Deep learning has revolutionized AI; however, the trustworthiness and robustness of the models remain open challenges. For instance, when a model is exposed to data it hasn’t observed before, it often makes inaccurate and overconfident predictions, such as when an overturned school bus is misclassified as a snowplow or a tiger is misclassified as a person — both with very high confidence. Deep learning models are also vulnerable to cleverly crafted adversarial attacks, imperceptible to the human eye, that can prevent models from predicting correctly. When a model is deployed in the real world, these flaws can lead to catastrophic results. Standard deep learning models don’t provide uncertainty estimates, which are essential to establishing trust in model predictions.
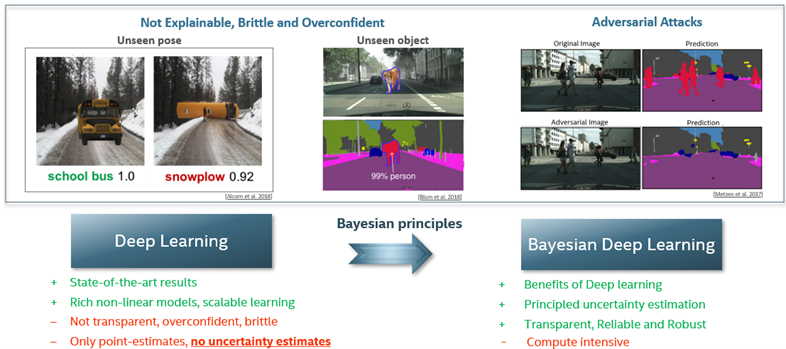
Bayesian deep learning mitigates the flaws of brittle and overconfident standard deep learning models. [1][2][3]
Obtaining reliable and accurate quantification of uncertainty estimates from deep neural networks is important in safety-critical applications. A well-calibrated model should be accurate when it’s certain about its prediction and indicate high uncertainty when it’s likely to be inaccurate. Uncertainty calibration is a challenging problem as no ground truth is available for uncertainty estimates. In a paper I’ve co-authored with fellow Intel researcher Omesh Tickoo, we propose a solution: an optimization method that leverages the relationship between accuracy and uncertainty as an anchor for uncertainty calibration.
But first, let’s talk about how Bayesian deep learning works and why it’s critical to creating trustworthy and reliable AI systems.
What is Bayesian Deep Learning?
Bayesian Deep Learning (BDL) combines the strengths of Bayesian probability theory with deep learning and enables uncertainty estimation in deep neural networks. BDL models enable you to build robust, trustworthy AI systems, opening the door for broader adoption of AI in high-stakes applications such as healthcare, finance, and autonomous driving.
Bayesian neural networks offer a probabilistic interpretation of deep learning models by learning probability distribution over neural network weights, such as Gaussian distribution during model training. In contrast, parameters in conventional neural networks are represented with deterministic point estimates. During inference, multiple forward passes through the neural network are required while performing Monte Carlo sampling over the weights. The resulting model can be considered as an ensemble of stochastic neural networks, enabling two types of uncertainty estimation:
- Aleatoric uncertainty, or input or data uncertainty, captures the noise inherent in the observation.
- Epistemic uncertainty captures what the model does not know when interpreting the model parameters and helps to improve the model as it observes new data.
Uncertainty Estimation in Deep Learning
Uncertainty estimation in deep neural networks is a crucial aspect of model interpretation and reliability. It provides a measure of the model's confidence in its predictions, which is particularly important in various tasks such as classification, regression, and semantic segmentation. In classification tasks, uncertainty estimation can help in understanding the model's confidence in assigning a particular class label. For regression tasks, it can provide an interval estimate around the predicted value, indicating the possible range within which the true value may lie. In semantic segmentation, which involves classifying each pixel in an image, uncertainty estimation can provide a measure of confidence for the classification of each pixel.
