By Louie Tsai and Niharika Maheshwari
Introduction
Optimizations from Intel® oneAPI AI Analytics Toolkits and multi-node training enablement improved the performance of the rotoscoping AI workload from Laika, and the training time was reduced from 23 hours to less than three hours. These optimizations helped the customer shorten the development cycle and train their model within one workday.
The performance analysis and measurement on AWS are presented in the article
You can apply similar optimizations to other workloads to improve the performance of your AI applications.
Rotoscoping–Motivation and Problem Statement
The article “How movie studio Laika and Intel are revolutionizing stop-motion animation with AI”, published by Fast Company, explains the problems and solutions well. We cite fragments of this article to explain the motivation and problem statement.
The article includes the following:
Movie production studio Laika animates films “by seamlessly blending the tactical artistry of stop-motion with technological advancements including CGI and 3D printing.”
The puppets used in Laika’s films have a wide range of facial expressions created by 3D printing. In Missing Link alone, more than 106,000 faces were printed in pieces (i.e., lower and upper parts of a face). It’s a useful process in controlling how a character’s face moves, but it also creates a visible seam that shows where the various lower and upper pieces connect.
Much like Photoshop, RotoPainting involves isolating and removing unwanted items from a scene, such as puppet rigs or seam lines. While effective, it’s also incredibly time consuming.
During production of its Oscar-nominated film Missing Link, the technology and visual effects teams developed a prototype of an AI tool in collaboration with Intel … to knock that [RotoPaining task] down by 50%.
Figure 1 shows how the AI tool removes the seam lines

Figure 2 shows an overview of the AI tool. We mine the ground truth dataset for landmark points (used to train the landmark model) and shapes (used to train the shape model). Our tool loads a sequence of images, accompanied by a rough crop of the face, and feeds them into the landmark model. Then the resulting inferred landmark points are fed into the shape model to produce the roto shapes.
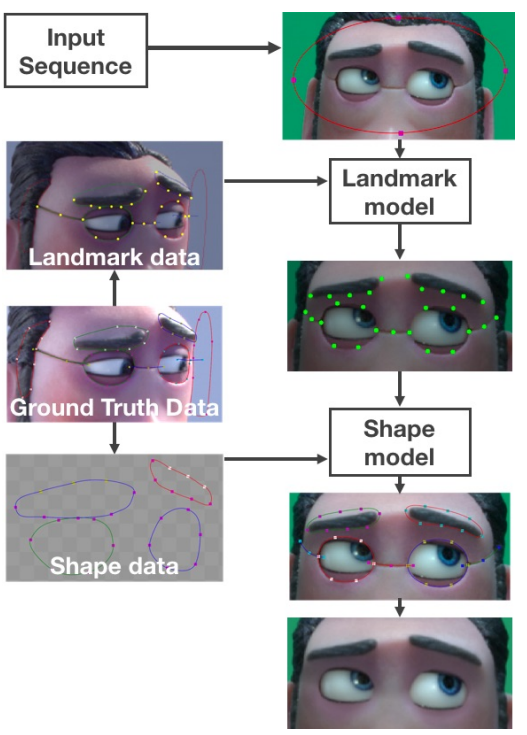
Improving Landmark Model Training Efficiency Using Intel® AI Software on AWS
AWS configuration
We used the AWS m5n.24xlarge, m6i.24xlarge, and c6i.24xlarge instance types for performance measurement.
All instance types have 96 vCPUs and two sockets. Both m5n.24xlarge and m6i.24xlarge have 384 GB of memory, but c6i.24xlarge only has 192 GB of memory.
M5n.24xlarge instances use the 2nd Generation Intel® Xeon® Scalable processors, and both m6i.24xlarge and c6i.24large instances use the 3rd Generation Intel® Xeon® Scalable processors.
Single node performance optimization
Point model (landmark model) training takes around 23 hours by using the official TensorFlow* (stock TensorFlow) release v2.4. The long training time impacts the development cycle of the rotoscoping pipeline.
First, we trained the point model using Intel® TensorFlow* with oneAPI Deep Neural Network Library (oneDNN) optimizations, and then analyzed the performance by using Intel® VTune™ Profiler to further tune the performance.
Intel® VTune™ Profiler identified a non-uniform memory access (NUMA) remote access issue on the AWS 24xlarge two-socket system. Figure 3 shows that 41% of memory accesses are on remote NUMA nodes, and high remote NUMA access rate impacts training performance.
