Co-author: Naoaki Yamashita of Yahoo! JAPAN*.
Part1 - Yahoo! JAPAN Shopping's Recommendation use Case
Recommendation is unsurprisingly a critical workload for Yahoo! JAPAN's daily business. Yahoo! JAPAN* has several services like advertisement, auction, news, shopping and each service has its own recommender systems. Like modern recommender systems, the product recommender system for Yahoo! JAPAN Shopping* is also a multi-stage recommender system made up of many components (e.g. ETLs, feature engineerings, recommendation algorithms, online serving, etc.) that function together to eventually prompt users with the contents that they are most likely interested in. The configuration of the stages would be designed based on several constraints such as the amount of the data, available system resources and business requirements. In many cases, each stage would be optimized by different metrics like recall and precision.
One key challenge in building production recommender systems is to efficiently retrieve the most relevant items from an enormous candidate pool with millions or even billions of items in total in real-time. Multi-stage recommender systems make it possible to reduce the number of candidates effectively in a stage-wise manner. In the recommender system for Yahoo! JAPAN Shopping, we tackle this challenge using three stages as follows:
-
Offline item search (also known as offline item recall): In this very first but important stage, for each item we search for 200 similar items within the same category. This stage greatly reduces the candidate space from millions to hundreds.
-
Offline item ranking: In this stage, we use Learning-to-Rank (GBDT, DNN) to get more precise candidate orders from the results of the recall stage.
-
Online re-ranking: Based on user features, current activities and/or business logics, the system would trigger many types of next-item recommendation service. The online recommendation products together with their top similar items from the offline item ranking would be combined and recommended to the user.
The general workflow of the above stages is shown in Figure 1. We conduct all the item-to-item recommendations offline so that during the online stage, the result of ranking stage could be directly fetched with lower latency as no extra item-based computations are involved. Since our item space is huge (more than millions per category), efficient offline item search would play an important role in our entire recommender system.
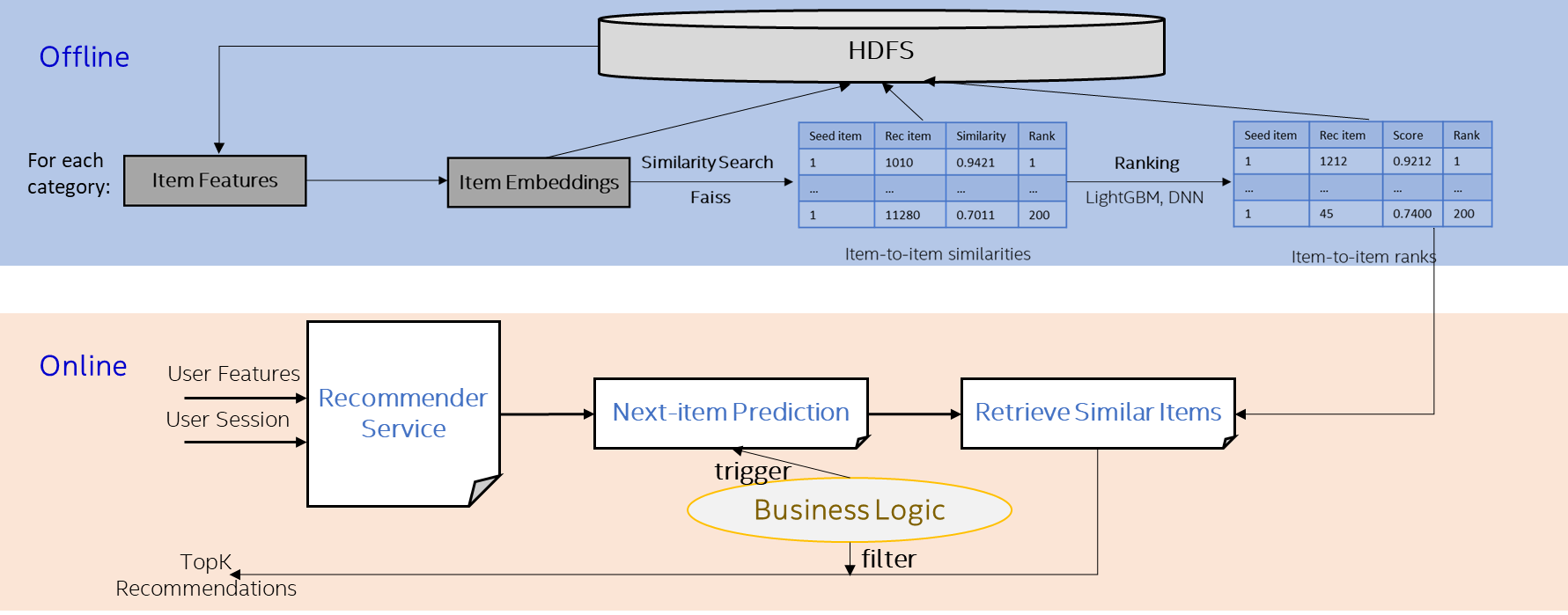
Figure 1: Recommendation Workflow at Yahoo! JAPAN Shopping
This blog mainly discusses Yahoo! JAPAN Shopping’s practice of efficiently performing large-scale offline item recall (i.e. the first stage discussed above) using the solution provided in BigDL. We do item search based on item embeddings, which have been trained beforehand regularly, using the vector search algorithms provided in Faiss and utilizes BigDL as well as Apache Spark to scale Intel® optimized Faiss to large Intel® Xeon clusters in a distributed fashion with high performance. From our experiments, this implementation can achieve outstanding performance compared with our previous trials on single-node 4 Nvidia V100 and we have successfully adopted it in our production environment.
