At Intel Vision 2022 last May, Habana launched its second-generation deep learning processor, Gaudi2* (Figure 1), which significantly increases training performance. It builds on the high-efficiency, first-generation Gaudi architecture to deliver up to 40% better price-to-performance on AWS* EC2 DL1 cloud instances and on-premises in the Supermicro Gaudi AI Training Server. It shrinks the process from 16nm to 7nm, increases the number of AI-customized Tensor Processor Cores from 8 to 24, adds FP8 support, and integrates a media compression engine. Gaudi2’s in-package memory has tripled to 96 GB of HBM2e at 2.45 TB/s bandwidth. These advances give higher throughput compared to the NVIDIA* A100 80G on popular computer vision and natural language processing models (Figures 2 and 3).

Figure 1. Gaudi2* architecture.
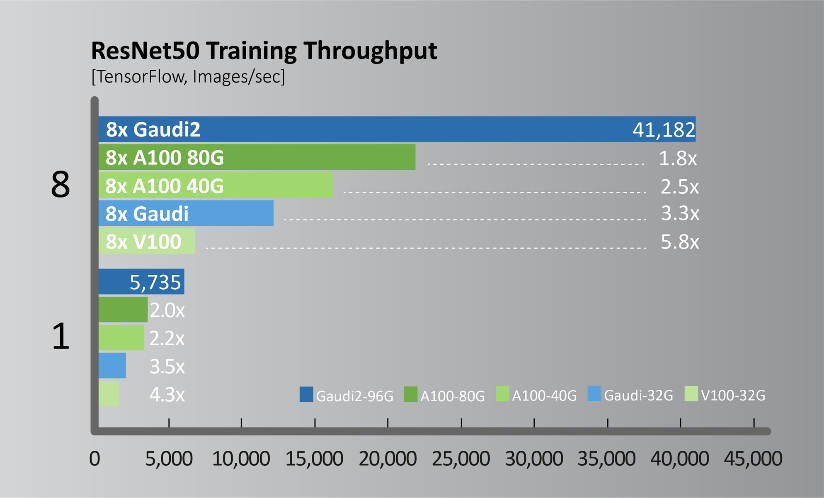
Figure 2. ResNet50 training throughput comparisons.
Test configuration: https://github.com/HabanaAI/Model-References/tree/master/TensorFlow/computer_vision/Resnets/resnet_keras. Habana SynapseAI* Container: https://vault.habana.ai/ui/repos/tree/General/gaudi-docker/1.6.0/ubuntu20.04/habanalabs/tensorflow-installer-tf-cpu-2.9.1. Habana Gaudi* Performance: https://developer.habana.ai/resources/habana-training-models. Results may vary. NVIDIA* A100/V100 performance source: https://ngc.nvidia.com/catalog/resources/nvidia:resnet_50_v1_5_for_tensorflow/performance, results published for DGX A100-40G and DGX V100-32G.
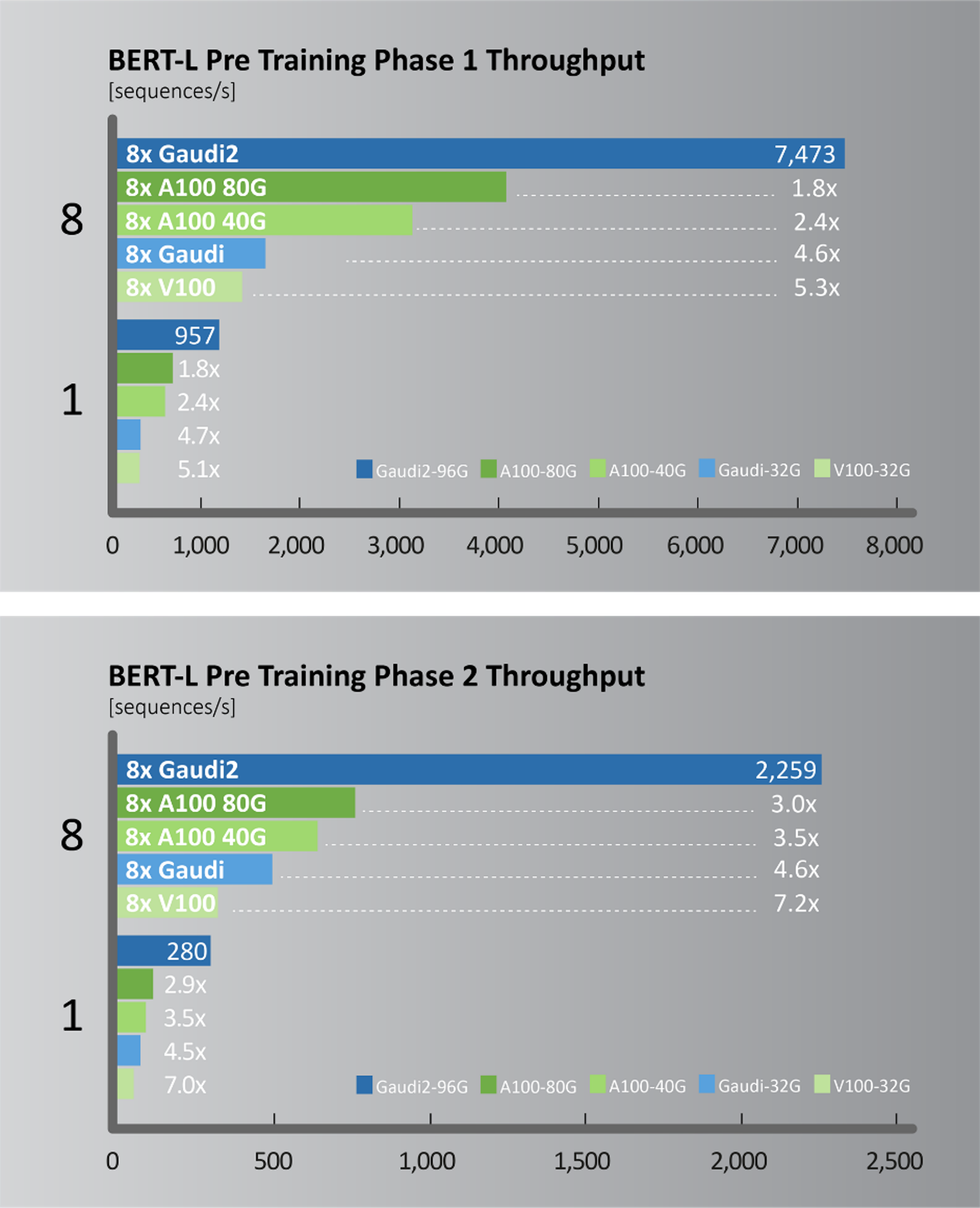
Figure 3. BERT-L pretraining phase 1 and 2 throughput comparisons.
Test configuration: A100-80GB: Measured by Habana on Azure* instance Standard_ND96amsr_A100_v4 using single A100-80GB with TF docker 22.03-tf2-py3 from NGC (Phase-1: Seq len=128, BS=312, accu steps=256; Phase-2: seq len=512, BS=40, accu steps=768). A100-40GB: Measured by Habana on DGX-A100 using single A100-40GB with TF docker 22.03-tf2-py3 from NGC (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=16, accu steps=2048). V100-32GB: Measured by Habana on p3dn.24xlarge using single V100-32GB with TF docker 21.12-tf2-py3 from NGC (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=8, accu steps=4096). Gaudi2*: Measured by Habana on Gaudi2-HLS system using single Gaudi2 with SynapseAI TF docker 1.5.0 (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=16, accu steps=2048). Results may vary.
