
Deep learning frameworks offer researchers and developers the building blocks for designing and training deep neural networks quickly. This makes it easier for practitioners to apply deep learning to real-world problems.
PyTorch* and TensorFlow* are among the most popular open source deep learning frameworks. Although they have differences in how they run code, both are optimized tensor libraries used for deep learning applications on CPUs and GPUs.
This blog focuses on two recent trainings delivered at the oneAPI DevSummit for AI and HPC. It shares each on-demand session to help you acquire new (or reinforce existing) development skills:
- Accelerate PyTorch Deep Learning Models on Intel® XPUs
- Take Advantage of Default Optimizations in TensorFlow* from Intel
Let’s get started.
Workshop 1: Accelerate PyTorch* Deep Learning Models on Intel® XPUs
Session Overview
PyTorch is an open source deep learning framework based on Python*. It is built for both research and production deployment. In this session, Pramod Pai, Intel AI software and solutions engineer, begins with an overview about Intel® Optimization for PyTorch* as well as the newest optimizations and usability features that are first released in Intel® Extension for PyTorch* before they are incorporated into open source PyTorch.
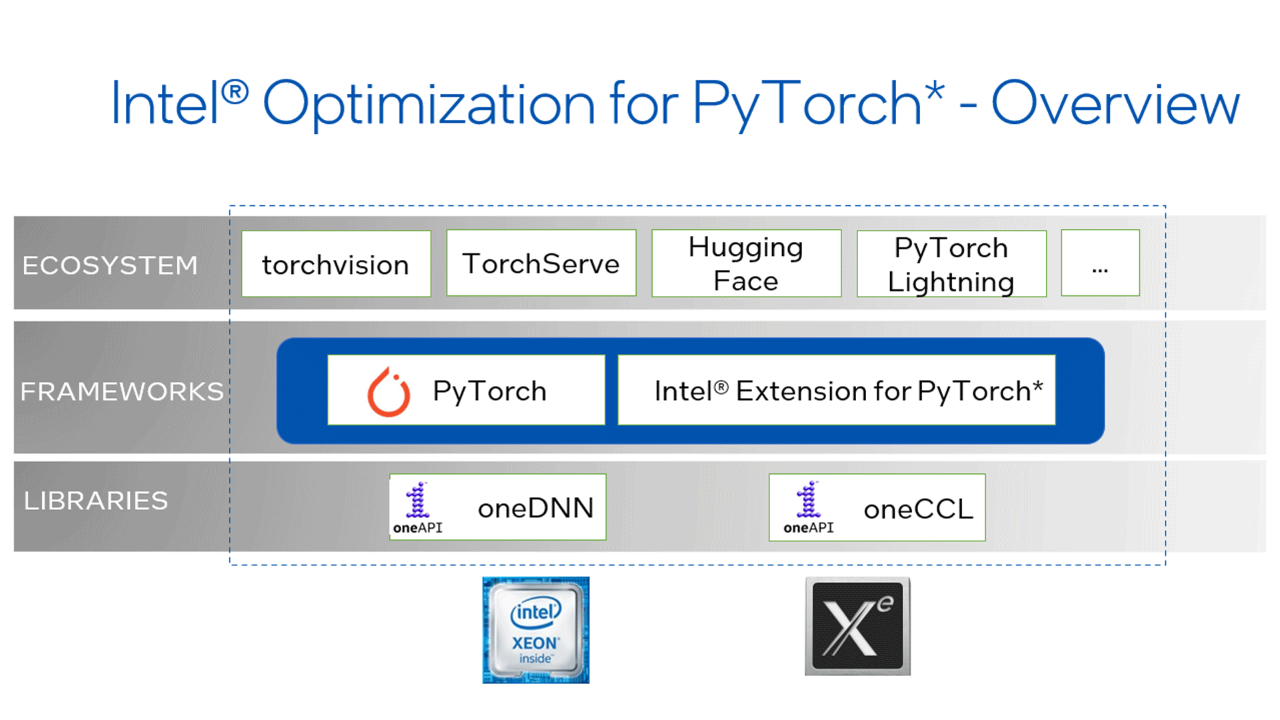
Next, he explains major optimization methodologies:
- Operators Optimization: Involves vectorization and parallelization to maximize the efficiency of CPU capability and use.