Part2 - Faiss Overview
With AI tools, like bags-of-words, word2vec or convolutional neural net (CNN) descriptors, each item can be trained to have a high-dimensional dense vector representation of its characteristics, which is also known as embeddings. In the same latent space, the distance (e.g. dot product or cosine distance) between two item vectors can therefore reflect the similarity between these two items. Similarity search performs the work to search for a certain number of most similar items in the database given a query item.
Facebook AI Similarity Search (Faiss) is a library for efficient similarity search of dense vectors developed primarily at Facebook AI Research that supports both CPU and GPU. As shown in Figure 2 below, Faiss performs vector similarity search by pre-building the index given a collection of vectors and efficiently indexing similar items to the query in RAM. Faiss provides various similarity search methods that span a wide spectrum of usage trade-offs and has excellent optimization under the hood. There are a number of exact and approximation search algorithms available in Faiss such as IVFFlat, IVFPQ, HNSW, etc.
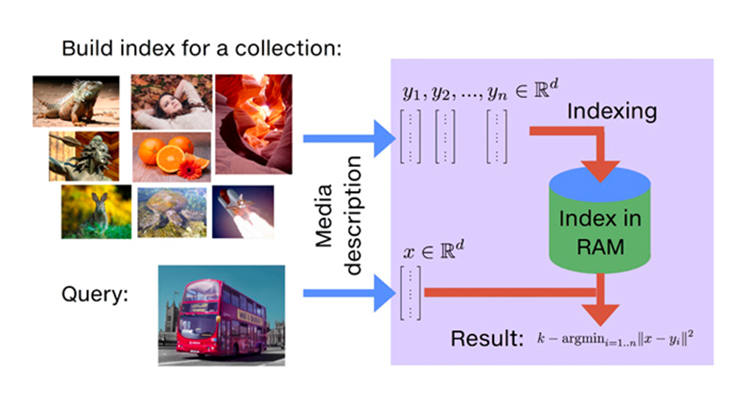
Figure 2: Vector Similarity Search Overview
Efficient distance computation between vectors is crucial for overall performance of vector search. Intel® Optimized Faiss makes heavy use of multi-threading (via OpenMP) to exploit multiple cores for parallel search. In the meantime, BLAS libraries are leveraged to perform distance computations via matrix multiplication, and SIMD vectorization instruction also greatly speeds up distance computations for isolated vectors. Additionally, AVX512 on Intel® Xeon executes operations for more data in one instruction and VNNI uses one instruction to implement multiply-accumulate operation for INT8 and INT16. Intel® AVX512 and Intel® Deep Learning Boost can bring even further throughput improvement for Faiss on Xeon platforms.
Part3 - Trials of Faiss on GPU at Yahoo! JAPAN Shopping
Our initial attempt tried to run Faiss on Nvidia V100 Tensor Core GPU for this task because the embedding models are trained on it and we use faiss-gpu to calculate the recall metrics of embeddings at the end of each training epoch. The training environment and a part of the executing codes can be applicable to the inference after the training.