Habana has made it cost-effective and easy for customers to scale out training capacity with the integration of 24 100-gigabit RDMA over Converged Ethernet (RoCE2) ports on every Gaudi2, an increase from ten ports on the first-generation Gaudi. Twenty-one ports on every Gaudi2 are dedicated to connecting to the other seven processors in an all-to-all, non-blocking configuration within the server (Figure 4). Three of the ports on every processor are dedicated to scale out, providing 2.4 terabits of networking throughput in the 8-card Gaudi server, the HLS-Gaudi2. To simplify customers’ system design, Habana also offers an 8-Gaudi2 baseboard. With the integration of RoCE on chip, customers can easily scale and configure Gaudi2 systems to suit their deep learning cluster requirements, from one to 1,000s of Gaudi2s. With system implementation on industry-standard Ethernet, Gaudi2 enables customers to choose from a wide array of Ethernet switching and networking equipment, enabling added cost-savings. And the on-chip integration of the networking interface controller ports lowers component count and total system cost.

Figure 4. Gaudi2 network configuration.
Gaudi2, like its predecessor, supports developers with the Habana SynapseAI* Software Suite, optimized for deep learning model development and to ease migration from GPU-based models to Gaudi hardware (Figure 5). It integrates TensorFlow and PyTorch* frameworks and 50+ computer vision and natural language processing reference models. Developers are provided documentation and tools, how-to content, a community forum, and reference models and model roadmap on the Habana GitHub repository. Getting started with model migration is as easy as adding two lines of code. For expert users programming their own kernels, Habana offers the full toolkit. SynapseAI supports training models on Gaudi2 and inferencing them on any target, including Intel® Xeon® processors, Habana Greco*, or Gaudi2 itself. SynapseAI is also integrated with ecosystem partners, such as Hugging Face with transformer model repositories and tools, Grid.ai Pytorch Lightning*, and cnvrg.io MLOps software.