- Graph Optimization: Constant folding and operator fusion are the two main components.
- Runtime Extension: Overheads can be avoided by using thread affinity and tweaking memory allocation methodologies.
He then gives an overview about the structure of the Intel extension, including the following examples on how to use it for FP32 and bfloat16. Check out Intel Extension for PyTorch (GitHub*) and feel free to contribute to this project.

Finally, Pramod shows the performance improvements using Intel Extension for PyTorch compared to the stock PyTorch. For more information, see Configurations.
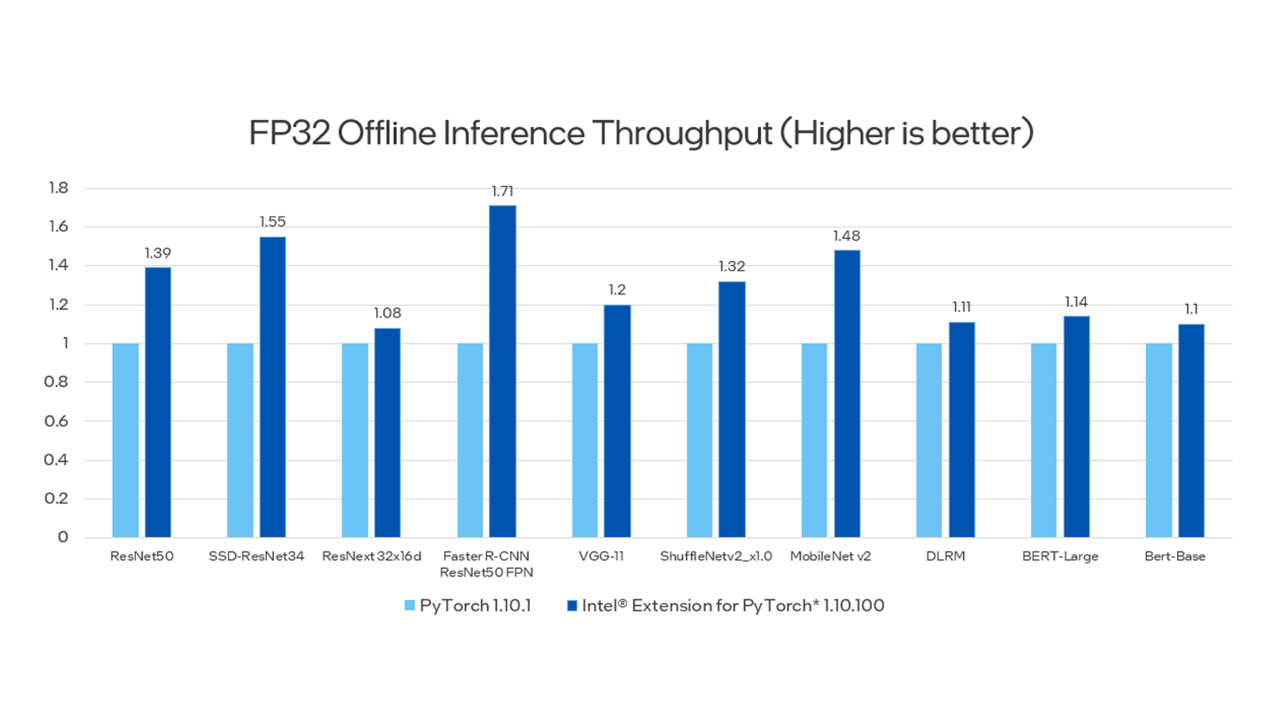
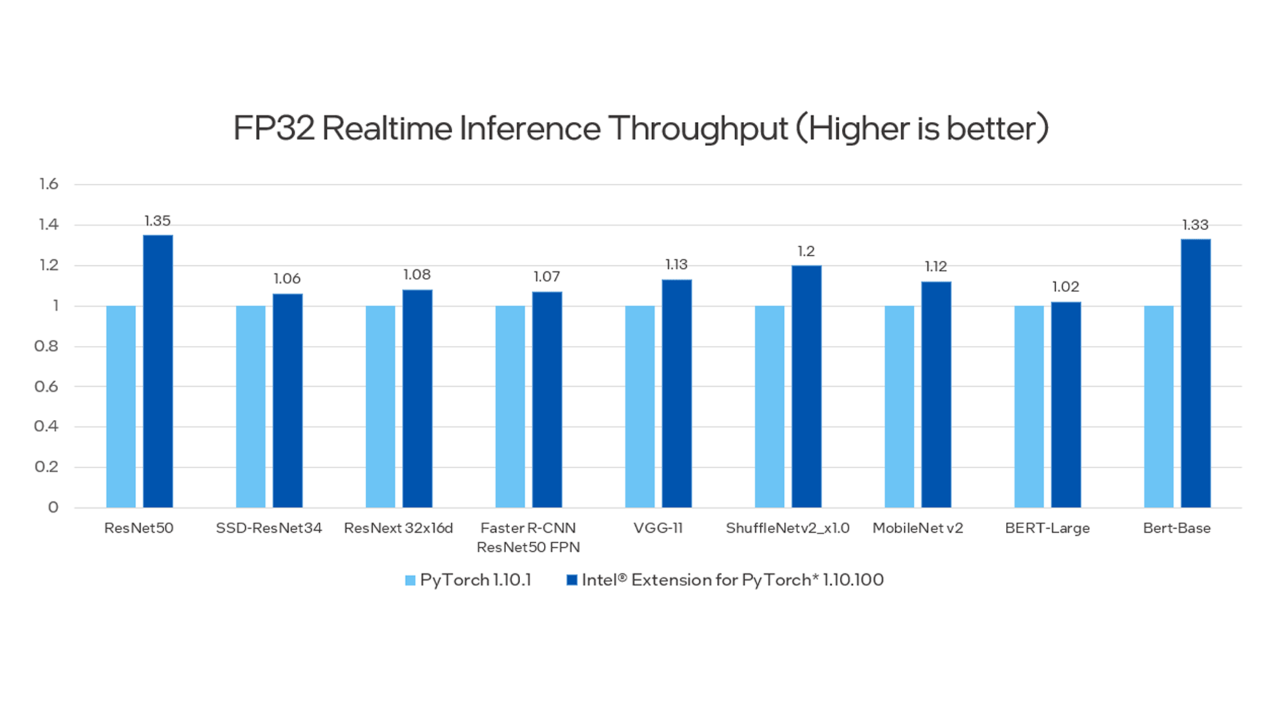
Hands-On Lab
To access the code sample used in this session, go to the GitHub repository for the workshop. It includes:
- Getting started with Intel Extension for PyTorch for sample computer vision and natural language processing (NLP) workloads
- Loading two models from the PyTorch hub: Faster R-CNN and DistilBERT
- Applying sequential optimizations from the Intel extension and examining performance gains for each incremental change
- The steps for trying out the code sample in a Linux* environment and on Intel® Developer Cloud
Workshop 2: Take Advantage of Default Optimizations in TensorFlow from Intel
Session Overview
TensorFlow is a free, open source library and end-to-end machine learning platform that makes machine learning and developing neural networks faster and easier. In this session, Sachin Muradi, Intel deep learning software engineer, begins with a synopsis of TensorFlow, followed by an introduction to Intel’s optimizations in the framework contributed by Intel® oneAPI Deep Neural Network Library (oneDNN). oneDNN is an open source cross platform library used for deep learning applications. It also supports FP32, FP16, bfloat16, and int8 datatypes. (Starting with TensorFlow 2.9, oneDNN optimizations are automatic. For TensorFlow v2.5 through v2.8, the optimizations can be enabled by setting the environment variable TF_ENABLE_ONEDNN_OPTS=1.)
When combined with oneDNN, TensorFlow provides a CPU performance boost as shown in the following graphs. For more information, see Configurations.
