06/11/2024
Introduction
Intel has a Compiler Engineering team dedicated to the GNU* Compiler Collection (GCC). We consistently engage with the GCC community, working to incorporate enhancements that boost performance and drive innovation, including those tailored for x86 architectures, into GCC 14. This ongoing initiative is one of many manifestations of our longstanding and significant commitment to the open-source community, a collaboration that strengthens and supports developers across the entire software landscape.
The GCC x86 backend was enabled to support the next generations of
- Intel® Core™ Ultra mobile processors (code-named Lunar Lake),
- 6th Generation Intel® Xeon® Scalable processors with Efficient-cores (E-cores) and Performance-cores (P-cores) (code-named Sierra Forest and Granite Rapids)
- and Intel® Core™ Processors and Intel® Xeon® Processors following these.
This includes support for Intel® Advanced Performance Extensions (Intel® APX) in those future platforms.
Note: Please refer to Intel® Architecture Instruction Set Extensions Programming Reference for instruction set details.
Several auto-vectorization enhancements have been developed for new vector neural network instructions (AVX-VNNI-INT16) in the GCC 14 compiler. In addition, we contributed many patches, improving quality and performance in the compiler backend. Last but not least, the spin-lock was fine-tuned for hybrid Intel Core Processors with both P-cores and E-cores, resulting in a significant performance gain as measured by SPECspeed® 2017.
Generation-to-Generation Performance Improvement