Classification
Conventional deep learning models don’t capture principled uncertainty estimates. Though they provide softmax probability in classification tasks, it is the relative probability that an input is in a given class relative to the other classes. These models do not capture complete predictive uncertainty to represent the model’s overall reliability. Uncertainty estimates help to establish trust in the AI system for informed decision-making. For instance, the image shows a model yielding a low uncertainty score when it predicts the input image correctly and a high uncertainty score when it predicts incorrectly.
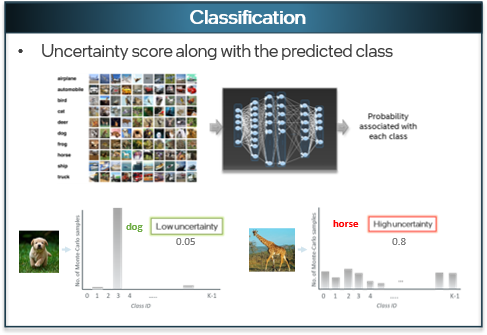
A classification model trained with multiple categories of data, producing an uncertainty score associated with the prediction. [4]
Regression
In a regression model trained to predict CO2 concentration levels in 20 years, a standard neural network provides point-estimate prediction. A Bayesian neural network predicts a variance along with the average mean, considering the many environmental changes that may happen in the distant future.
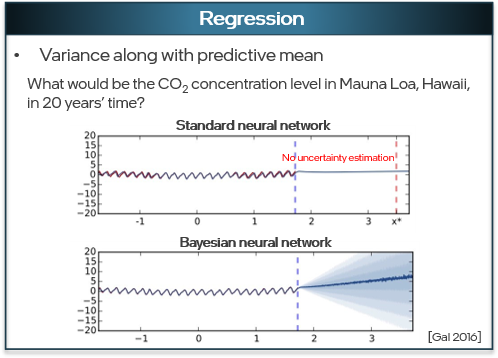
Two regression models compare the results of a standard neural network and a Bayesian neural network predicting CO2 concentration trends. [7]
Semantic Segmentation
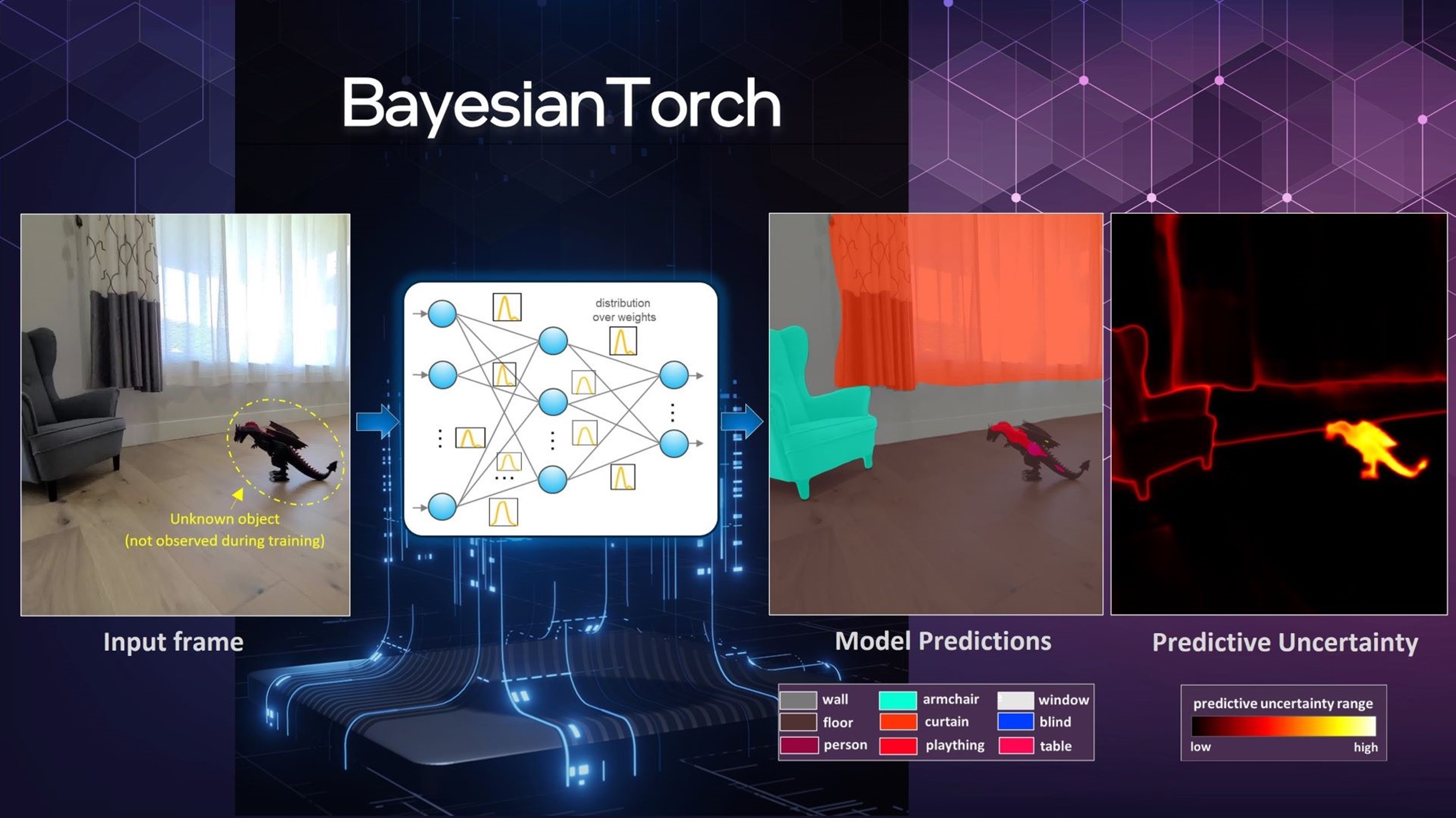