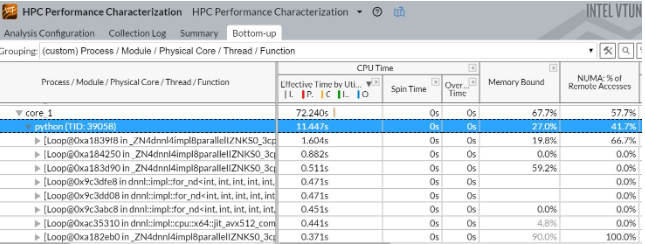
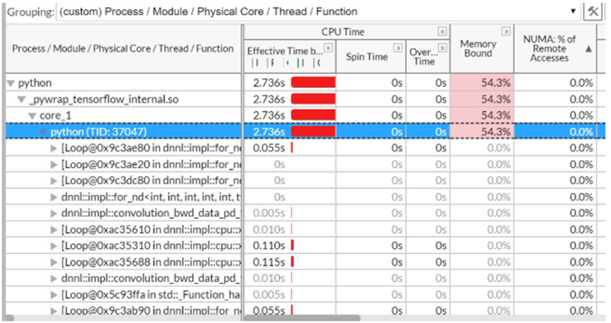
Figure 4 shows that no NUMA remote access issues occur when all training threads run on the same socket.
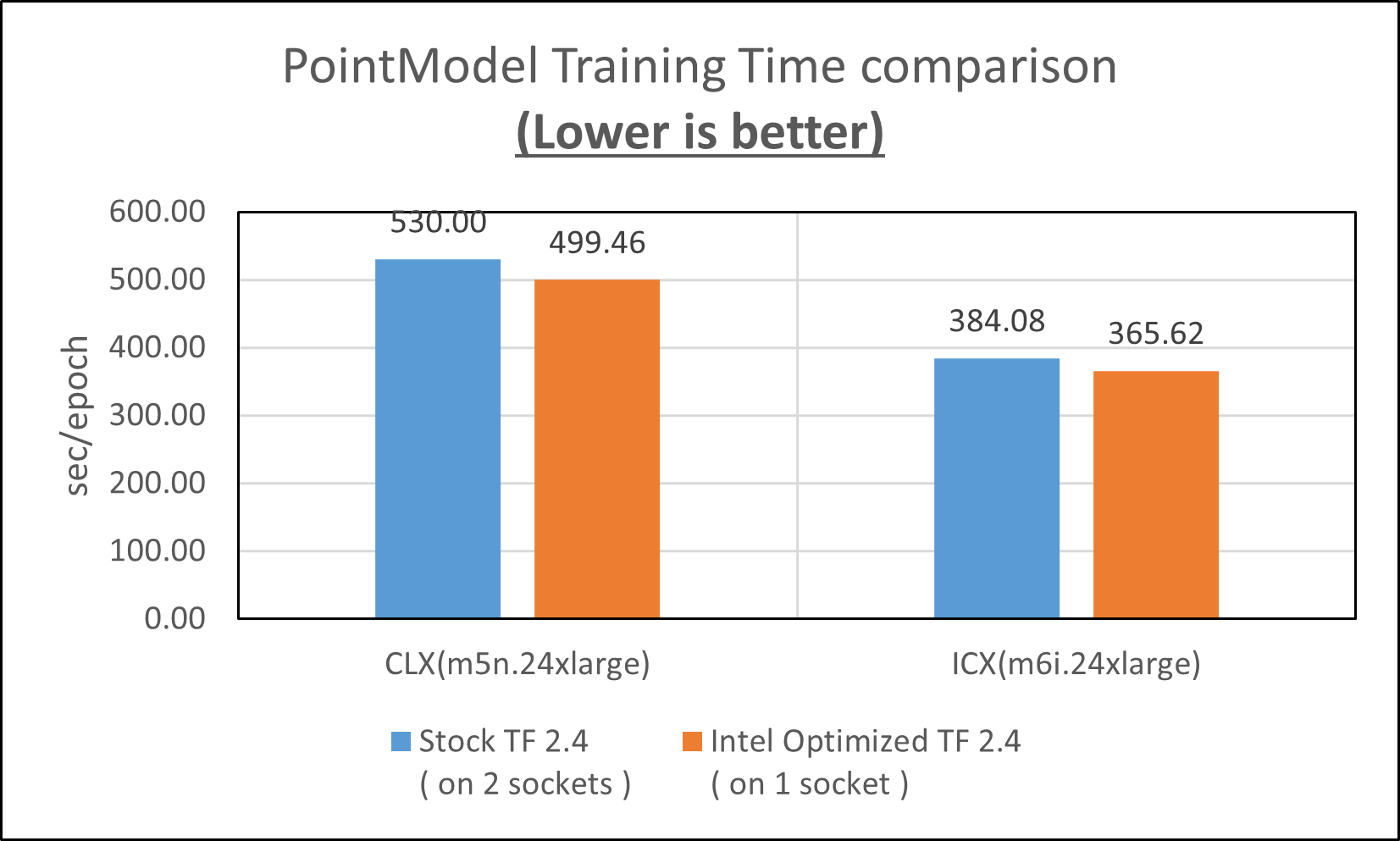
Without the NUMA remote access problem, the point model took less time to finish training on Intel® TensorFlow* even with half of the CPU cores compared to training with stock TensorFlow* as shown in Figure 5.