O2 is the default optimization level for major Linux OS distributions, e.g., RedHat* Enterprise Linux (RHEL). Many users also prefer O2 to build their programs. Besides, RHEL 9 uses x86-64-v2 as the default architecture setting. For GCC 14, more effort was put into the -O2 performance with x86-64-v2 and improved by 1% for SPECrate® 2017. Figure 1 shows more details about the improvement.
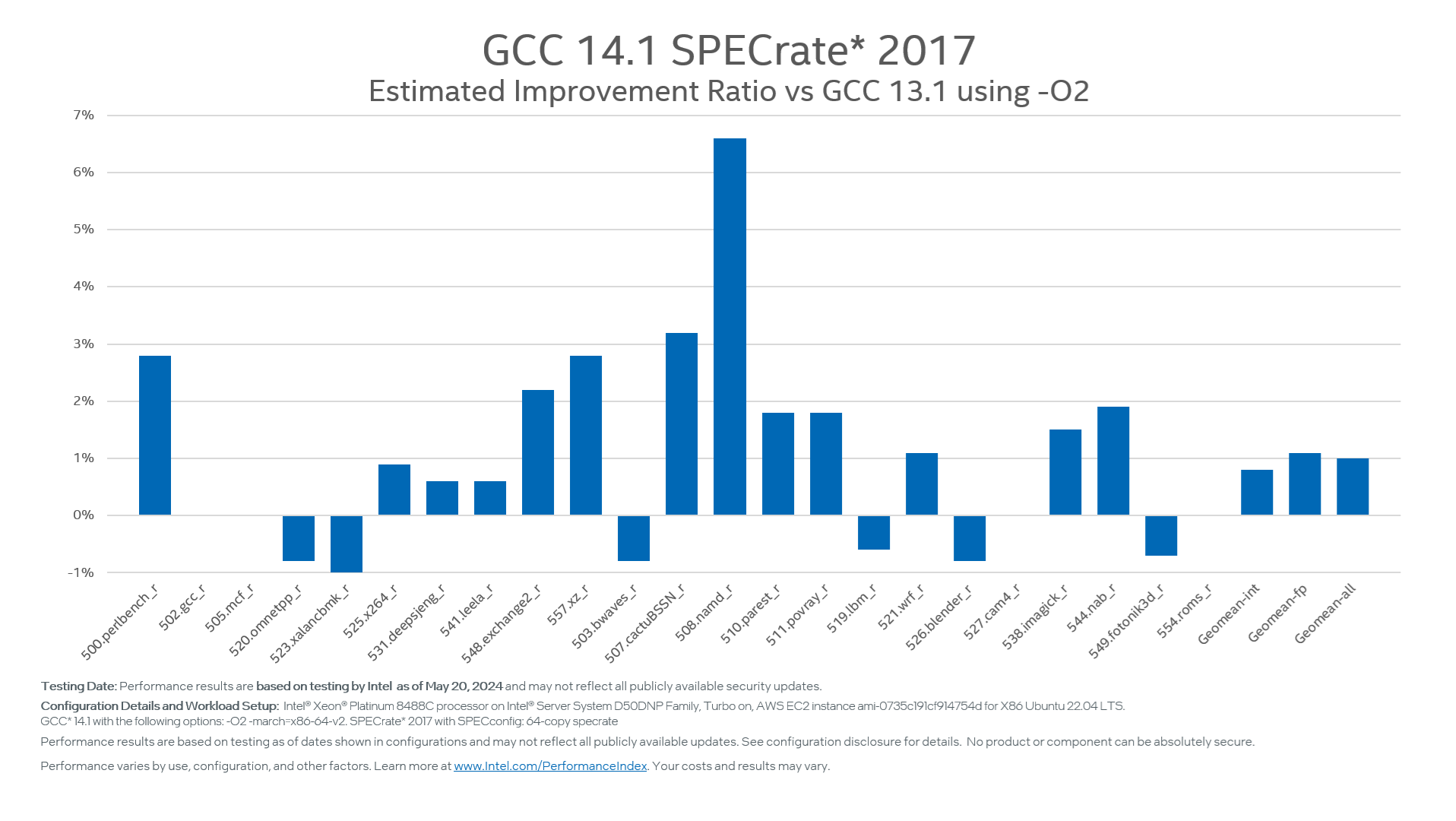
Figure 1: GCC 14.1 -O2 SPECrate 2017 (64-core) estimated improvement ratio vs GCC 13.1 on 4th Gen Intel Xeon Scalable Processor (formerly code-named Sapphire Rapids).
|
Configuration:
|
GCC 14 Ofast performance has also improved by 1.9% for SPECrate 2017. Figure 2 shows more details of the improvement across benchmark reference algorithms.
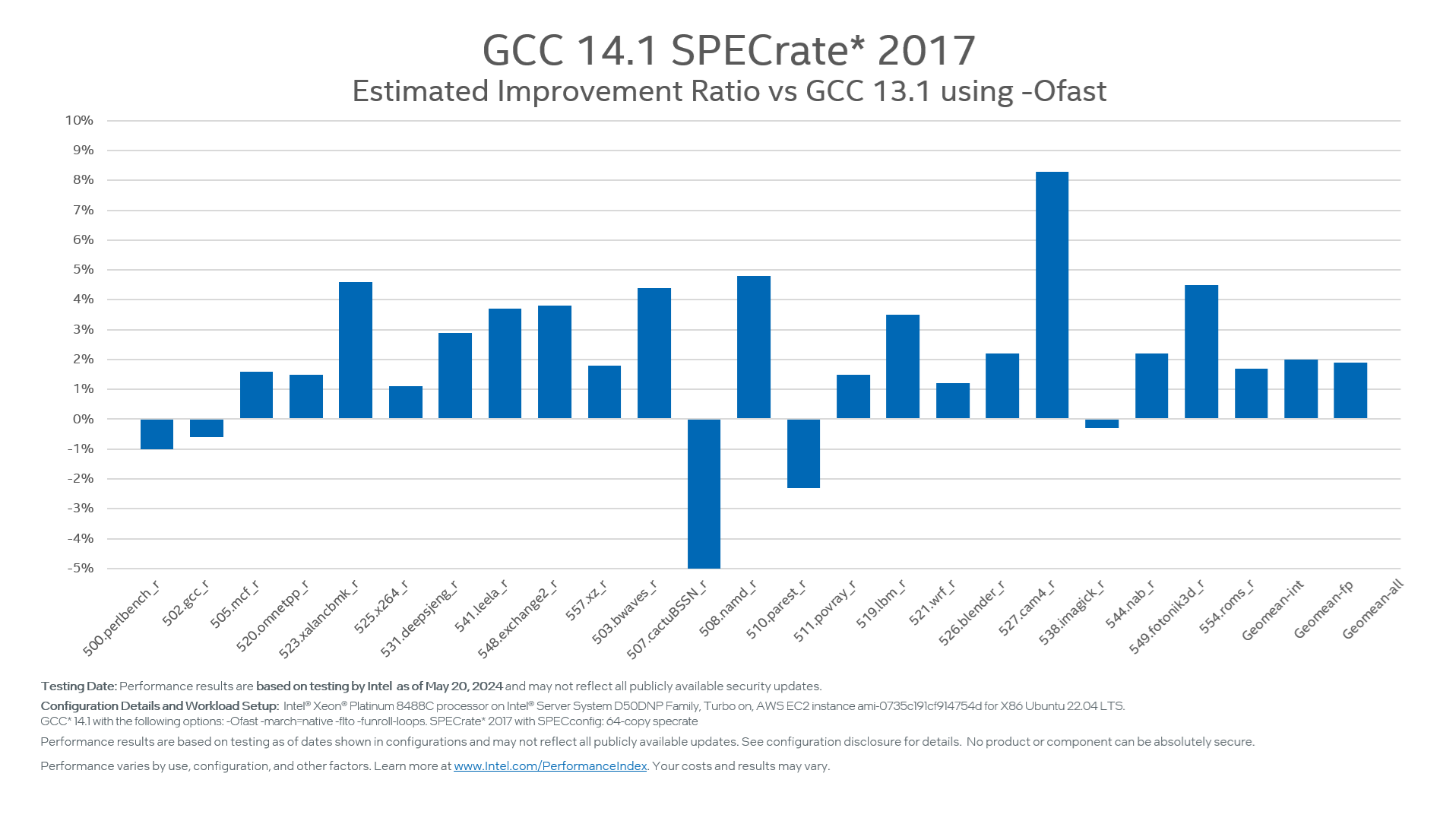
Figure 2: GCC 14.1 -Ofast SPECrate 2017 (64-core) estimated improvement ratio vs GCC 13.1 on 4th Gen Intel Xeon Scalable Processor (formerly code-named Sapphire Rapids).
|
Configuration:
|
Support for Next Generation Intel Xeon Scalable Processors
In GCC 14, we introduced and supported two major new features, Intel® Advanced Vector Extensions 10 (Intel® AVX10) and Intel® APX.
Intel® Advanced Vector Extensions 10
Intel AVX10 introduces a modern vector Instruction Set Architecture (ISA) supported across future Intel processors. This new ISA includes all the richness of the Intel® Advanced Vector Extensions 512 (Intel® AVX-512) with additional features and capabilities enabling it to seamlessly run across performance cores and efficient cores, delivering performance and consistency across all platforms.
It also introduces a new enumeration approach based on version and supported vector lengths, reducing the burden on the developer to check multiple feature bits for the platform.
Intel AVX10 extends and enhances the capabilities of Intel AVX-512 to benefit all Intel products and will be the vector ISA of choice moving into the future.