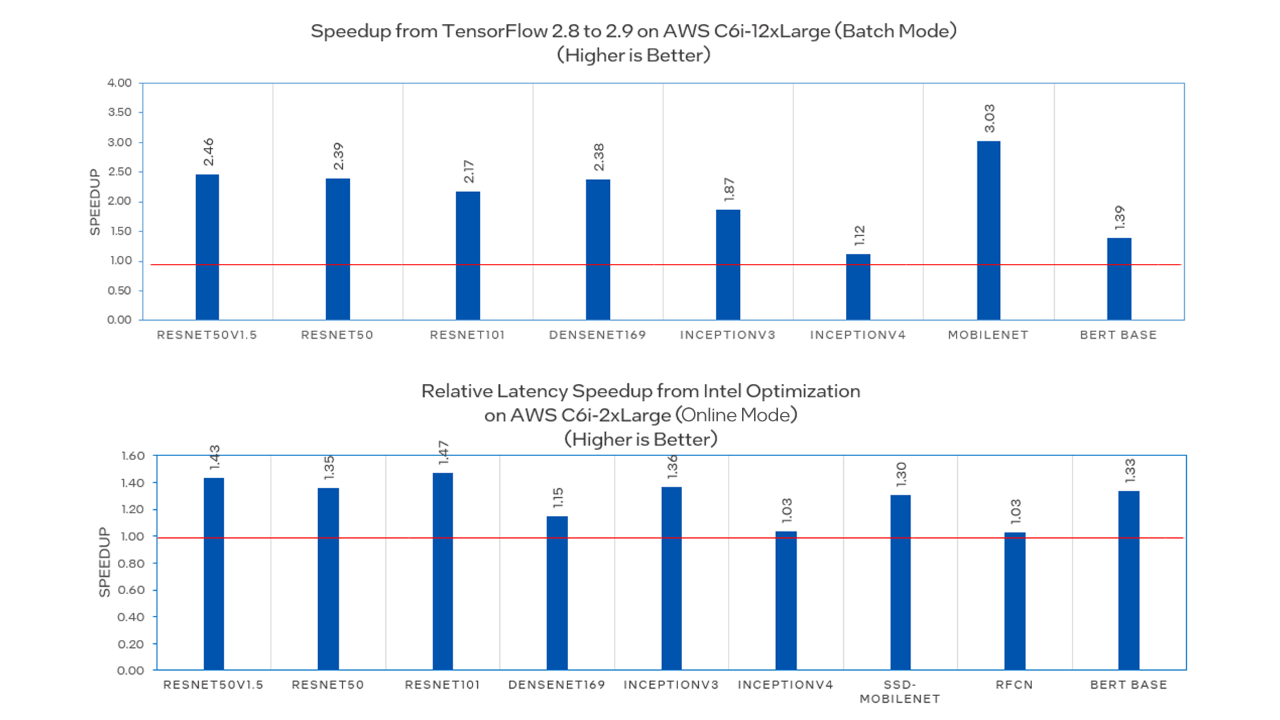
Next, Sachin explains the bfloat16 data type, a floating-point format that occupies 16 bits of computer memory but represents the approximate dynamic range of 32-bit floating-point (FP) numbers. Bfloat16 format is as follows:
- 1 bit - sign
- 8 bits - exponent
- 7 bits - fraction
Compared to FP32, bfloat16 delivers better performance and lower accuracy loss. Its performance enhancement is supported on 3rd gen Intel® Xeon® Scalable processors and with Intel AMX instructions on 4th gen Intel Xeon Scalable processors.
Hands-On Lab
Go to the GitHub repository for the workshop to access the code sample used in this session, which demonstrates three important concepts:
- Benefits of using automatically mixed precision to accelerate tasks like transfer learning, with minimal changes to existing scripts
- Importance of inference optimization on performance
- Ease of using Intel® Optimization for TensorFlow* (which are enabled by default in 2.9.0 and newer)
The sample shows how to fine-tune a pretrained model for image classification using the TensorFlow Flowers dataset. Here, a batch of 512 images measuring 224 x 224 x 3 are used. The following steps are performed:
- Transfer learning for image classification using the TensorFlow Hub's ResNet-50 v1.5 pretrained model
- Export the fine-tuned model in the SavedModel format
- Optimize the SavedModel for faster inference
- Serve the SavedModel using TensorFlow Serving
Try out the code sample in a Linux environment and on the Intel Developer Cloud.
