This article was originally published on Medium*.

Figure 1. Photo by Brett Jordan on Unsplash
Oct. 15, 2023—Large Language Models (LLMs) have taken the world by storm this past year with chatbots, code generation, debugging, retrieval augmented generation (RAG), instruction-following, and many more applications. In this article, I demonstrate LLM inference on the latest Intel® Data Center GPU Max Series 1100.
The two LLM models that I worked with are:
- Camel-5b: Derived from the base architecture of Palmyra-Base, Camel-5b is a 5-billion parameter LLM model, trained on 70 K instruction-response records. The Camel-5b model differentiates itself from other LLMs in being able to take in complex instructions and generate contextually accurate responses.
- Open LLaMA 3B v2: An open source, 3-billion parameter reproduction of the Meta* LLaMA model, trained on a variety of data. The biggest clear advantage to this model is that it builds upon the success of the Meta LLaMA 2 and is permissively licensed for much broader consumption.
Just a note on these particular models—they were not fine-tuned for chat, so your mileage may vary in terms of the responses from these models.
Intel GPU Hardware
The particular GPU that I used for my inference test is the Intel Data Center GPU Max Series 1100, which has 48 GB of memory, 56 Xe-cores, and 300 W of thermal design power. On the command line, I can first verify that I indeed do have the GPUs that I expect by running:
clinfo -l
And I get an output showing that I have access to four Intel GPUs on the current node:
Platform #0: Intel(R) OpenCL Graphics
+-- Device #0: Intel(R) Data Center GPU Max 1100
+-- Device #1: Intel(R) Data Center GPU Max 1100
+-- Device #2: Intel(R) Data Center GPU Max 1100
`-- Device #3: Intel(R) Data Center GPU Max 1100
Similar to the nvidia-smi function, you can run the xpu-smi in the command line with a few options selected to get the statistics you want on GPU use.
xpu-smi dump -d 0 -m 0,5,18
The result is a printout every 1 s of important GPU use for the device 0:
getpwuid error: Success
Timestamp, DeviceId, GPU Utilization (%), GPU Memory Utilization (%), GPU Memory Used (MiB)
13:34:51.000, 0, 0.02, 0.05, 28.75
13:34:52.000, 0, 0.00, 0.05, 28.75
13:34:53.000, 0, 0.00, 0.05, 28.75
13:34:54.000, 0, 0.00, 0.05, 28.75
Run the LLM Examples
My colleague, Rahul Nair, wrote an LLM inference Jupyter* Notebook that is hosted directly on the Intel® Developer Cloud. It gives you the option of using either model that I outlined earlier. Here are the steps you can take to get started:
- Go to Intel Developer Cloud.
- Register as a standard user.
- Once you are logged in, go to the Training and Workshops section.
- Select GenAI Launch Jupyter Notebook. You can find the LLM inference notebook and run it there.
Figure 2 shows the user interface within the LLM notebook. You have the option of selecting a model, interacting with or without context, and then selecting the parameters of Temperature, Top P, Top K, Num Beams, and Rep Penalty. Their definitions are:
- Temperature: The temperature for controlling randomness in Boltzmann distribution. Higher values increase randomness, lower values make the generation more deterministic.
- Top P: The cumulative distribution function (CDF) threshold for nucleus sampling. It helps in controlling the trade-off between randomness and diversity.
- Top K: The number of highest probability vocabulary tokens to keep for top-k-filtering.
- Num Beams: The number of beams for a beam search. It controls the breadth of the search.
- Repetition Penalty: The penalty applied for repeating tokens.