To utilize two sockets on the 24xlarge instance, we enabled Horovod. This framework distributed the point model training between two Horovod instances, one instance per socket to train half of the training dataset. By doing this data parallelism with Horovod, all CPU cores over two sockets can be utilized without the remote NUMA access problem.
The training time is further reduced on both m5n.24xlarge (CLX) and m6i.24xlarge (ICX) instance types as shown in Figure 6.
We use the intel/intel-optimized-tensorflow:2.4.0-ubuntu-20.04-mpi-horovod container image from Intel oneContainer here, so all the necessary packages including Horovod with Open MPI are installed in this container environment. This Horovod container image is crucial for multi-node training deployment, so you do not need to re-configure the software environment for every node.
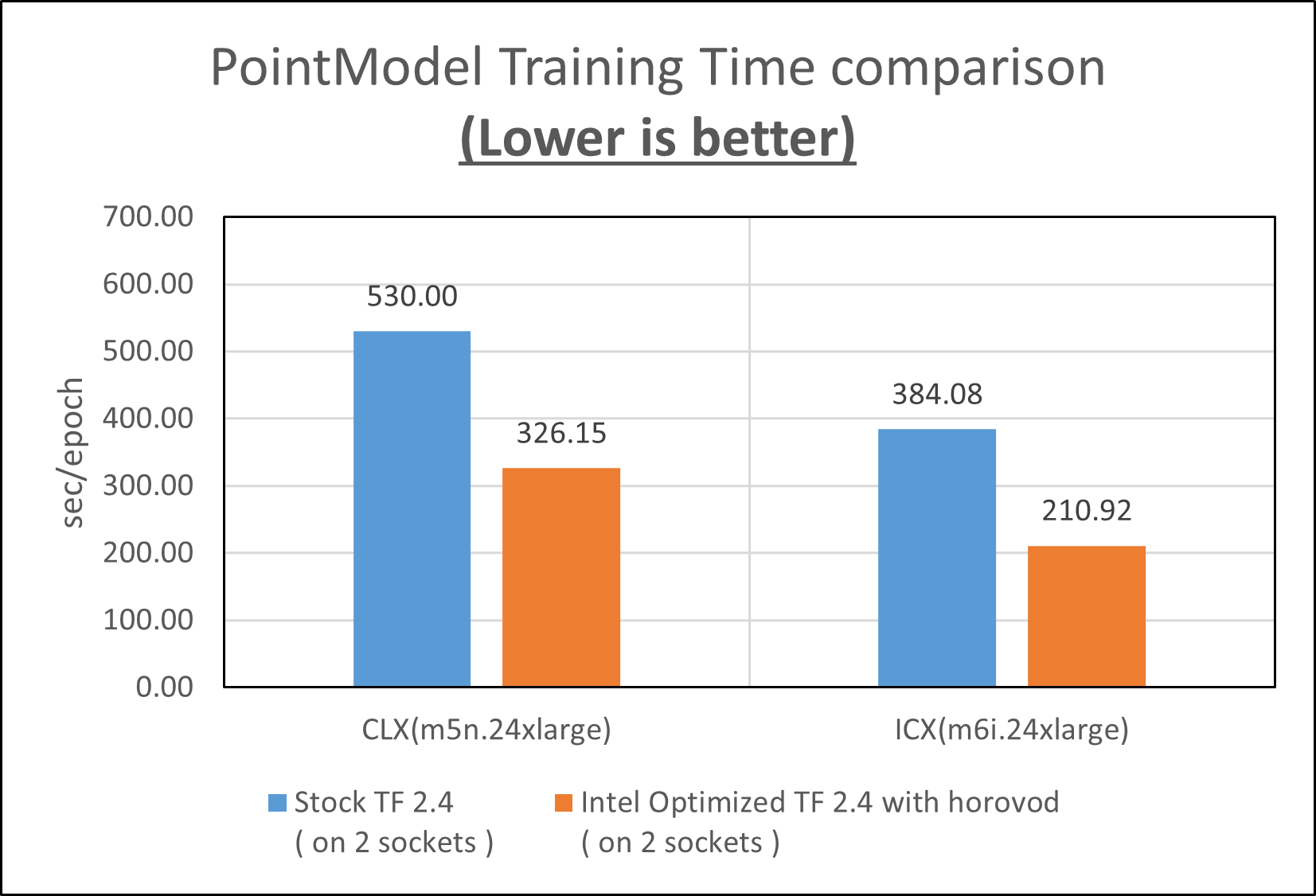
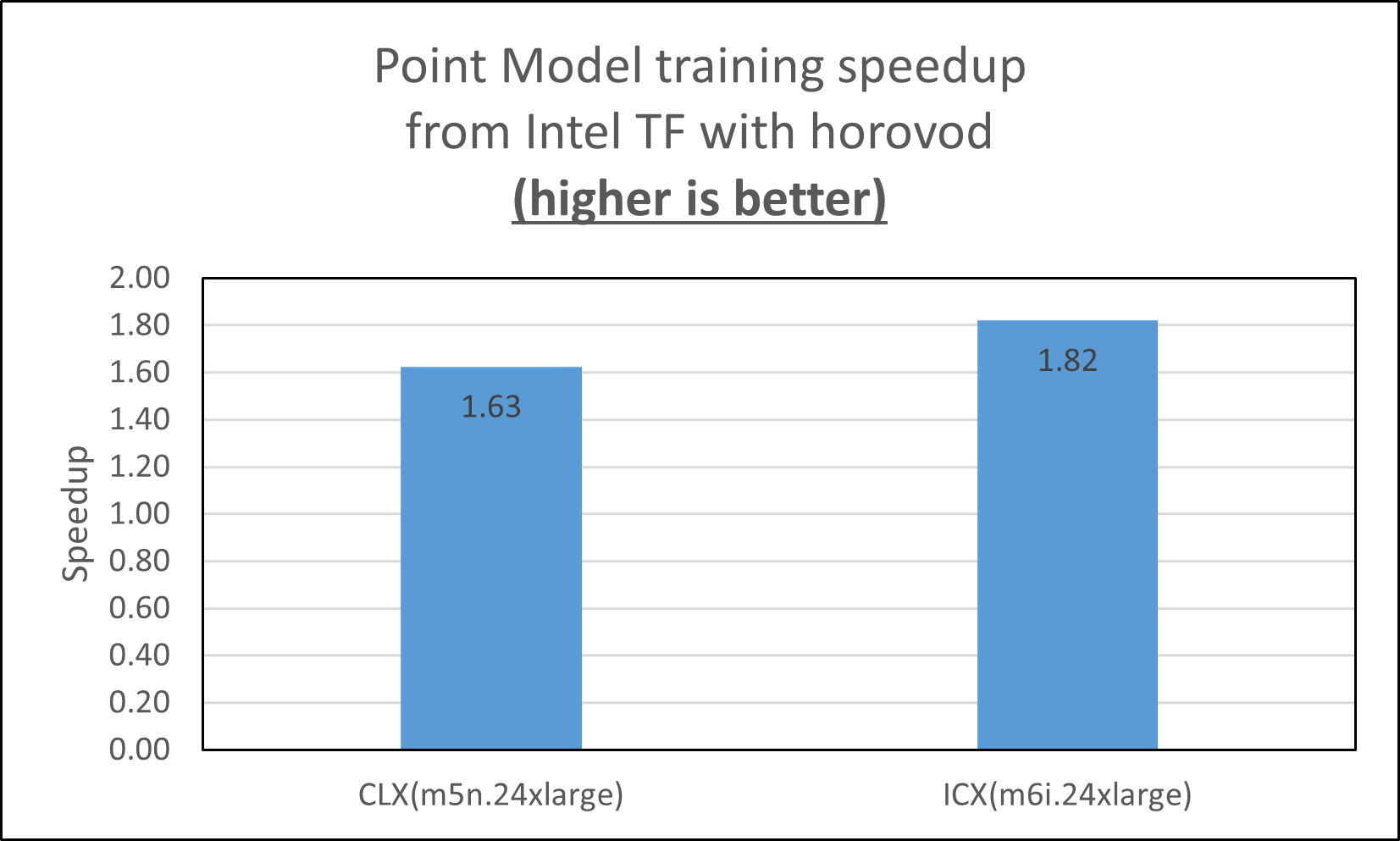
Overall, Horovod and Intel® Optimization for TensorFlow* speed up point model training by 1.6X on the m5ni.24xlarge instance type and by 1.8X on the m6i.24xlarge instance type.
