Fine-tuning Llama 2 models on Intel® Data Center GPUs using BigDL LLM
By Du, Wesley, Wang, Yang Y and Unnikrishnan Nair, Rahul
In the rapidly evolving field of Generative AI (GenAI), fine-tuning large language models (LLMs) presents unique challenges because of their high computational and memory demands. Techniques such as LoRA and QLoRA present powerful options for tuning state-of-the-art LLMs faster and at reduced costs. We have integrated QLoRA into the BigDL LLM library, specifically designed for Intel GPUs.
In this article, we cover two topics about fine-tuning Llama 2 models using QLoRA on Intel® Data Center GPUs:
- Performance improvement results data
- Fine-tuning Instructions
Fine-tuning LLMs Using BigDL LLM
We performed fine-tuning on the Llama 2 7B and 70B models using QLoRA on the Stanford Alpaca dataset and ran 3 epochs using multiple Intel® Data Center GPU Max 1550 and 1100 systems (including systems on the Intel® Tiber™ AI Cloud).
The graph below presents a comparison of the fine-tuning durations for the Llama 2 7B and 70B model, using configurations of the Intel® Data Center GPU Max 1550 and 1100 systems with 1, 4, and 8 GPUs.
Performance Data Results
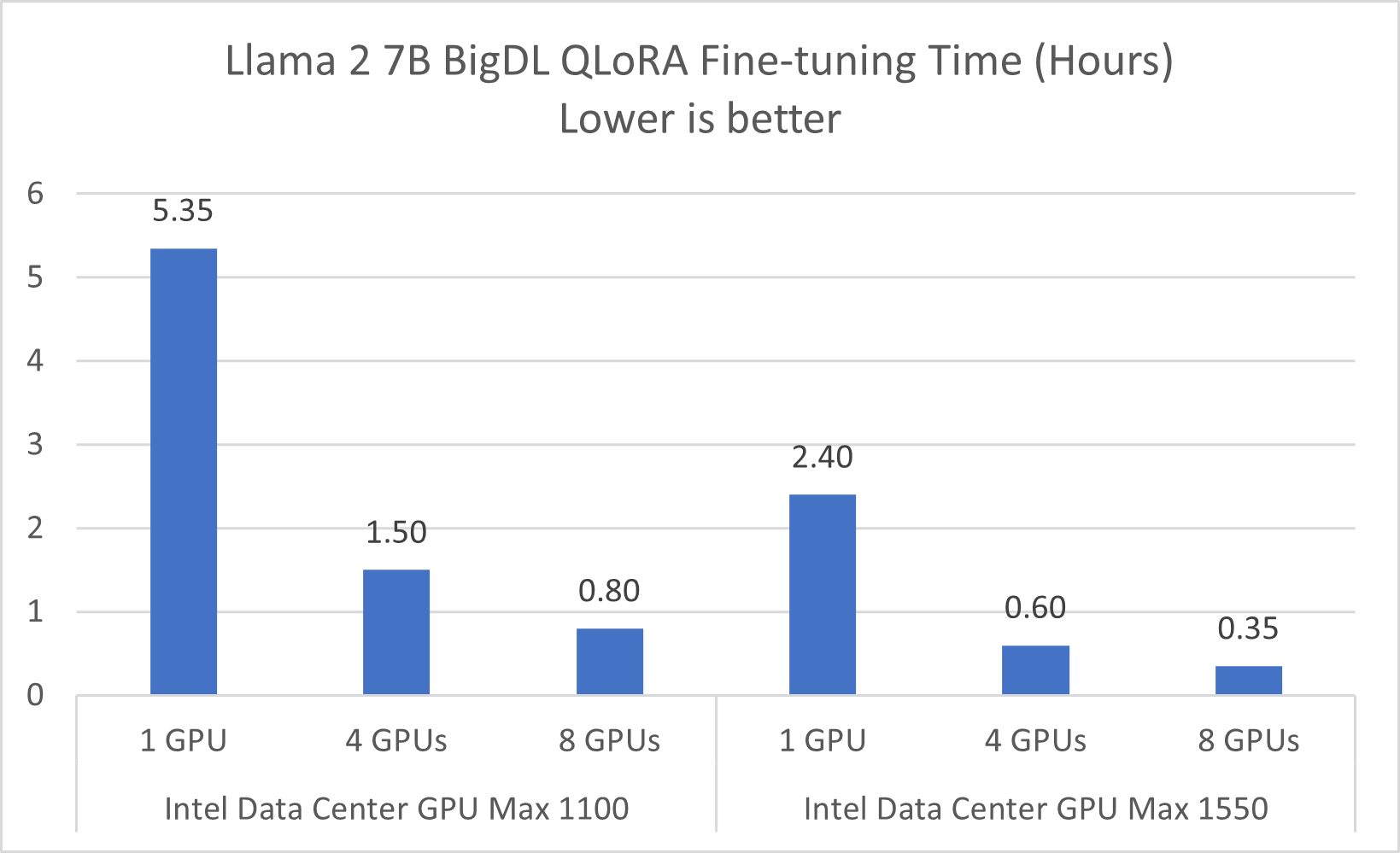
Figure 1. Llama 2 7B Fine-Tuning Performance on Intel® Data Center GPU
Refer to Configurations and Disclaimers for configurations