Note: More details can be found in Intel® Advanced Vector Extensions 10 (Intel® AVX10) Architecture Specification.

Figure 3: Intel AVX-512 Feature Flags Across Intel Xeon Scalable Processor Generations vs. Intel AVX10

Figure 4: Intel® ISA Families and Features
Intel AVX10.1 is first introduced in Granite Rapids and can be configured with two max vector sizes, 256bit and 512bit, for all existing AVX512 instructions. GCC 14 introduces new compiler options to support these different vector sizes.
-mavx10.1
The 256-bit vector size is supported via the -mavx10.1-256 or -mavx10.1 compiler options to generate EVEX instructions with 256-bit constraint (up to YMM registers), while the -mavx10.1-512 compiler option provides additional 512-bit vector size support (up to ZMM registers).
The 256-bit vector size binaries can be run across different platforms that support either 256-bit or 512-bit vector sizes. However, 512-bit vector size binaries can only be run on platforms that support 512-bit vector size, not those that support up to 256-bit vector size.
-mno-evex512
Considering the migration of existing binaries to the new platforms with AVX10, a new compiler option -mno-evex512 was added to GCC 14. The -mno-evex512 compiler option disables the generation of 512-bit vector instructions based on the specified architecture or ISA set. For example, with -mno-evex512 -march=skylake-avx512, the compiler can produce a binary with AVX512 instructions on a 1st Generation Intel Xeon Scalable Processor with 256-bit vector size, which could be deployed on all existing Intel Xeon Scalable Processors and future processors which support AVX10-256 or AVX10-512.