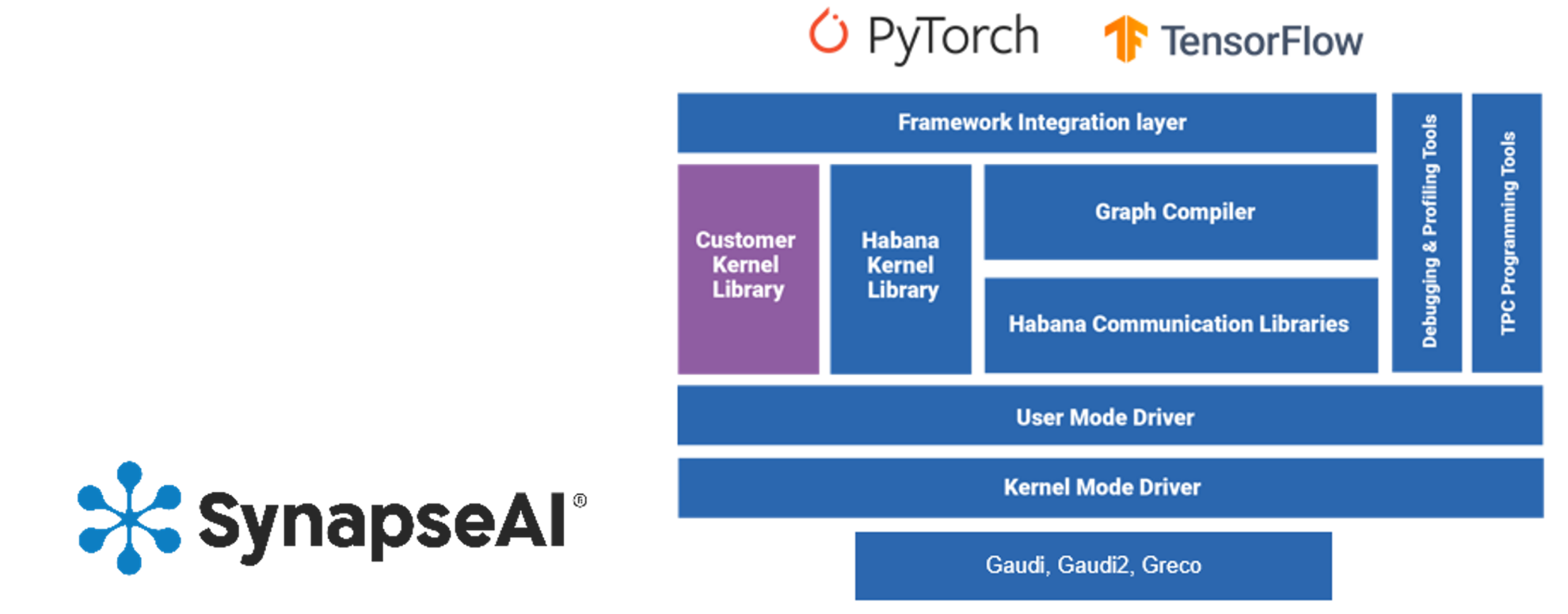
Figure 5. Simplified model building and migration with the Habana SynapseAI* Software Suite.
Ten days after the launch of Gaudi2, the Habana team submitted performance results for June publication in the MLPerf industry benchmark. The Gaudi2 results show dramatic advancements in time-to-train, resulting in Habana’s May 2022 MLPerf submission outperforming NVIDIA’s A100-80G submission for 8-card server for both the vision (ResNet-50) and language (BERT) models (Figures 6 and 7). For ResNet-50, Gaudi2 achieved a significant reduction in time-to-train of 36% vs. NVIDIA’s submission for A100-80GB and 45% reduction compared to Dell’s submission cited for an A100-40GB 8-accelerator server that was submitted for both ResNet-50 and BERT results. Compared to its first-generation Gaudi, Gaudi2 achieves 3x speed-up in training throughput for ResNet-50 and 4.7x for BERT. These advances can be attributed the numerous hardware and software advances over Gaudi.