However, our data is entirely stored on HDFS and we have to use pyarrow to read data from HDFS and write search results back to HDFS. The code segment and logic to combine Faiss and pyarrow is rather complicated because there are some parameters to be optimized such as batch size and the number of threads for Faiss and pyarrow respectively. In addition, there are many other factors to be considered, including the number of items for each category, the constraint of the consumable HDFS quota, the proper block size on HDFS, the number of GPU to be used to achieve relatively high utilization, etc. On the other hand, it is not feasible to separate the time cost of Faiss computation and HDFS I/O for performance analysis and optimization. Besides, our GPU resources are limited and allocated for other workloads (e.g. training tasks) and other in-house projects.
Spark is an efficient framework for processing large data on HDFS and Yahoo! JAPAN already has Hadoop/YARN clusters and runs Spark on them, thus we have switched over to BigDL and Spark with faiss-cpu to simplify and optimize the offline search stage.
Part4 - Faiss on Spark Solution with BigDL
Referring to the example use case provided in BigDL, our offline recall workload is now directly performed on the Hadoop/YARN cluster where HDFS locates. Every Spark executor runs one Faiss task and the task fully uses all the cores of this executor. Intel® optimized Faiss would utilize all the executor cores to do the search in parallel to achieve optimal performance. In such an implementation, Spark is used to read the data from HDFS, partition the data for each Faiss task and eventually write the search results back to HDFS as parquet files (as demonstrated in Figure 3).
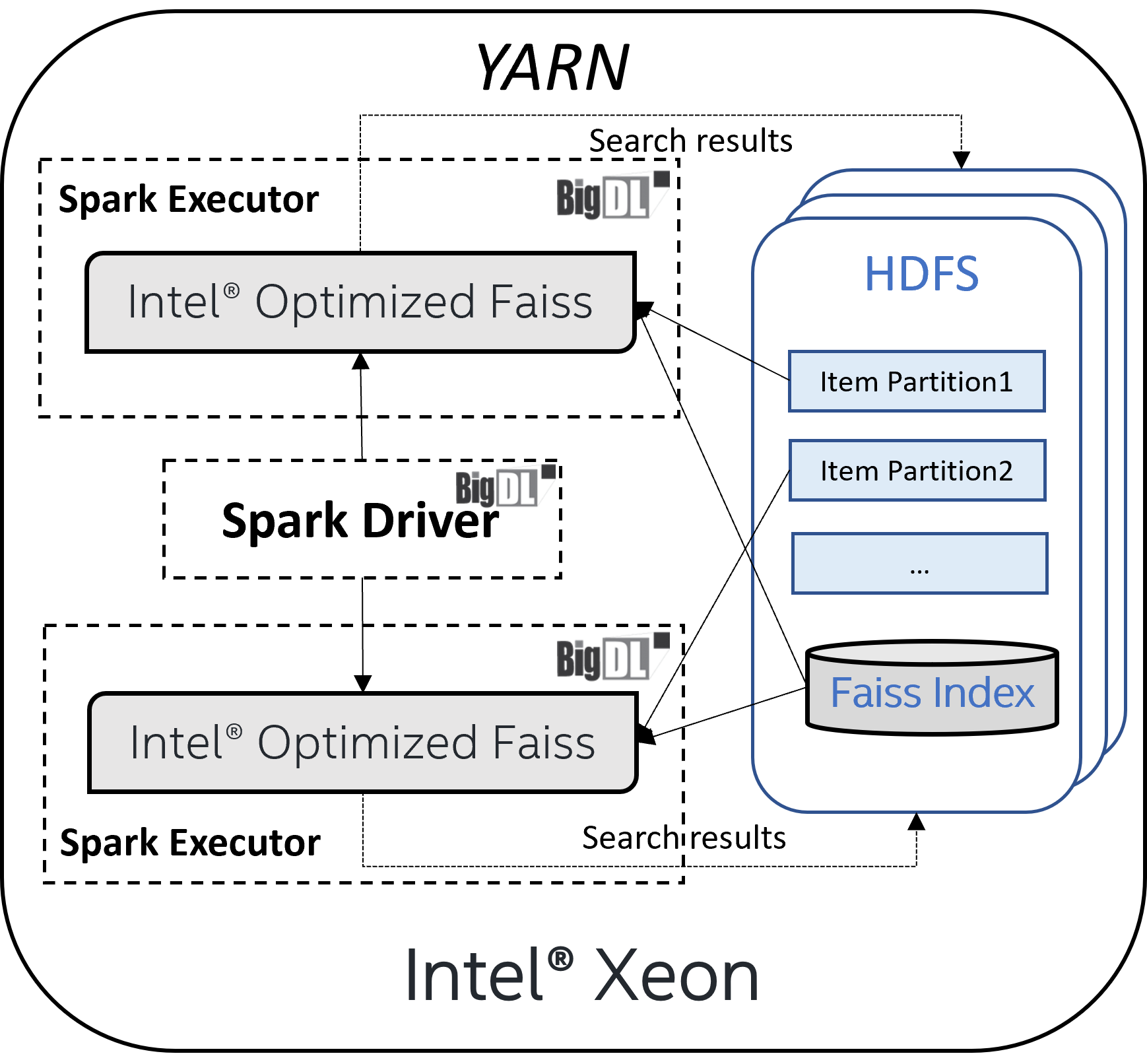
Figure 3: Intel® Optimized Faiss with BigDL and Spark Architecture
This solution unifies data I/O and computation in a single cluster and therefore makes it easier and more efficient to manage. Moreover, the solution could be easily scaled to large clusters of hundreds of nodes with minimum efforts. Below is some sample code snippet and you check here for the complete implementation.