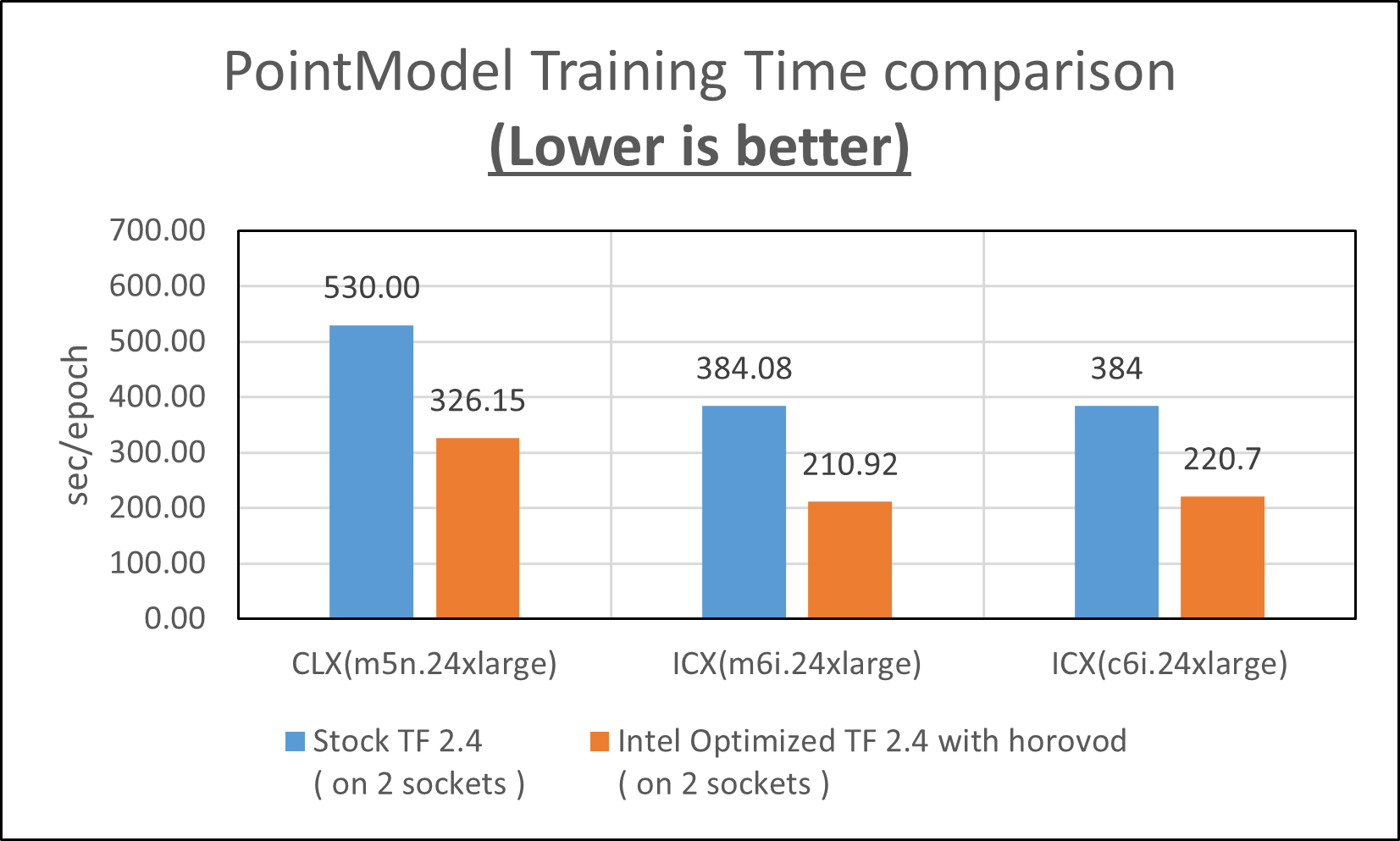
The point model is a memory bound workload as shown in Intel® VTune™ profiling results. So the c6i.24xlarge instance type with 192 GB of memory demonstrates a small performance drop compared to the m6i.24xlarge instance types with 384 GB of memory. However, the optimized point model still has 1.74X speedup on the c6i.24xlarge instance type with less memory.