In a single-server configuration with a single GPU card, the time taken to fine-tune Llama 2 7B ranges from 5.35 hours with one Intel® Data Center GPU Max 1100 to 2.4 hours with one Intel® Data Center GPU Max 1550. When the configuration is scaled up to 8 GPUs, the fine-tuning time for Llama 2 7B significantly decreases to about 0.8 hours (48 minutes) with the Intel® Data Center GPU Max 1100, and to about 0.35 hours (21 minutes) with the Intel® Data Center GPU Max 1550.
The BigDL LLM library extends support for fine-tuning LLMs to a variety of Intel GPUs, including the Intel® Data Center GPU Flex 170 and Intel® Arc™ series graphics. Specifically, using the Intel® Data Center GPU Flex 170 hardware as an example, you can complete the fine-tuning of the Llama 2 7B model in approximately 2 hours on a single server equipped with 8 Intel® Data Center GPU Flex 170 graphics cards.
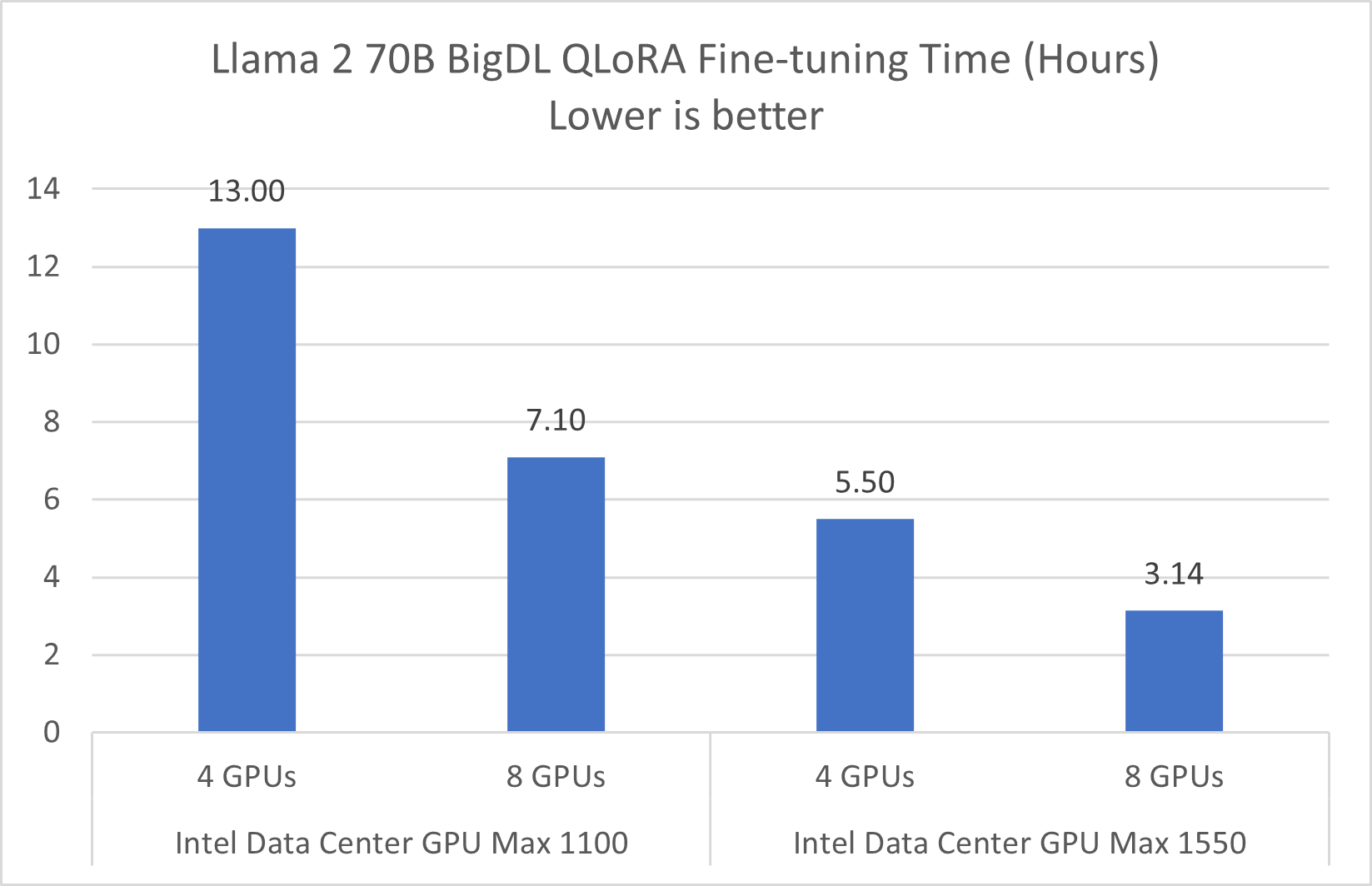
Figure 2. Llama 2 70B Fine-Tuning Performance on Intel® Data Center GPU
Refer to Configurations and Disclaimers for configurations
Fine-tuning larger LLMs, such as the Llama 2 70B, demands increased computational power, VRAM, and time. In our assessments with configurations of 4 and 8 Intel® Data Center GPU Max Series cards on a single server, we observed notable efficiency gains. Specifically, a single server equipped with 8 Intel® Data Center GPU Max Series GPUs significantly expedites the process, completing the fine-tuning of the Llama 2 70B model in roughly 200 minutes, or 3.14 hours. This setup emerged as the most efficient among those we tested.
Dataset used for Model Training
We have utilized the yahma/alpaca-cleaned dataset from Hugging Face, which contains 51.8k rows of English instructional text. For a comprehensive understanding and application of this dataset, visit the Hugging Face Dataset Page.
Instructions for fine-tuning LLMs
In these instructions, we'll walk you through the steps to fine-tune Llama 2 models using BigDL LLM on Intel® Data Center GPUs.
-
Get Intel Data Center GPU resource on Intel Developer Cloud
Intel® Data Center GPU instances are available on the Intel® Tiber™ AI Cloud. You can create a free account and explore various compute platforms offered by Intel. Follow the instructions on the IDC website to get started. -
Prepare BigDL LLM environment for LLM fine-tuning
To prepare the BigDL LLM environment for fine-tuning LLMs on Intel GPUs, you typically start with a Linux system equipped with an Intel GPU driver and the oneAPI base toolkit. We recommend you use Conda for environment management.The setup process is greatly simplified when you use the Intel Developer Cloud, where the Conda environment comes pre-configured with the necessary components, including the pytorch-gpu environment. This streamlined setup on the Intel Developer Cloud eliminates the need for manual environment sourcing, and lets you focus on your LLM fine-tuning tasks more efficiently.