In a semantic segmentation model, Bayesian models can capture pixel-level uncertainty estimates that can provide additional context around the model’s decisions. When novel objects are observed, a conventional model misclassifies them. In contrast, uncertainty-aware models flag these novel objects (epistemic), and objects far away from the viewpoint (aleatoric), with high uncertainty.
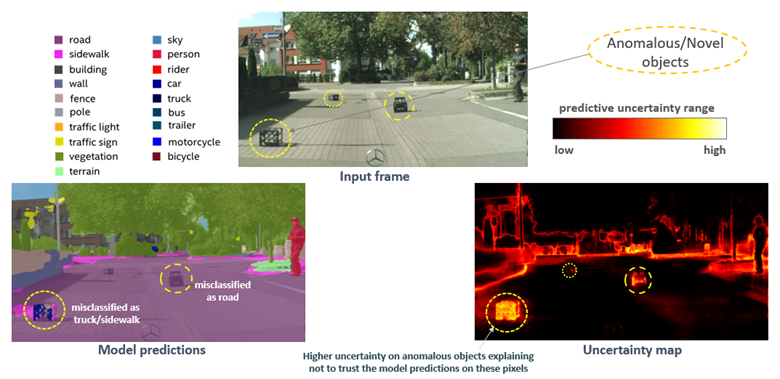
Credits: The input frame image is from the Fishyscapes Dataset [2]. The predictions and uncertainty map are generated by the author’s Bayesian-Torch models.
Uncertainty estimates in semantic segmentation models flag novel and ambiguous objects.
Creating the Foundation for Robust, Trustworthy AI
By enabling uncertainty estimation in deep neural networks, Bayesian models help advance many important objectives and capabilities towards safer, robust, and trustworthy AI, such as:
- Reliability and transparency: BDL models can express what they “do not know” through uncertainty estimates, which guide AI practitioners in deciding what level of trust to afford a prediction, forming the basis for creating trustworthy and explainable AI systems.
- Robustness: In real-world settings, deployed models face distribution shift challenges arising from non-stationary environments as the observed data evolve from training data distribution and models encounter novel data. BDL models offer robustness to distributional shifts by detecting out-of-domain data.