Intel® Advanced Performance Extensions
Intel Advanced Performance Extensions (Intel® APX) is the next major step in the evolution of Intel® architecture, which expands the entire x86 instruction set with access to more general purpose registers and adds various new features that improve general-purpose performance. The extensions are designed to provide efficient performance gains across various workloads – without significantly increasing the core's silicon area or power consumption.
The main features of Intel® APX include:
- 16 additional general-purpose registers (GPRs) R16–R31, also referred to as Extended GPRs (EGPRs);
- Three-operand instruction formats with a new data destination (NDD) register for many integer instructions;
- Conditional ISA improvements: New conditional load, store, and compare instructions, combined with an option for the compiler to suppress the status flags writes of common instructions;
- Optimized register state save/restore operations;
- A new 64-bit absolute direct jump instruction.
Note: More detailed information can be found in the APX Architecture Specification: Introducing Intel® Advanced Performance Extensions (APX)
GCC 14 now supports some major features in APX, including EGPR (Extra 16 general purpose registers), PUSH2/POP2 (register stat save/restore), NDD (New data destination), and PPX (Push-pop acceleration).
-mapxf
The features are available via the -mapxf compiler option. In addition, the optimization of new linker relocations for APX instructions has been supported in binutils 2.42.
Procedure linkage table (PLT) rewrite has been enabled in glibc 2.39 to change the indirect branch in PLT to APX JMPABS at run-time to improve branch prediction. The environment variable GLIBC_TUNABLES=glibc.cpu.plt_rewrite=2 enables it.
Since not all instructions have the EGPR extension, the EGPR feature was disabled in inline assembly by default to prevent generating illegal instructions with inappropriate EGPR registers. To invoke EGPR usage in inline asm, programmers can explicitly use the new compiler option -mapx-inline-asm-use-gpr32 and need to ensure the instructions in inline asm support EGPR.
Hardware-assisted AddressSanitizer now works with LAM_U57
Intel® Linear Address Masking Extension (LAM) allows software to locate metadata in data pointers and dereference them without having to mask the metadata bits. It supports:
-LAM_U48: Activate LAM for user data pointers and use of bits 62:48 as masked metadata.
-LAM_U57: Activate LAM for user data pointers and use of bits 62:57 as masked metadata.
Hardware-assisted AddressSanitizer helps debug address problems similarly to AddressSanitizer but is based on partial hardware assistance and provides probabilistic protection to use less RAM at run time.
To use this sanitizer, the command line options are:
-fsanitize=hwaddress to instrument userspace code.
-fsanitize=kernel-hwaddress to instrument kernel code.
The -march GCC compiler instruction set options for upcoming Intel processors
- GCC now supports the Intel CPU code-named Clearwater Forest using -march=clearwaterforest. Based on its predecessor, the 6th Gen Intel Xeon processor with E-cores, the switch further enables the AVX-VNNI-INT16, PREFETCHI, SHA512, SM3, SM4, and USER_MSR ISA extensions.
- GCC now supports the Intel CPU code-named Arrow Lake using -march=arrowlake. Based on its predecessor, the 12th Gen Intel Core processor, the switch further enables the AVX-IFMA, AVX-NE-CONVERT, AVX-VNNI-INT8, and CMPccXADD ISA extensions.
- GCC now supports the Intel CPU code-named Arrow Lake S using -march=arrowlake-s. In addition to the Intel CPU code-named Arrow Lake, the switch further enables the AVX-VNNI-INT16, SHA512, SM3, and SM4 ISA extensions.
- GCC now supports the Intel CPU code-named Lunar Lake using -march=lunarlake. It has the same ISA as the Intel CPU code-named Arrow Lake S.
- GCC now supports the Intel CPU code-named Panther Lake using -march=pantherlake. Based on its predecessor, Intel CPU code-named Arrow Lake S, the switch further enables the PREFETCHI ISA extensions.
Note: For more details on the new intrinsics, see the Intel® Intrinsics Guide.
Auto-Vectorization Enhancement
Besides the intrinsics for the new instructions, auto-vectorization has been enhanced to generate vector neural network instructions (AVX-VNNI-INT16). Also several other auto-vectorization improvements have been developed in GCC 14.