def faiss_search(faiss_index_path, batch_size, top_k):
faiss_idx = faiss.deserialize_index(pickle.load(index_pkl))
def search(iter):
buffer = []
for item in iter:
if len(buffer) == batch_size:
similarity, idx = faiss_idx.search(buffer, k=top_k)
for i in range(batch_size):
seed_item = buffer[i]
for rank, (score, recommend_item) in enumerate(zip(similarity[i], idx[i])):
yield seed_item, recommend_item, rank, score
buffer = []
else:
buffer.append(item)
# Skip the part of handling the last incomplete batch
return search
embed_df = spark.read.parquet(path)
search_rdd = embed_df.rdd.mapPartitions(faiss_search(faiss_index_path, batch_size, top_k))
search_df = search_rdd.toDF()
search_df.write.mode("overwrite").parquet(output_path)
Part5 - Experimental Results
We demonstrated the performance of the similarity search on Spark based on the above BigDL implementation. To compare it with our GPU use case, we used a single-node 4 V100 GPU server and exploited the code segment running on our production system with faiss-gpu and pyarrow. As for the test dataset, we prepared 6 million 128 dimensional random vectors normalized by L2 norm and made a 'FlatIP' index since the embedding vectors in production are optimized through cosine similarity. The data size is based on our reference scale of items in a category. Measurement of the execution time is done for searching similar 200 items for each 6 million items and writing 1.2 billion rows down to HDFS for the production system. All the parameters are about the same as the case of Yahoo! JAPAN Shopping's recommender system for each item category.
The performance results of our experiments are shown in Figure 4 below. When using GPUs to run Faiss with 4 threads and 8 pyarrow threads, it took about 1 hour and 50 minutes to complete search and writing. For this experiment, we used the same parameters as in the production system without optimizing them. On the other hand, using 20 Spark executors and 4 cores per executor with the Faiss on Spark solution in BigDL, the whole process can be completed within half an hour. When 2 cores for each executors are used it took about 1 hour and so the scalability is quite good. In addition, the code structure is simpler and solid, so it would be suitable for long-term use.
The performance boost of 20 Spark executors and 4 cores against single-node 4 V100 (more than 3.5x speed up) is significant as we experiment and BigDL’s solution turns out to be efficient, scalable and easy to maintain.