- Principled sensor fusion: BDL enables multimodal fusion by harnessing uncertainty estimates, and fallback to reliable modes of sensing backed by the mathematically grounded Bayesian framework.
- Agility and adaptiveness: Bayesian models enable active and continual learning, an important factor in helping models remain accurate, safe, and adaptive in a rapidly evolving world.
These capabilities require efficient computation. We have enabled low-precision optimizations to run BDL workloads efficiently on Intel AI platforms.
A Framework for Seamless Bayesian Model Development
Intel Labs has released Bayesian-Torch, an open source framework built on top of PyTorch, to address the lack of scalable development tools for BDL models in PyTorch. For example, Google offers TensorFlow Probability, but there’s no framework to build Bayesian models in PyTorch. With Bayesian-Torch, developers can seamlessly convert a deep learning neural network model of any architecture to be uncertainty-aware using simple APIs. Bayesian-Torch is the first framework to support low-precision quantization of BDL models for efficient inference and is widely used by research and developer communities.
Bayesian-Torch offers various Bayesian layers that replace the standard PyTorch layer, including linear, convolutional, and long short-term memory (LSTM) layers. The framework allows faster convergence of stochastic variational inference scalable to larger models by specifying weight priors and transfer learning with the Empirical Bayes approach. We provide different Monte Carlo estimators, such as reparameterization and flipout. A Bayesian linear layer, for example, is wrapped with a PyTorch linear layer and additional weight sampling to create stochastic outputs.
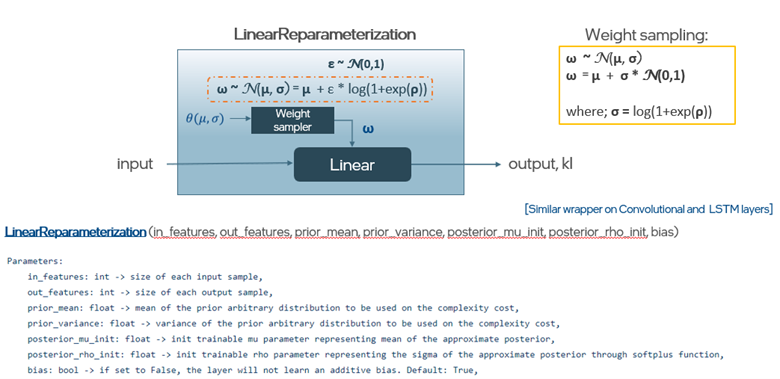
Illustration of the LinearReparameterization layer in Bayesian-Torch
How to Use Bayesian-Torch
The sections below describe how to install Bayesian-Torch, create and train a model, and compare the performance of two different models.
Installation
You can easily install Bayesian-Torch directly from the Python Package Index (PyPI) using the command ‘pip install bayesian-torch’.
Create a Model
Once you’ve installed Bayesian-Torch, you can use simple, high-level APIs to implement each Bayesian layer you need to replace existing Python layers in your model architecture. For instance, use the dnn_to_bnn() API to convert a ResNet-50 neural network to Bayesian ResNet-50 with just one line of code. Specify the prior parameters for Bayesian layers—such as the μ and σ for the Gaussian distribution, the initialization for the model parameters, and what type of Monte Carlo estimator you want to use (flipout method or reparameterization trick) — and the API will seamlessly convert a deep neural network (DNN) to a Bayesian neural network. Here’s an example:
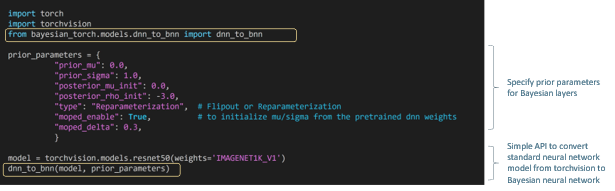
Once you specify prior parameters, the dnn_to_bnn() API will convert a torchvision model like ResNet-50 to a Bayesian neural network with one line of code.