Auto-vectorization for AVX-VNNI-INT16 vpdpbssd
Auto-vectorization was enhanced to perform idiom recognition (such as the dot-production idiom) that triggers instruction generation for AVX-VNNI-INT16. Figure 5 shows that the compiler generates the vpdpwuud instructions plus a sum reduction.
int udot_prod_hi (unsigned short * restrict a,
unsigned short *restrict b, int c, int n) {
for (int i = 0; i < 16; i++) {
c += ((int) a[i] * (int) b[i]);
}
return c;
}
udot_prod_hi:
vmovdqu (%rdi), %ymm0
vpxor %xmm1, %xmm1, %xmm1
movl %edx, %eax
vpdpwuud (%rsi), %ymm0, %ymm1
vextracti128 $0x1, %ymm1, %xmm0
vpaddd %xmm1, %xmm0, %xmm0
vpsrldq $8, %xmm0, %xmm1
vpaddd %xmm1, %xmm0, %xmm0
vpsrldq $4, %xmm0, %xmm1
vpaddd %xmm1, %xmm0, %xmm0
vmovd %xmm0, %edx
addl %edx, %eax
vzeroupper
ret
Figure 5: Intel® AVX for VNNI idiom recognition in GCC (-O2 -mavxvnniint16) auto-vectorization
Auto-vectorization for more dot products via vpmaddwd
When VNNI dot production instructions are unavailable in the target architecture (e.g., AVX2), auto-vectorization can also perform idiom recognition (such as the dot-production idiom) to generate the most efficient set of equivalent instructions. Figure 6 shows that the compiler generates the vpmovzxbw and vpmaddwd instructions plus a sum reduction.
int udot_prod_qi (unsigned char * restrict a,
unsigned char *restrict b, int c, int n) {
for (int i = 0; i < 16; i++) {
c += ((int) a[i] * (int) b[i]);
}
return c;
}
udot_prod_qi:
vmovdqu (%rdi), %xmm1
vmovdqu (%rsi), %xmm2
movl %edx, %eax
vpmovzxbw %xmm2, %xmm3
vpsrldq $8, %xmm2, %xmm2
vpmovzxbw %xmm1, %xmm0
vpsrldq $8, %xmm1, %xmm1
vpmovzxbw %xmm2, %xmm2
vpmaddwd %xmm3, %xmm0, %xmm0
vpmovzxbw %xmm1, %xmm1
vpmaddwd %xmm2, %xmm1, %xmm1
vpaddd %xmm1, %xmm0, %xmm0
vpsrldq $8, %xmm0, %xmm1
vpaddd %xmm1, %xmm0, %xmm0
vpsrldq $4, %xmm0, %xmm1
vpaddd %xmm1, %xmm0, %xmm0
vmovd %xmm0, %edx
addl %edx, %eax
ret
Figure 6: GCC (-O2 -march=x86-64-v3) auto-vectorization via vpmovzxbw + vpmaddwd
Auto-vectorization for conversion from char to double
There is no direct conversion instruction for vector types from char to double, but it can be supported with an intermediate type. Figure 7 shows that the conversion is supported via vpmovsxbd and vcvtdq2pd.
void foo (char* a, double* __restrict b)
{
for (int i = 0; i != 4; i++)
b[i] = a[i];
}
foo:
vpmovsxbd (%rdi), %xmm0
vcvtdq2pd %xmm0, %ymm0
vmovupd %ymm0, (%rsi)
vzeroupper
ret
Figure 7: auto-vectorization for conversion from char to double via vpmovsxbd and vcvtdq2pd (-O3 -mavx2)
Code Generation Optimization for the x86 Back End
Generate more FMA instructions
In the current GCC framework, the pass for generating fused multiply-add (FMA) instructions is pass_optimize_widening_mul, which comes after pass_reassoc. Because pass_reassoc doesn’t consider the existence of FMA, pass_optimize_widening_mul loses some FMA generation opportunities.