Get started by selecting the pytorch-gpu kernel and install the bigdl-llm[xpu] package, as shown here:
conda create -n llm python=3.9
conda activate llm
pip install --pre --upgrade bigdl-llm[xpu] -f https://developer.intel.com/ipex-whl-stable-xpu
Configure oneAPI environment variables:
source /opt/intel/oneapi/setvars.sh
To achieve optimal performance on Intel Data Center GPU, you should also install gperftools and set important configuration environment variables:
conda install -y gperftools -c conda-forge
export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libtcmalloc.so
export USE_XETLA=OFF
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
export ENABLE_SDP_FUSION=1
- Fine-tuning Llama 2 7B model on a single GPU
This pseudo-code outline offers a structured approach for efficient fine-tuning with the Intel® Data Center GPU Max 1550 GPU. See the notes after the code example for further explanation. We'll call below code fine-tuning.py, it will be used for fine-tuning both Llama 2 7B and 70B models.
import torch
import transformers
from datasets import load_dataset
import accelerate
from transformers import LlamaTokenizer
from peft import LoraConfig
import intel_extension_for_pytorch as ipex
from bigdl.llm.transformers import AutoModelForCausalLM
from bigdl.llm.transformers.qlora import get_peft_model, prepare_model_for_kbit_training
def train(\...):
#Step 1: Load the base model from a directory or the HF Hub to 4-bit NormalFloat format
model = AutoModelForCausalLM.from_pretrained(
'meta-llama/lama-2-7b-hf',
load_in_low_bit="nf4", # According to the QLoRA paper, using "nf4" could yield better model quality than "int4"
optimize_model=False,
torch_dtype=torch.bfloat16,
modules_to_not_convert=["lm_head"],
)
model = model.to('xpu')
tokenizer = LlamaTokenizer.from_pretrained(base_model)
# Step 2: Prepare a BigDL-LLM compatible Peft model
model = prepare_model_for_kbit_training(
model,
use_gradient_checkpointing=gradient_checkpointing
)
config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
target_modules=lora_target_modules,
lora_dropout=lora_dropout,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
# load dataset and split data to train_data and val_data
data = load_dataset(data_path)
train, val_data = ...
# Step 3: Data processing and passing to data_collator
trainer = transformers.Trainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
args=transformers.TrainingArguments(
# keypart3: define plenty of training args as you need
bf16=True,
per_device_train_batch_size=micro_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
num_train_epochs=num_epochs,
learning_rate=learning_rate,
gradient_checkpointing=gradient_checkpointing,
...
),
data_collator=...
)
model.config.use_cache = False
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
model.save_pretrained(output_dir)
Notes:
-
In Step1, setting low_in_low_bit='nf4' within the AutoModelForCausalLM module of the bigdl.llm.transformers converts all Linear layers (excluding the 'lm_head') to 4-bit NormalFloat. Then, by executing model.to("xpu"), the converted Llama 2 7B model is transferred from the CPU to the Intel GPU.
-
In Step 2, utilize the get_peft_model and prepare_model_for_kbit_training functions from bigdl.llm.transformers.qlora. These functions are instrumental in preparing the converted Llama 2 7B model into a format compatible with BigDL-LLM, specifically as a Peft model.
-
In Step 3, the parameters in TrainingArguments are set for improved fine-tuning performance. Note that setting BF16=True yields more balanced fine-tuning performance and model accuracy when using a mixed datatype of BF16 and FP32.
Refer to the alpaca_qlora_fine-tuning.py script on GitHub to view the complete fine-tuning code example.
- Fine-tuning Llama 2 70B and extend to distributed fine-tuning on multiple GPUs
To extend the fine-tuning process from Llama 2 7B to Llama 2 70B, change 'meta-llama/Llama-2-7b-hf' to 'meta-llama/Llama-2-70b-hf', and set gradient_checkpointing=True, otherwise there is a high probability that the GPU VRAM will not be sufficient to complete the training for 70B model.
