Generation Intel® Core™ Processor Family based on microarchitecture code name Coffee Lake H |
| 06_9EH | A | 8th Generation Intel® Core™ Processor Family based on microarchitecture code name Coffee Lake S |
| 06_8EH | A | 8th Generation Intel® Core™ Processor Family based on microarchitecture code name Coffee Lake U43e |
| 06_9EH | B | 8th Generation Intel® Core™ Processor Family based on microarchitecture code name Coffee Lake S (4+2) |
| 06_9EH | B | Intel® Celeron® Processor G Series based on microarchitecture code name Coffee Lake S (4+2) |
| 06_9EH | A | 8th Generation Intel® Core™ Processor Family based on microarchitecture code name Coffee Lake S (6+2) x/KBP |
| 06_9EH | A | Intel® Xeon® Processor E Family based on microarchitecture code name Coffee Lake S (6+2)3 |
| 06_9EH | A | Intel® Xeon® Processor E Family based on microarchitecture code name Coffee Lake S (4+2)3 |
| 06_9EH | D | 9th Generation Intel® Core™ Processor Family based on microarchitecture code name Coffee Lake H (8+2) |
| 06_9EH | D | 9th Generation Intel® Core™ Processor Family based on microarchitecture code name Coffee Lake S (8+2) |
| 06_8EH | C | 10th Generation Intel® Core™ Processor Family based on microarchitecture code name Comet Lake U42 |
| 06_A6H | 0 | 10th Generation Intel® Core™ Processor Family based on microarchitecture code name Comet Lake U62 |
| 06_9EH | 9 | 8th Generation Intel® Core™ Processor Family based on microarchitecture code name Kaby Lake G |
| 06_9EH | 9 | 7th Generation Intel® Core™ Processor Family based on microarchitecture code name Kaby Lake H |
| 06_AEH | A | 8th Generation Intel® Core™ Processor Family based on microarchitecture code nameKaby Lake Refresh U (4+2) |
| 06_9EH | 9 | 7th Generation Intel® Core™ Processor Family based on microarchitecture code name Kaby Lake S |
| 06_8EH | 9 | 7th Generation Intel® Core™ Processor Family based on microarchitecture code name Kaby Lake U |
| 06_8EH | 9 | 7th Generation Intel® Core™ Processor Family based on microarchitecture code name Kaby Lake U23e |
| 06_9EH | 9 | Intel® Core™ X-series Processors based on microarchitecture code name Kaby Lake X |
| 06_9EH | 9 | Intel® Xeon® Processor E3 v6 Family Kaby Lake Xeon E3 |
| 06_8EH | 9 | 7th Generation Intel® Core™ Processor Family based on microarchitecture code name Kaby Lake Y |
| 06_55H | 4 | Intel® Xeon® Processor D Family based on microarchitecture code name Skylake D, Bakerville |
| 06_5E | 3 | 6th Generation Intel® Core™ Processor Family based on microarchitecture code name Skylake H |
| 06_5E | 3 | 6th Generation Intel® Core™ Processor Family based on microarchitecture code name Skylake S |
| 06_55H | 4 | Intel® Xeon® Scalable Processors based on microarchitecture code name Skylake Server |
| 06_4E | 3 | 6th Generation Intel® Core™ Processors based on microarchitecture code name Skylake U |
| 06_4E | 3 | 6th Generation Intel® Core™ Processor Family based on microarchitecture code name Skylake U23e |
| 06_55H | 4 | Intel® Xeon® Processor W Family based on microarchitecture code name Skylake W |
| 06_55H | 4 | Intel® Core™ X-series Processors based on microarchitecture code name Skylake X |
| 06_55H | 4 | Intel® Xeon® Processor E3 v5 Family based on microarchitecture code name Skylake Xeon E3 |
| 06_4E | 3 | 6th Generation Intel® Core™ Processors based on microarchitecture code name Skylake Y |
| 06_8EH | B | 8th Generation Intel® Core™ Processors based on microarchitecture code name Whiskey Lake U |
| 06_8EH | C | 8th Generation Intel® Core™ Processors based on microarchitecture code name Whiskey Lake U |
Footnotes
- Data measured on Intel internal reference platform for research/educational purposes.
- Server benchmarks include:
- SPECrate2017_int_base compiler with Intel Compiler Version 19 update 4
- SPECrate2017_fp_base compiler with Intel Compiler Version 19 update 4
- Linpack, Stream Triad, FIO.(rand7030_4K_04_workers_Q32/seq7030_64K_04_workers_Q32)
- HammerDB-Postgres
- SPECjbb2015
- SPECvirt
- Client benchmarks include:
- SPECrate2017_int_base compiler with Intel Compiler Version 19 update 4
- SPECrate2017_fp_base compiler with Intel Compiler Version 19 update 4
- SYSmark 2018
- PCmark 10
- 3Dmark Sky Diver
- WebXPRT v3
- Cinebench R20
- Server benchmarks include:
- Note that some processors which are not affected may take longer to decode instructions with more than 3 or 4 prefixes (for example Silvermont and Goldmont processors as noted in the Intel® 64 and IA-32 Architectures Optimization Reference Manual).
- Workstation, server, and desktop included
Software Security Guidance Home | Advisory Guidance | Technical Documentation | Best Practices | Resources