Multi-node performance optimization
By running the optimized point model on multiple nodes with the c6i.24xlarge instance type, the training time is further reduced from 220 sec/epoch to 50 sec/epoch with eight c6i.24xlarge instances as shown in Figure 9.
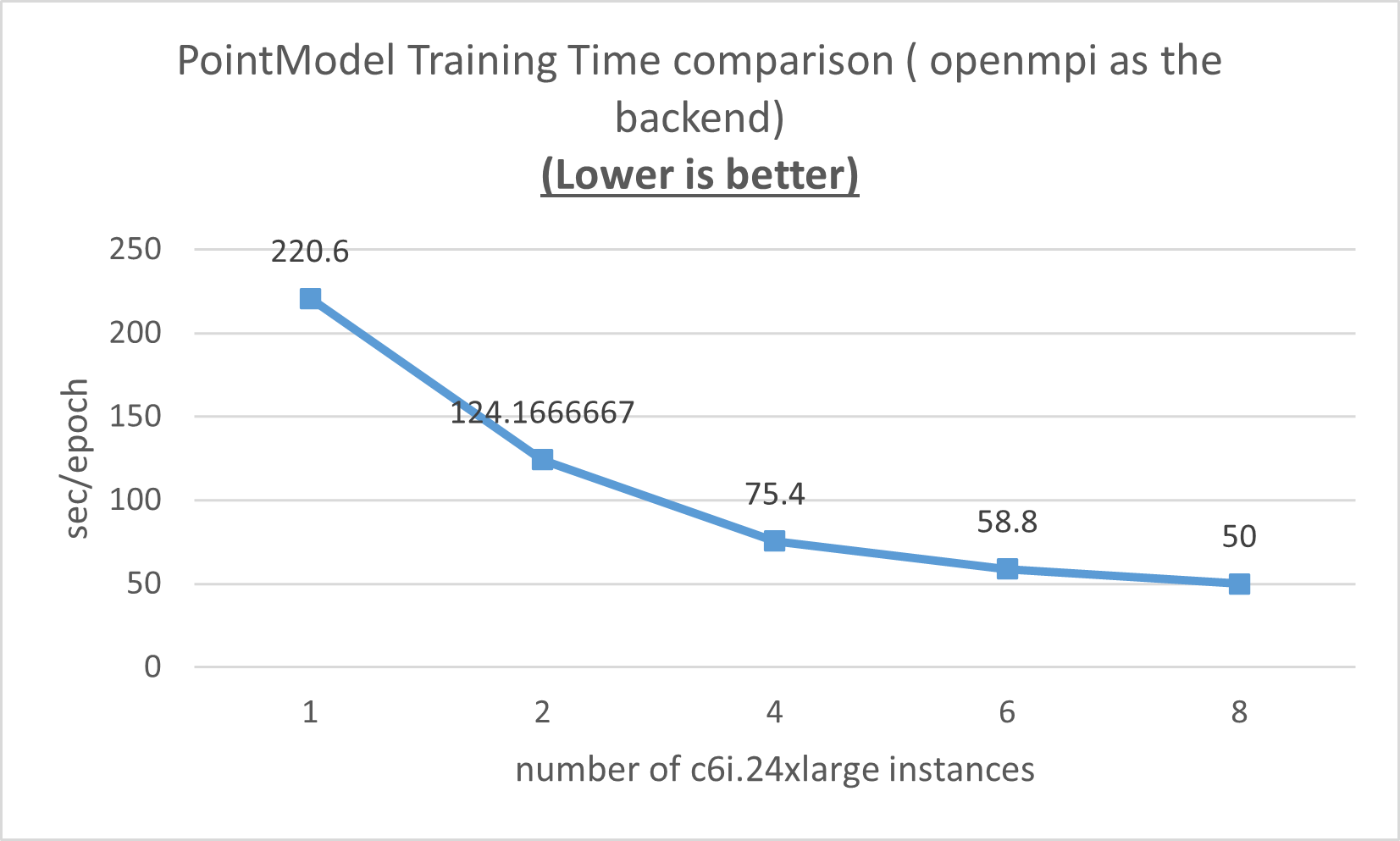
Overall, we saw more speedup when we increased the number of the c6i.24xlarge instances as shown in Figure 10.