We use miprun to enable distributed fine-tuning on systems with multiple GPUs. Here are the example steps for how this is done:
- Set local rank, world size and related variables:
def get_int_from_env(env_keys, default):
"""Returns the first positive env value found in the `env_keys` list or the default."""
for e in env_keys:
val = int(os.environ.get(e, -1))
if val >= 0:
return val
return default
local_rank = get_int_from_env(["LOCAL_RANK","MPI_LOCALRANKID"], "0")
world_size = get_int_from_env(["WORLD_SIZE","PMI_SIZE"], "1")
port = get_int_from_env(["MASTER_PORT"], 29500)
os.environ["LOCAL_RANK"] = str(local_rank)
os.environ["WORLD_SIZE"] = str(world_size)
os.environ["RANK"] = str(local_rank)
os.environ["MASTER_PORT"] = str(port)
- Set environment variables and use mpirun to launch the fine-tuning.py script shown above:
export MASTER_ADDR=127.0.0.1
export OMP_NUM_THREADS=6 # adjust this to 1/16 of total physical cores
export FI_PROVIDER=tcp
export CCL_ATL_TRANSPORT=ofi
mpirun -n 16 \
python -u ./fine-tuning.py \
--base_model “meta-llama/Llama-2-70b-hf” \
For more details, refer to the BigDL LLM online example in GitHub.
Get Started
To get started on fine-tuning large language models using BigDL LLM and the QLoRA technique, we have developed a comprehensive step-by-step Jupyter notebook. Begin by registering for a free standard account on the Intel® Tiber™ AI Cloud. Once registered, go to the console home page, click on the Training and Workshops icon on the left edge, scroll down to the "Gen AI Essentials" section, and access the LLM Fine-tuning with QLoRA notebook. This notebook will guide you through the fine-tuning process in a step-by-step manner and help you apply these techniques to various LLMs.
Summary
Our exploration into fine-tuning large language models using BigDL LLM on Intel® Data Center GPUs sheds light on efficient strategies to overcome the large computational and memory challenges inherent in Generative AI models. Through performance data analysis and step-by-step instructions, we've demonstrated the effectiveness of QLoRA in significantly reducing fine-tuning times for state-of-the-art LLMs such as Llama 2 7B and Llama 2 70B. We hope our findings offer valuable insights and serve as a practical resource for researchers and practitioners in the field and underscores our ongoing commitment to advancing Generative AI, sharing knowledge, and promoting collaborative innovation in this dynamic and rapidly evolving domain.
Acknowledgement
We would like to thank Yang3 Wang, Ruonan Wang, Yabai Hu and Jason Dai for BigDL LLM QLoRA development and content contribution, and special thanks to Golembiewski Brian P, Kermanshahche Kristina and Kinder David for their great support.
Configurations and Disclaimers
The benchmark uses 3 EPOCHS to measure the duration of the training time. Batch size 128, micro batch size 8 or 4. Data type NF4. The measurements used BigDL-LLM 2.4.0b20231109, PyTorch 2.0.1, Intel® Extension for PyTorch* 2.0.110+xpu, Transformers 4.34.0 and Intel oneAPI Base Toolkit 2023.2. Ubuntu 22.04.3 LTS with kernel 5.15.0. Intel GPU Driver 2328.38. Tests performed by Intel in November 2023. Intel® Data Center GPU Max 1100 x1, x4 and x8 results were measured on a system with 2S Intel® Xeon® 8480+ and 512 GB DDR5-4800. Intel® Data Center GPU Max 1550 x1 and x4 results were measured on a system with 2S Intel® Xeon® 8480+ and 1024 GB DDR5-4800. Intel® Data Center GPU Max 1550 x8 results were measured on a system with 2S Intel® Xeon® 8468V and 2048 GB DDR5-4800.
Performance varies by use, configuration and other factors. Learn more on the Performance Index site. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation. © Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.