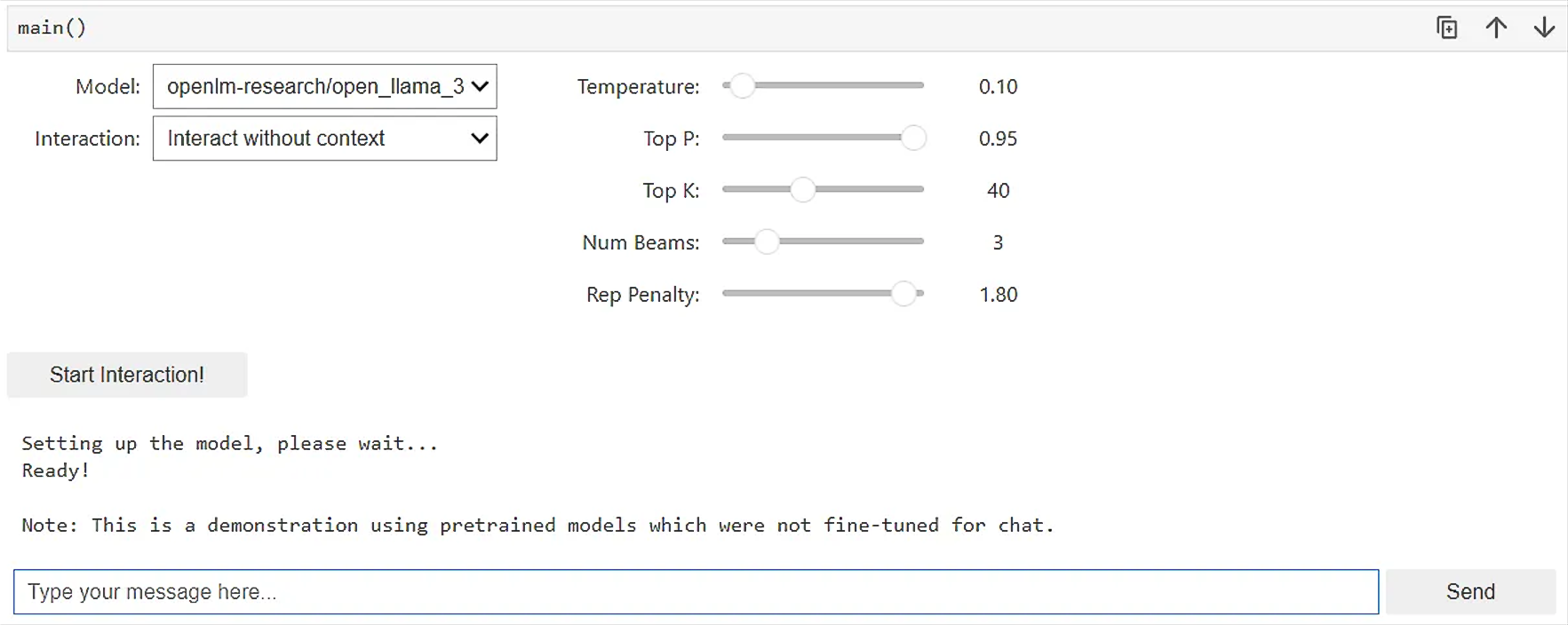
Figure 2. A mini user interface within the Jupyter Notebook environment allows for a text prompt and response in line.
To speed up inference on the Intel GPU, the Intel® Extension for PyTorch* was used. Two of the key functions are:
ipex.optimize_transformers(self.model, dtype=self.torch_dtype)
and
ipex.optimize(self.model, dtype=self.torch_dtype)
where self.model is the loaded LLM model, and self.torch_dtype is the data type, which to speed up performance on the Intel GPU should be torch.bfloat16. You can learn more about the Intel Extension for PyTorch in the GitHub* repository.
I was able to generate responses with these models within seconds after the model was loaded into memory. As I mentioned, because these models are not fine-tuned for chat, your mileage may vary in terms of the response of the model.
You can reach me on:
- DevHub Discord* server (user name bconsolvo)
- LinkedIn*
- X (formerly known as Twitter*)
Disclaimer for Using Large Language Models
Be aware that while LLMs like Camel-5b and OpenLLaMA 3b v2 are powerful tools for text generation, they may sometimes produce results that are unexpected, biased, or inconsistent with the given prompt. It’s advisable to carefully review the generated text and consider the context and application in which you are using these models.
Use of these models must also adhere to the licensing agreements and be in accordance with ethical guidelines and best practices for AI. If you have any concerns or encounter issues with the models, refer to the respective model cards and documentation provided in the previous links.