The heuristics of pass_reassoc was improved in GCC14 to generate as many FMA instructions as possible while considering instruction parallelism. Figure 6 shows one case of the optimization; GCC 13.2 generates vmulss and vfmadd132ss and vaddss, while GCC 14 generates vfmadd132ss and vfmadd132ss.
float
foo (float a, float b, float c, float d, float *e)
{
return *e + a * b + c * d ;
}
GCC 13.2:
foo:
vmulss %xmm3, %xmm2, %xmm2
vfmadd132ss %xmm1, %xmm2, %xmm0
vaddss (%rdi), %xmm0, %xmm0
ret
GCC 14:
foo:
vfmadd213ss (%rdi), %xmm3, %xmm2
vfmadd132ss %xmm1, %xmm2, %xmm0
ret
Figure 8: FMA optimization of GCC 14 vs. GCC13.2 with -march=86-64-v3 -Ofast
Enable AVOID_256FMA_CHAINS in -mtune=generic
Generating FMA instructions in tight loops might negatively impact performance. A common scenario is FMA accumulation introducing data dependence across the loop. When the loop is tight, FMA might have a longer dependence chain than a pair of FMUL and FADD instructions.
This became obvious when the FADD latency was cut in half in the new E-cores and P-cores. A code optimization example is as below.
Before Optimization:
110: mov (%rsi,%rax,1),%ecx
vmovsd (%r11,%rax,2),%xmm0
add $0x4,%rax
cmp %rdi,%rax
vfmadd231sd (%rdx,%rcx,8),%xmm0,%xmm1 // 4 cycles on 4th Gen Intel Xeon Scalable Processor
jne 110
After Optimization:
110: mov (%rsi,%rax,1),%ecx
movsd (%rdx,%rcx,8),%xmm0
mulsd (%r11,%rax,2),%xmm0 //4 cycles
add $0x4,%rax
addsd %xmm0,%xmm1 // 2 cycles
cmp %rdi,%rax
jne 110
In GCC 13 this optimization fine-tuning option AVOID_256FMA_CHAINS was enabled as part of m_ALDERLAKE and m_SAPPHIRERAPIDS. It brought 4.5% improvement on E-core, and 3.13% on P-core measured by SPECrate 2017 Floating Point Suite, as mentioned in our GCC 13 blog.
In GCC 14, the optimization is also applied as part of -mtune=generic to improve the performance of more generic architectures, including -march=x86-64-v3, -march=x86-64-v4 etc. The experiment showed that this approach improves SPECrate 2017 Floating Point Suite by 2.4% on 4th Gen Intel Xeon Scalable processor (formerly code-named Sapphire Rapids) and 3.6% on 12th Gen Intel Core processors P-core (formerly code-named Alder Lake), while it had less impact to previous processors. The patch was also backported to GCC 13.4.
New options (-mgather and -mscatter) to control auto-generation for gather and scatter instructions.
The gather and scatter instructions vary greatly in performance on different processors. In addition to the microarchitecture tuning, two new compiler options were introduced to control the generation of gather and scatter instructions in auto-vectorization.
Note: Negative options (-mno-gather/-mno-scatter) can’t disable the generation of gather/scatter instructions from corresponding intrinsics.
Combine vlddqu and inserti128 to vbroadcasti128
vlddqu and vinserti128 use shuffle port in addition to load port. In terms of latency, vbroadcasti128 is comparable to vlddqu and vinserti128. Figure 9 shows that vlddqu and vinserti128 are optimized using vbroadcasti128.
#include <immintrin.h>
__m256i foo(void *data) {
__m128i X1 = _mm_lddqu_si128((__m128i*)data);
__m256i V1 = _mm256_broadcastsi128_si256 (X1);
return V1;
}
foo:
vbroadcasti128 (%rdi), %ymm0
ret
Figure 9: vbroadcasti128 is generated instead of vlddqu + vinserti128 under -march=x86-64-v3 -O2
Microarchitecture Tuning
As measured by SPECspeed 2017, The spin-lock was fine-tuned for hybrid platforms and significantly improved performance by 8.5% on 12th Gen Intel Core Processor. Figure 8 shows more details about the improvement.