Train a Model
Similar to training a deep neural network, a Bayesian model uses a primary loss, such as CrossEntropyLoss. The framework offers the get_kl_loss() API for obtaining the Kullback-Leibler (KL) divergence in the model to compute the evidence lower bound, enabling the training process to happen similarly to standard neural network training, as shown in the example below.
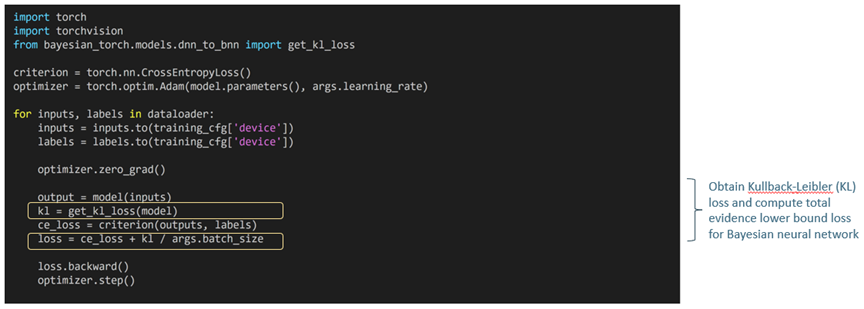
Training a Bayesian neural network model is similar to training a deep neural network, except for the requirement to add a Kullback-Leibler divergence.
Model Inferencing and Uncertainty Estimation
Once you’ve trained your model, you’ll perform Monte Carlo sampling, which requires multiple forward passes in which you run the model multiple times. The Monte Carlo estimation produces a stochastic predictive distribution. Bayesian-Torch provides utility functions to compute different types of uncertainty estimations, including aleatoric, epistemic, or total predictive uncertainty from the predictive distribution. An example of computing uncertainty metrics using APIs is shown below.
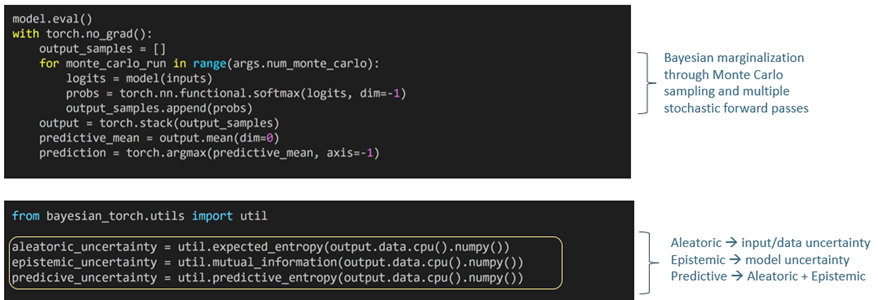
After you perform multiple forward passes (top frame), you can choose which type of uncertainty estimate you want using Bayesian-Torch APIs (bottom frame).
A Simple Example: Regression
Let’s compare two simple regression models. Both models use a two-layer architecture, but the first uses deterministic weights. In contrast, the second uses Bayesian layers, such as linear reparameterization with stochastic weights represented by a Gaussian distribution. The Bayesian layers enable the model to quantify uncertainty estimates along with the prediction. As you can see, the Bayesian model is confident about the prediction where it has observed data but is highly uncertain where the model has not observed data. We can update the model when new data is observed so the model’s accuracy can continually improve.

While both regressor models comprise two layers, the Bayesian-enabled layers in the bottom code snippet empower the model to deliver uncertainty estimates.
Use Case: Medical Application (Colorectal Histology Diagnosis)
In this high-stakes application of colorectal histology diagnosis, selective prediction based on uncertainty estimates could potentially improve the decision-making process. The medical practitioner could rely on the model’s automated decision for predictions with low uncertainty, while cases with high uncertainty are routed to a doctor for closer review.