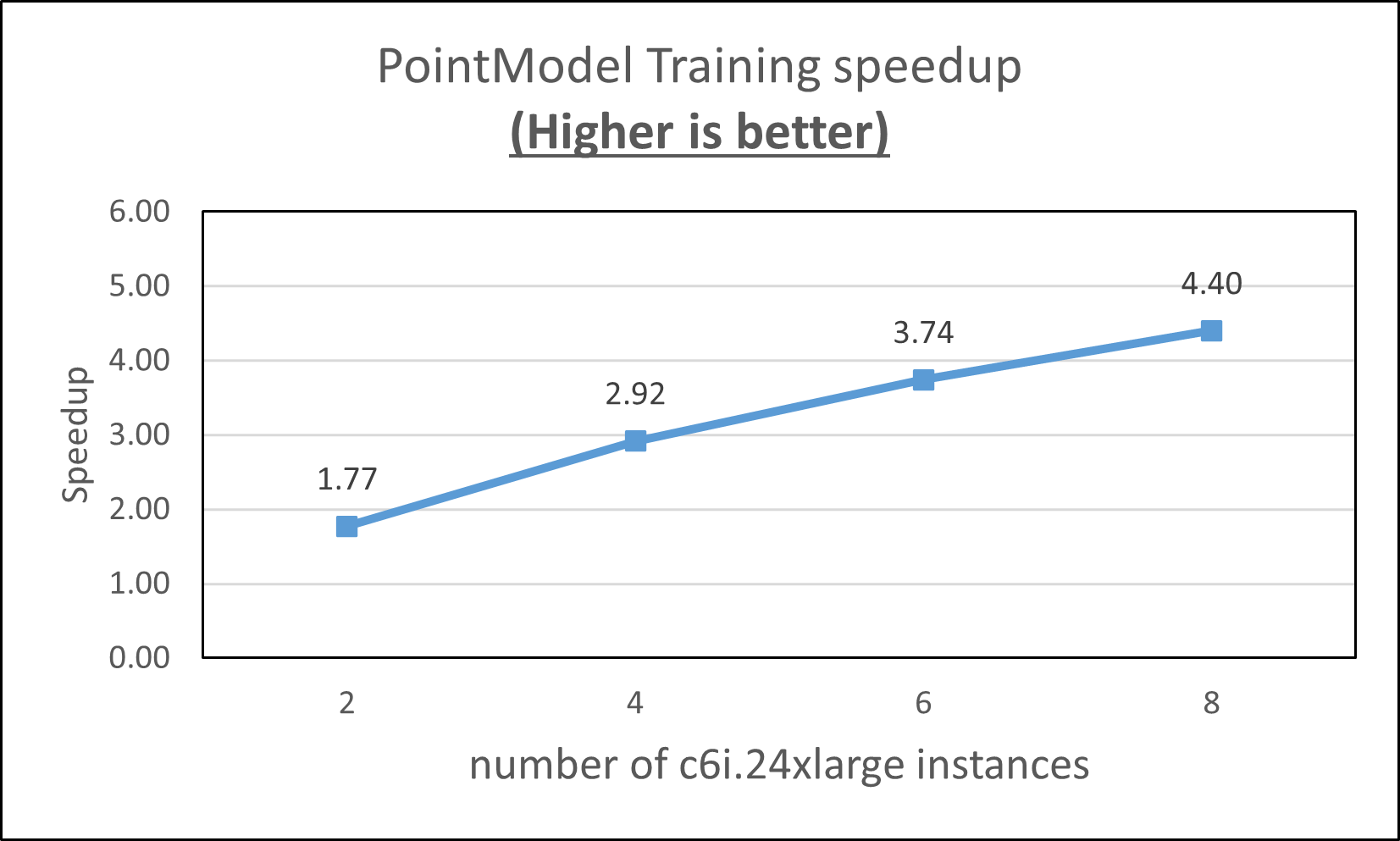
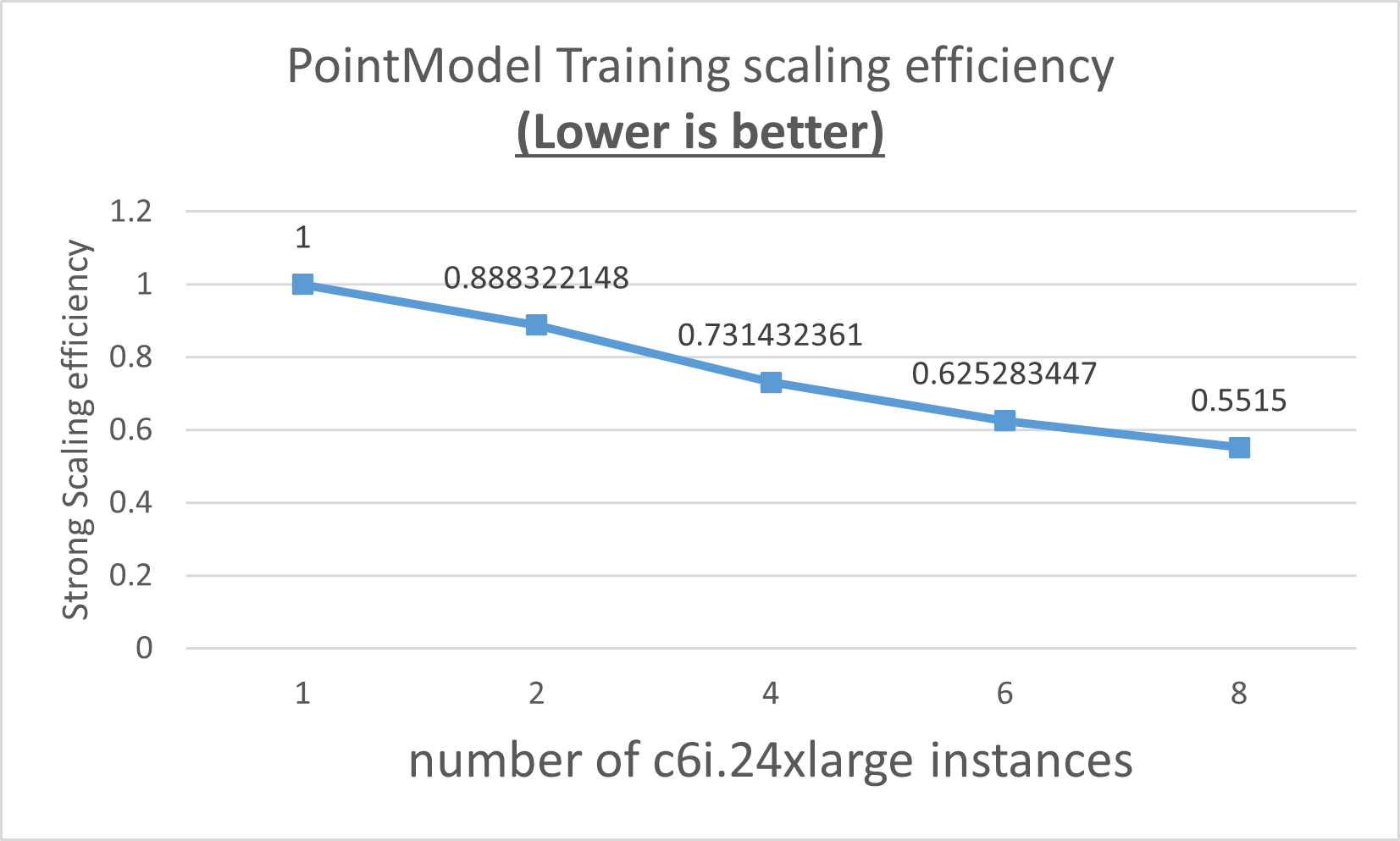
However, the strong efficiency drops when the number of c6i.24xlarge is increased.
The strong efficiency performance issue might be caused by Open MPI as the Horovod communication backend. As the next step, we plan to improve the strong efficiency by changing the Horovod backend from Open MPI to Intel® oneAPI Collective Communications Library (oneCCL).
Conclusion
By adopting Intel® Optimization for TensorFlow* from Intel® oneAPI AI Analytics Toolkit and enabling Horovod using Intel® oneContainer image, the training time of point model is reduced from 23 hours to less than 3 hours on AWS c6i.24xlarge instances. This effort helps the customer shorten the development cycle and train a model within one workday.
The same optimizations could be applied to other deep learning training workloads to avoid remote NUMA access within one system with multiple sockets and to scale out the training among multiple nodes.
Intel® oneAPI AI Analytics Toolkit is a good start for optimizing your AI workloads. Not only the deep learning pipeline but also the machine learning and data analysis pipeline could be further optimized through Intel® oneAPI AI Analytics Toolkit.