Sachin concludes the workshop by highlighting improved AI performance with new Intel AMX instructions on 4th gen Intel Xeon Scalable processors.
What’s Next?
We encourage you to learn more about and incorporate Intel’s other AI and machine learning framework optimizations and end-to-end portfolio of tools into your AI workflow. Also, visit the AI and machine learning page that covers Intel’s AI software development resources for preparing, building, deploying, and scaling your AI solutions.
For more details about the new 4th gen Intel Xeon Scalable processors, visit AI Platform where you can learn how Intel is empowering developers to run end-to-end AI pipelines on these powerful CPUs.
About the Speakers
Pramod Pai, Intel software solutions engineer
Pramod helps customers optimize their machine learning workflows using solutions from Intel, such as Intel® AI Analytics Toolkit and Intel Extension for PyTorch. He holds a master's degree in information systems from Northeastern University in Massachusetts.
Sachin Muradi, Intel deep learning software engineer
Sachin is part of the Intel team focused on direct optimization for TensorFlow and oneDNN direct optimization, where he uses his expertise in performance libraries and compilers for deep learning accelerator hardware. He holds a master’s degree in electrical and computer engineering from Portland State University in Oregon.
Useful Resources
- Intel AI Developer Tools and Resources
- oneAPI Unified Programming Model
- Documentation: Intel Optimization for PyTorch
- Documentation: Intel Optimization for TensorFlow
- Intel® Extension for TensorFlow* on GitHub
- Model Zoo for Intel Architecture
- Intel® Advanced Matrix (Intel® AMX) Extensions Overview
- Accelerate AI Workloads with Intel AMX
Configurations
FP32 Offline Inference Throughput
Testing Date: Performance results are based on testing by Intel as of January 10, 2022. Configuration Details and Workload Setup: Hardware Configuration: Intel® Xeon® Platinum 8380 CPU at 2.30 GHz, two sockets with 40 cores per socket, 256 GB RAM (16 slots/16 GB/3200 MHz), Hyperthreading: on; Operating System: Ubuntu* v18.04.5 LTS; Software Configuration: PyTorch v1.10.1, Intel Extension for PyTorch v1.10.100; Offline inference refers to running single instance inference with large batch using all cores of a socket.
FP32 Realtime Inference Throughput
Testing Date: Performance results are based on testing by Intel as of January 10, 2022. Configuration Details and Workload Setup: Hardware Configuration: Intel Xeon Platinum 8380 CPU at 2.30 GHz, two sockets with 40 cores per socket, 256 GB RAM (16 slots/16 GB/3200 MHz), Hyperthreading: on; Operating System: Ubuntu v18.04.5 LTS; Software Configuration: PyTorch v1.10.1, Intel Extension for PyTorch v1.10.100; Realtime inference refers to running a multi-instance single batch inference with four cores per instance.
Speedup from TensorFlow 2.8 to 2.9 on Amazon Web Services (AWS)* c6i-12xlarge
Testing Date: Performance results are based on testing by Intel as of May 19, 2021. Configuration Details and Workload Setup: Hardware Configuration: Intel Xeon Platinum 8375C CPU at 2.90 GHz, one socket, 96 GB RAM; Software Configuration: Operating System: Ubuntu v20.04.2; Kernel: 5.11.0-1019-aws x86_64; Model Zoo v2.6.
Latency Speedup from an Intel Optimization on AWS c6i-2Xlarge
Testing Date: Performance results are based on testing by Intel as of May 19, 2021. Configuration Details and Workload Setup: Hardware Configuration: Intel Xeon Platinum 8375C CPU at 2.90 GHz, one socket, 16 GB RAM; Software Configuration: Operating System: Ubuntu v20.04.2, Kernel: 5.11.0-1019-aws x86_64, Model Zoo v2.6.
Intel® oneAPI Base Toolkit
Develop high-performance, data-centric applications for CPUs, GPUs, and FPGAs with this core set of tools, libraries, and frameworks including LLVM-based compilers.