A standard deep neural network produced overconfident results, yielding low uncertainty and failing to distinguish when the model was correct or incorrect. The Bayesian deep neural network yielded reliable uncertainty estimates, which serve as an explainability tool, achieving a 78% improvement [5] in referral rate efficiency compared to a standard neural network model, as shown below.
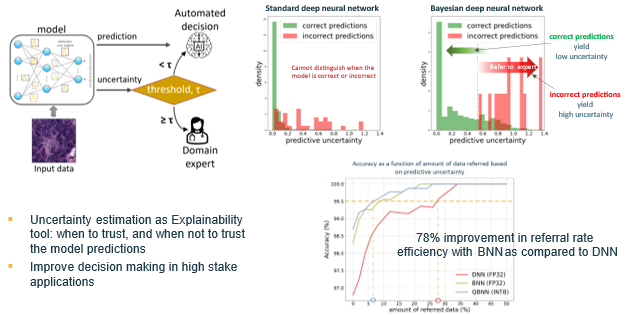
A Bayesian neural network yields reliable uncertainty estimates compared to a standard neural network.
Accounting for Distributional Shifts
Once deployed in the real world, there’s a possibility that a model will encounter data not included in the training distribution data. It’s important for models to be robust to adjust to these distributional shifts. To yield reliable uncertainty estimates even under distributional shift, we introduced an optimization method, ‘accuracy versus uncertainty calibration’ (AvUC), built upon theoretically sound Bayesian decision theory.
We tested standard deterministic models and Bayesian neural network model variants to evaluate performance when encountering common data shifts, including illumination changes, weather conditions, and sensor degradation noise. In the box plot comparing the uncertainty calibration error (UCE) as a function of increasing data shift intensity, the UCE increases for the vanilla deterministic model. In contrast, the Bayesian models produce lower UCE, indicating that the model is more reliable and robust. Similarly, the Bayesian deep learning models achieved state-of-the-art performance for out-of-distribution detection and dataset shift detection, indicating that Bayesian models can detect when a domain shift is happening, so you can update your models or adapt them accordingly.
Read about the results in our paper, Improving model calibration with accuracy versus uncertainty optimization.
Open source code is available on GitHub.
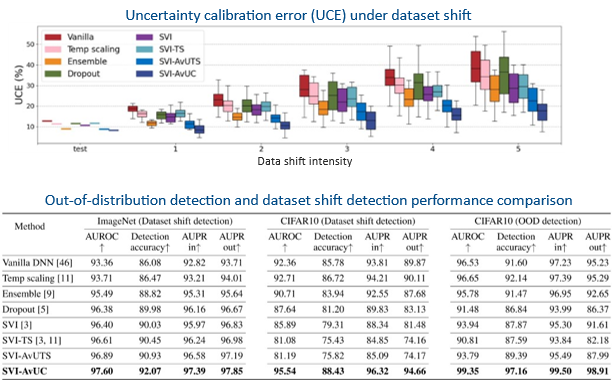
Bayesian models offer robustness to distributional shifts, providing reliable uncertainty estimates under distribution shifts and outperforming in data shift detection. [6]
Advancing Real-World Benchmarks
Benchmarking tools serve as a driving force behind the advancements in deep learning research. A lack of large-scale benchmarking tools was impeding the development of Bayesian deep learning, so in collaboration with the University of Oxford, Intel supported the development of an open source BDL-benchmarks tool to evaluate different uncertainty estimation methods on real-world tasks such as diabetic retinopathy diagnosis. The BDL benchmarks code base was merged with Google’s Uncertainty Baselines repo, an open source tool for comparing uncertainty estimation methods.
Developing Efficient Computing Systems for BDL Models
To deliver the efficient computing systems needed for BDL, we have developed a quantization framework in Bayesian-Torch to enable low-precision optimizations for BDL models, and algorithmic optimization for efficient uncertainty quantification. We have also introduced an Empirical Bayes method for efficient training convergence of BDL models and enabled scalable Bayesian inference for larger model architectures.