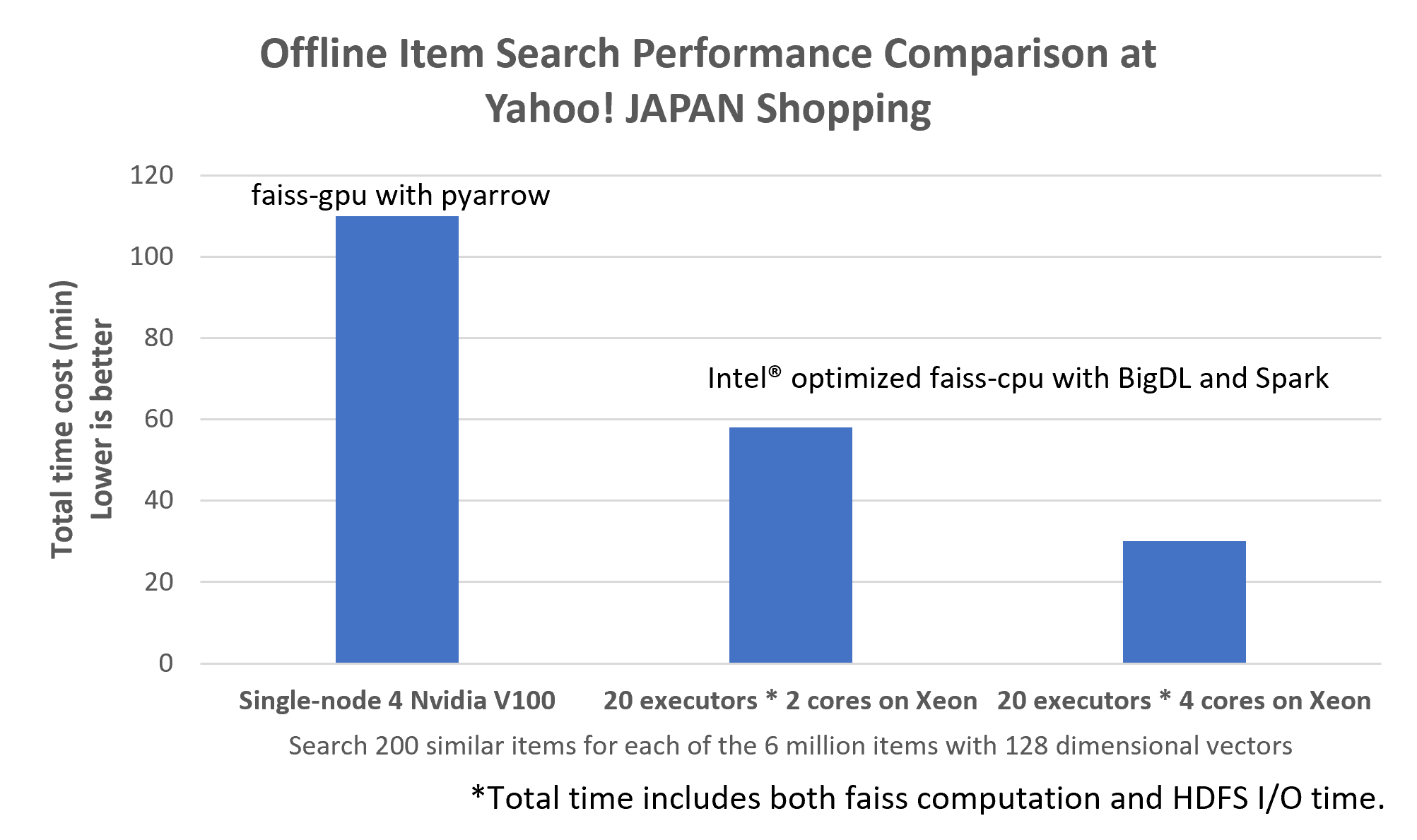
Figure 4: Offline Item Search Performance Comparison Results
Part6 - Conclusion and Future Work
In this blog, we share our practical experience in efficiently performing large-scale optimized Faiss using BigDL and Spark on Yahoo! JAPAN’s Hadoop/YARN cluster. Empirical results prove that this solution obtains satisfactory performance on our production data. Besides, the code and the parameters are quite simple and it improves maintainability for the production system. Don’t hesitate to check out the implementation here to scale your similarity search workloads :).
We are also attempting to use BigDL to seamlessly scale models in TensorFlow Recommenders (TFRS) to large clusters for listwise ranking in the offline item ranking stage after the recall stage. Using the BigDL Orca library, ETL, model training and inference tasks for deep learning workloads can be executed end-to-end on a single Spark cluster, which helps reduce the gap between ETL and training/inference for data-intensive workloads to a large extent. BigDL Orca not only supports running popular deep learning frameworks on Spark clusters, including TensorFlow and PyTorch, but also supports easily scaling additional libraries such as TFRS. Moreover, the data processing implementation for our initial attempt can be improved by BigDL Friesian, a library in BigDL for building large-scale end-to-end recommender systems.
Our initial results look quite good and with BigDL, all the tasks are combined into a single workload and could be easily migrated from the experiment environment to the production environment. BigDL does significantly speed up the development and productization of recall and ranking stages in the recommender system for Yahoo! JAPAN Shopping. We are glad to share our experience in applying large-scale data on TFRS with BigDL in the future.