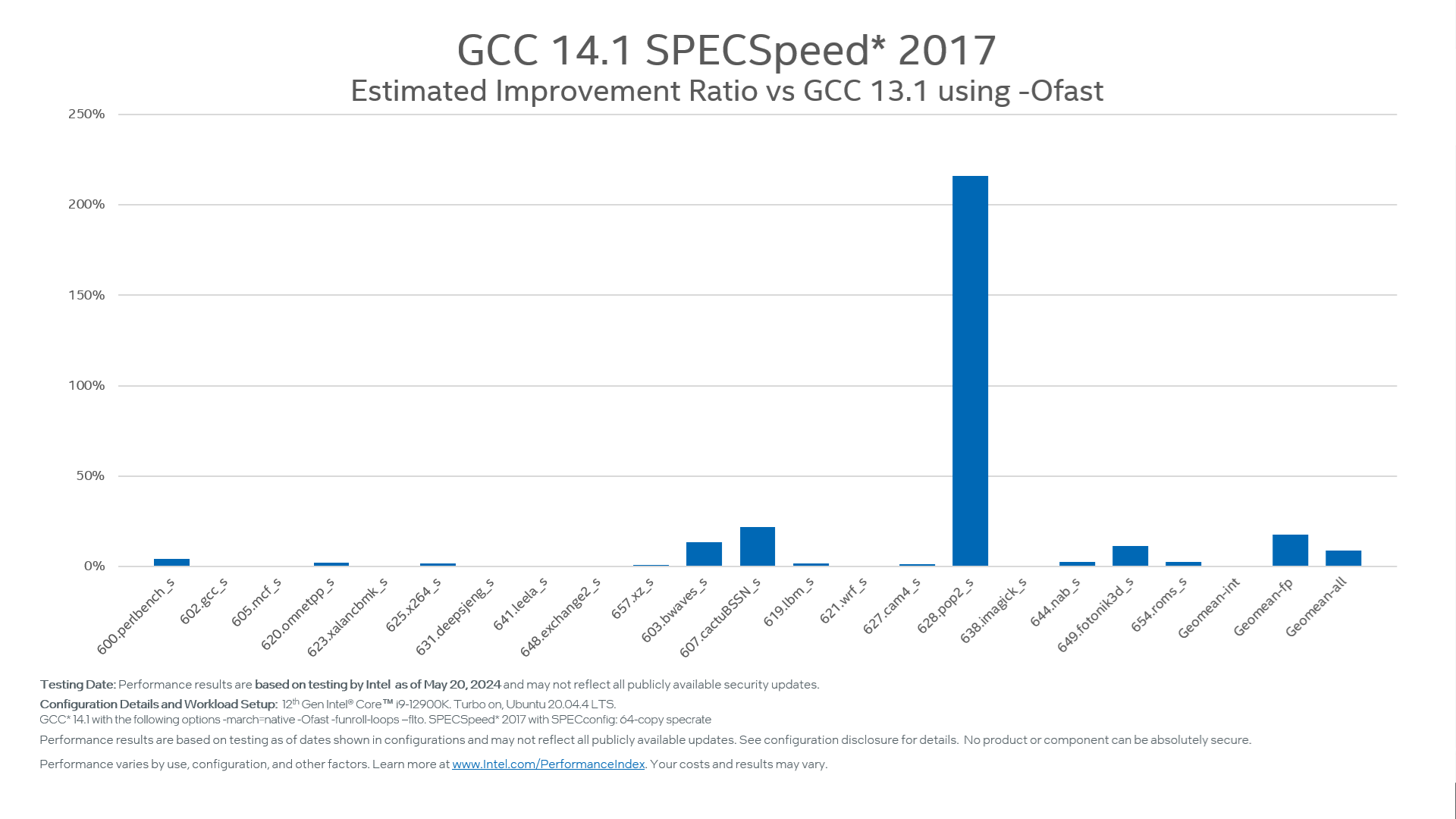
Figure 10: SPECspeed 2017® is improved by 8.5% Geomean on 12th Gen Intel Core Processor with -march=native -Ofast -funroll-loops -flto
|
Configuration:
For additional details, please consult the performance estimate footnote. |
Future Work
In GCC 15 and beyond, we continue implementing the remaining features in Intel APX and Intel AVX10 and other new features in future platforms.
We also continue to drive performance by improving auto-vectorization in different optimization levels. We are very excited to see the performance gain this will achieve. We look forward to coordinating with the community in our ongoing efforts to improve GCC performance further on modern workloads and use cases.
Please don’t hesitate to share your feedback and provide input through GCC mailing lists.