Low-precision Optimization
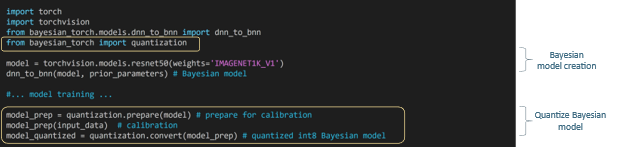
Quantization is a technique for reducing the precision of the weights, biases, and activations, resulting in reduced memory consumption and fast inference through low-precision computation. Model deep learning frameworks, including TensorFlow and PyTorch, do not natively support the quantization of Bayesian neural networks due to their unique and intricate computations. We introduced a comprehensive quantization framework for BDL in our paper Quantization for Bayesian Deep Learning: Low-Precision Characterization and Robustness, published at the 2023 IEEE International Symposium on Workload Characterization. The quantization layers and modules are available in open source Bayesian-Torch through user-friendly high-level APIs for ease of use. For instance, if you’re working with a ResNet-50 model, you can convert to a Bayesian model and train and quantize the model using the Bayesian-Torch APIs shown in the example below.
Evaluation of model performance and robustness to data shift on ImageNet-C
Get Involved
Uncertainty estimates are an essential foundation for building the robust, transparent, and trustworthy AI systems of the future. To bring the benefits of Bayesian deep learning and uncertainty estimates to real-world use cases, including high-stakes applications such as healthcare, finance, and autonomous driving, we must combine software and hardware enhancements to enable more efficient compute systems. The first step is engagement with the open source community to encourage wider adoption of BDL technology.
For more information, explore the Bayesian-Torch GitHub repo, where you can learn more about the key features of Bayesian-Torch, how to install it, and find some examples that show you how to train and evaluate some example models.
About the Author
Ranganath Krishnan, Senior Staff Research Scientist AI/ML, Intel Labs
Ranganath Krishnan is a research scientist at Intel focused on probabilistic machine learning and developing trustworthy, robust, and adaptive AI systems. His research focus includes Bayesian deep learning, uncertainty-aware ML, data-centric AI, active learning, and continual adaptive AI in computer vision and natural language understanding. Ranganath has published more than 15 papers in these areas at top-tier AI/ML conferences including NeurIPS, AAAI, ICCV, and CVPR.
References
[1] Strike (with) a Pose: Neural Networks Are Easily Fooled by Strange Poses of Familiar Objects - Michael A. Alcorn, Qi Li, Zhitao Gong, Chengfei Wang, Long Mai, Wei-Shinn Ku, Anh Nguyen: Auburn University, Adobe Inc.
[2] The Fishyscapes Benchmark: Measuring Blind Spots in Semantic Segmentation - Hermann Blum, Paul-Edouard Sarlin, Juan Nieto, Roland Siegwart Cesar Cadena of the Autonomous Systems Lab, ETH Zurich
[3] Universal Adversarial Perturbations Against Semantic Image Segmentation - Jan Hendrik Metzen Bosch Center for Artificial Intelligence, Robert Bosch GmbH, Mummadi Chaithanya Kumar, University of Freiburg, Thomas Brox, University of Freiburg, Volker Fischer Bosch Center for Artificial Intelligence, Robert Bosch GmbH.
[4] Learning Multiple Layers of Features from Tiny Images, Alex Krizhevsky, 2009.
[5] Quantization for Bayesian Deep Learning: Low-Precision Characterization and Robustness - Jun-Liang Lin, The Pennsylvania State University, Intel, Ranganath Krishnan, Intel, Keyur Ruganathbhai Ranipa, Intel, Mahesh Subedar, Intel, Vrushabh Sanghavi, Intel, Meena Arunachalam, AMD, Omesh Tickoo, Intel, Ravishankar Iyer, Intel, Mahmut Taylan Kandemir, The Pennsylvania State University
[6] Improving model calibration with accuracy versus uncertainty optimization - Ranganath Krishnan, Intel Labs, Omesh Tickoo Intel Labs
[7] Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning – Yarin Gal and Zoubin Ghahramani, University of Cambridge, 2016