Intel® Extension for TensorFlow* is a heterogeneous, high-performance, deep-learning extension plugin. This extension:
- is based on the TensorFlow Pluggable Device interface to bring Intel CPUs, GPUs, and other devices into the TensorFlow open source community for AI workload acceleration and;
- provides users to flexibly plug an XPU into TensorFlow showing the computing power inside Intel’s hardware and;
- up-streams several optimizations into open source TensorFlow.
Let’s look at it, including how you can use the extension to jumpstart your AI workloads.
What is Intel’s TensorFlow Extension?
The Structure
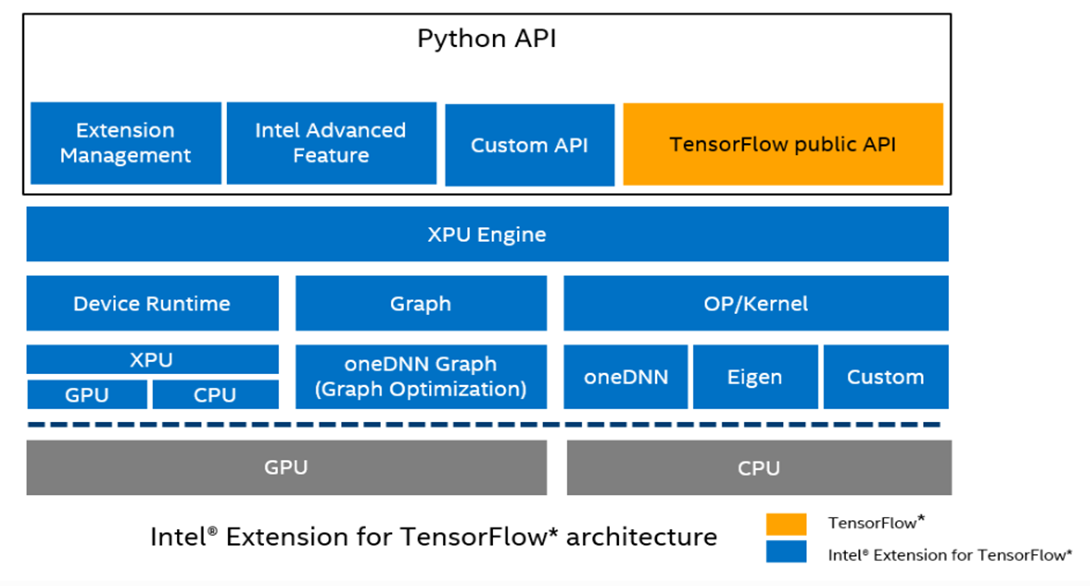
The Intel Extension for TensorFlow is exactly that: an extension of the stock, open source TensorFlow library that is uniquely optimized for high performance on Intel® Architecture. It is compatible with the stock TensorFlow public API; this allows developers to maintain the same experience as with the stock API with minimal code changes.
The extension includes:
- Custom API to extend the stock TensorFlow public API. The users can import and use the custom API under itex.ops namespace.
- Intel Advanced Feature and Extension Management which enables good performance without any code changes. In addition, simple front-end Python APIs and utilities can be used to increase performance. This can be done with minor code changes (~2-3 lines) for specialized application scenarios.
- XPU Engine that includes device runtime and graph optimization and brings Intel GPU into the TensorFlow community. This engine also provides deeper performance optimization on Intel CPU hardware. The user can install Intel GPU backend or CPU backend separately to satisfy different scenarios.
Features
Intel Extension for TensorFlow offers several features to get additional AI performance.
- Operator Optimization: Optimizes operators in CPU and implements all GPU operators with Intel® oneAPI DPC++/C++ Compiler. Operator optimization can be implemented by default without any additional settings. For more information, check Customized Operators.
- Graph Optimization: Helps to fuse specified op pattern to new single op for better performance, such as Conv2D+ReLU and Linear+ReLU. Users can implement this by default without any additional settings. For more detailed information, check Graph Fusion.