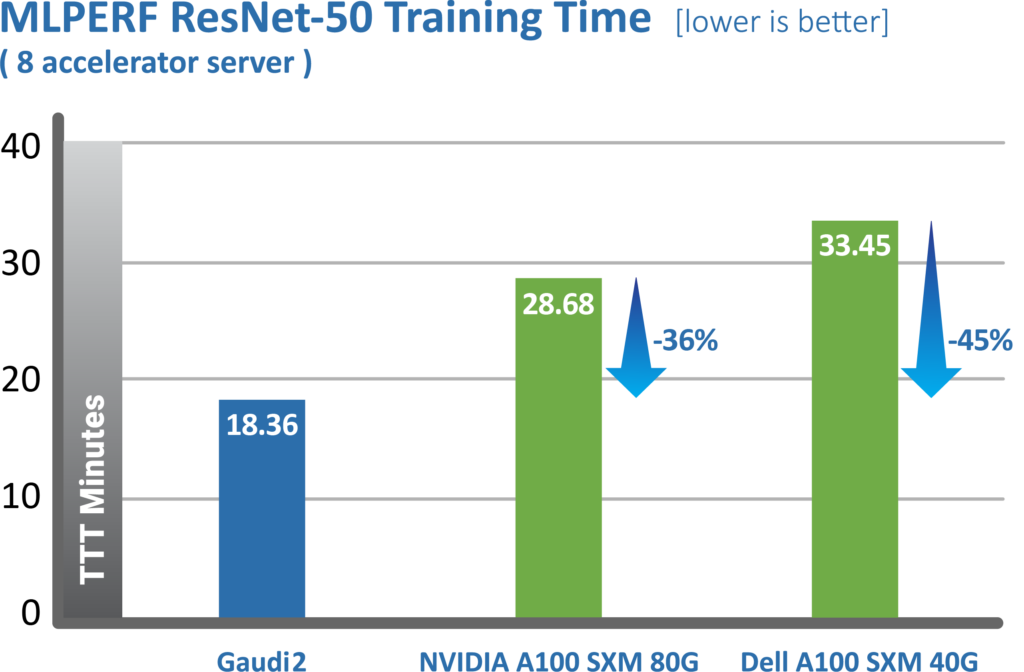
Figure 6 MLPerf results for ResNet-50 training.
Source: https://mlcommons.org/en/training-normal-20/ (June 2022).
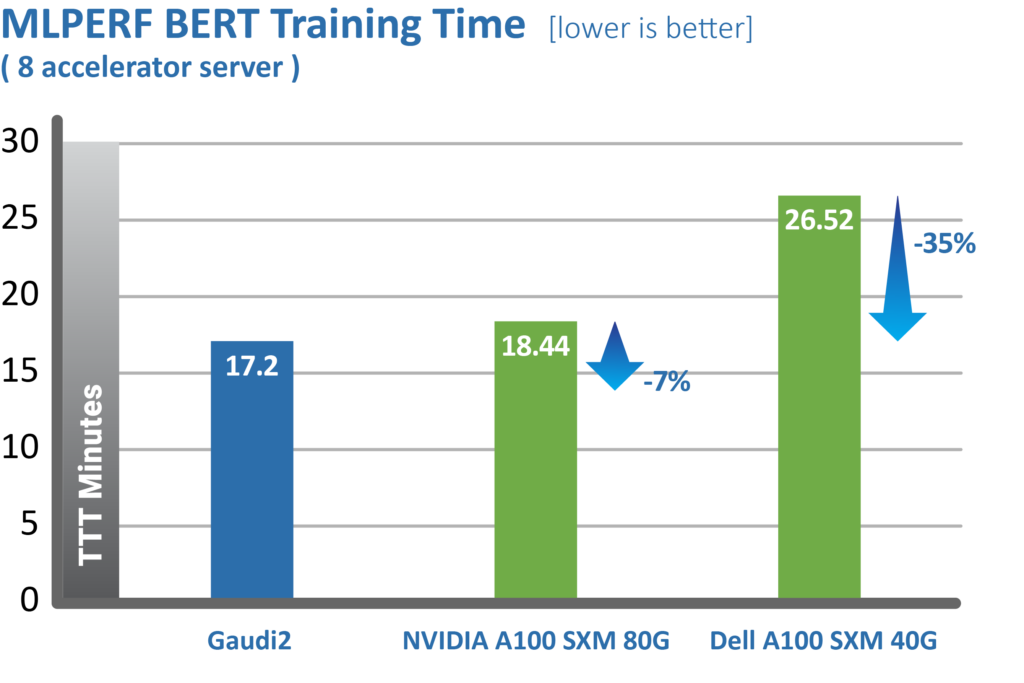
Figure 7. MLPerf results for BERT training.
Source: https://mlcommons.org/benchmarks/training/ (June 2022).
The performance of both generations of Gaudi processors is achieved without special software manipulations that differ from Habana’s commercial software stack available to its customers, out of the box. As a result, customers can expect to achieve MLPerf-comparable results in their own Gaudi or Gaudi2 systems using Habana’s commercially available software. Both generations of Gaudi were designed at to deliver exceptional deep learning efficiency, so Habana can provide customers with excellent performance while maintaining very competitive pricing.
For more information about Habana Gaudi and Gaudi2, please visit: https://habana.ai/training.
See Related Content
Technical Articles
- Getting Started with Habana® Gaudi® for Deep Learning Training
- Hyperparameter Optimization with SigOpt for MLPerf Training
Get the Software
Intel® AI Analytics Toolkit
Accelerate end-to-end machine learning and data science pipelines with optimized deep learning frameworks and high-performing Python* libraries.
Get It Now
See All Tools