- Advanced Auto Mixed Precision (AMP): Uses lower-precision data types such as bfloat16 and float16 to make models run faster with less memory consumption during training and inference. The Extension is fully compatible with Keras mixed precision API in stock TensorFlow and provides an Advanced Auto Mixed Precision feature for better performance. For additional information, check Advanced Auto Mixed Precision.
- Ease-of-use Python API: Frontend Python APIs and utilities deliver additional performance optimizations which can be made with minor code changes for different kinds of application scenarios. For more detailed information, check Python APIs page and Environment Variables page.
-
GPU Profiler: To track the performance of TensorFlow models running on the Intel GPU. The profiler is enabled by three environment variables - export ZE_ENABLE_TRACING_LAYER=1, export UseCyclesPerSecondTimer=1 and export ENABLE_TF_PROFILER=1. For additional information, check GPU Profiler.
- CPU Launcher (Experimental): Setting configuration options properly contributes to a performance boost. However, there is no unified configuration that is optimal to all topologies. Users need to try different combinations. Intel Extension for TensorFlow provides a CPU launcher to automate these configuration settings, freeing users from complex work. For more detailed information, check CPU Launcher.
- INT8 Quantization: The Extension co-works with Intel® Neural Compressor to provide compatible TensorFlow INT8 quantization solution support with same user experience. For additional information, check INT8 Quantization.
- XPUAutoShard on GPU (Experimental): This feature is used to automatically shard the input data and the TensorFlow graphs. These shards are placed on GPU devices to maximize the hardware usage. For more detailed information, check XPUAutoShard.
- OpenXLA Support on GPU (Experimental): The extension adopts a uniform Device API PJRT as the supported device plugin to implement Intel GPU backend for OpenXLA experimental support. For additional information, check OpenXLA Support.
- TensorFlow Serving: This is designed by Google that acts as a bridge between trained machine learning models and the applications that need to use them. It streamlines the process of deploying and serving models in a production environment while maintaining efficiency and scalability. Install TensorFlow Serving with Intel® Extension for TensorFlow*. For more detailed information, check TensorFlow Serving.
Getting Started
Installation
Hardware Requirement:
Intel Extension for TensorFlow provides support for Intel GPU and Intel CPU.
Software Requirement:
|
Package |
CPU |
GPU |
XPU |
Installation |
|---|---|---|---|---|
|
Intel GPU driver |
|
Y |
Y |
|
|
Intel® oneAPI Base Toolkit |
|
Y |
Y |
|
|
TensorFlow |
Y |
Y |
Y |
Installation Channel:
Intel® Extension for TensorFlow* can be installed through the following channels:
- PyPI: XPU \ CPU
- DockerHub: XPU Container \ CPU Container
- Source: Build from source
For XPU:
Installation Commands:
pip install --upgrade intel-extension-for-tensorflow[xpu]
Find additional installation methods for XPU >
Environment check instructions:
bash /path to site-packages/intel_extension_for_tensorflow/tools/env_check.sh
For CPU (Experimental):
Installation Commands:
pip install --upgrade intel-extension-for-tensorflow[cpu]
Sanity check instructions:
python -c "import intel_extension_for_tensorflow as itex; print(itex.__version__)"
Code Example
This code sample will guide users how to run a TensorFlow inference workload on both GPU and CPU by using Intel® AI Analytics Toolkit. The following steps are implemented:
- Leverage the (resnet50 inference sample) from Intel Extension for TensorFlow
- Use the resnet50v1.5 pretrained model from TensorFlow Hub
- Inference with images in Intel Caffe GitHub
- Use different conda environment to run on Intel CPU and GPU
- Analyze oneDNN verbose logs to validate GPU or CPU usage
Try out the code sample on the Intel® Developer Cloud and Jupyter Notebook. Check out other examples that demonstrate the usage of Intel Extension for TensorFlow.
What’s Next?
Learn about feature information and release downloads for the latest and previous releases of Intel Extension for TensorFlow on GitHub and feel free to contribute to the project. We also encourage you to check out and incorporate Intel’s other AI/ML Framework optimizations and end-to-end portfolio of tools into your AI workflow and learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel’s AI Software Portfolio to help you prepare, build, deploy, and scale your AI solutions.