Co-author: Kai Wan of Dangdang.com*.
Dangdang.com* is a large online shopping platform in China, popular for selling various books and publications. Personalized recommendation plays an important role on Dangdang’s website and mobile channels for recommending users with the books that they most likely have interest in (as shown in Figure 1 below). This blog discusses the best practice at Dangdang.com to efficiently perform large-scale offline book recommendation with BigDL on Intel® Xeon clusters.

Figure 1: Personalized Book Recommendation at mobile Dangdang.com
Part1: Dangdang’s recommendation use case
To enhance online book search experience, Dangdang has implemented a Wide & Deep recommender model with TensorFlow to rank the items for each user based on the user and item features as well as the user’s purchase and browse history. To make the recommendation on the website most efficient, Dangdang performs the offline batch inference for the Wide & Deep model every night and refreshes the website recommendations for users daily.
Dangdang’s previous trial ran the model inference on Nvidia GPU. Due to the limited number of GPU resources available in the production environment, Dangdang could only afford to run the model inference using a single V100 on a subset of the data (size around 200GB), which took about 5 hours to complete1. On the other hand, Dangdang does have a 200-node Hadoop/YARN cluster on Intel® Xeon, which is available as a shared resource pool for running different data processing and analytics workloads. Thus, to improve the overall workload efficiency, Dangdang has switched to running offline inference on the Xeon cluster with the adoption of BigDL with minimum efforts.
Part2: Dangdang’s offline recommendation pipeline with BigDL
BigDL can seamlessly scale single-node AI applications across Xeon clusters for distributed model training or inference on in-memory datasets (such as Spark DataFrames, TensorFlow Dataset, PyTorch DataLoader, Ray Dataset, etc.). The unified architecture of Dangdang’s end-to-end, distributed offline recommender inference pipeline on BigDL is shown in Figure 2 below.
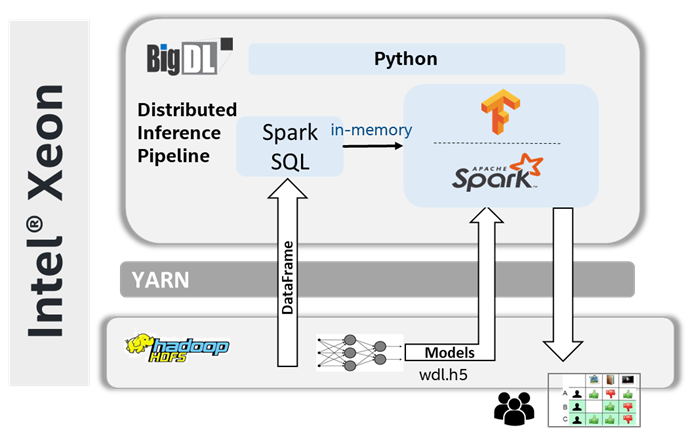
Figure 2: Offline Inference Pipeline with BigDL on Xeon at Dangdang.com
The entire pipeline includes Spark data processing and TensorFlow model inference. Dangdang first uses Spark to load their large-scale data from HDFS, process user and item features, then generate each user’s most recent activities to form a history sequence. The processed data are directly in-memory fed into the TensorFlow model through BigDL on the same Xeon cluster and the prediction results are written back to HDFS with Spark. The code segment of Dangdang’s inference workload on BigDL is shown below. After adopting BigDL, Dangdang can directly leverage the “freely” available Xeon cluster to run the AI pipeline, and easily scale-out model inference across multiple Xeon servers to operate on their full dataset.
# Load and process with Spark DataFrames
df = spark.read.csv("hdfs://data/path", sep=',', header=True)
df = df.select(…).withColumn(…)
# Distributed inference with BigDL TensorFlow Estimator
from bigdl.orca.learn.tf2 import Estimator
estimator = Estimator.from_keras(backend="spark", workers_per_node=4)
estimator.load("hdfs://path/to/wdl.h5")
prediction_df = estimator.predict(df, batch_size=32, feature_cols=[…])
prediction_df.write.mode("overwrite").parquet("hdfs://output/path")
Part3: Performance Comparison
Per Dangdang’s test results in the production, the solution with BigDL takes 22 minutes to complete the model inference on the same 200GB data with 300 Xeon cores, more than 13.6x speed up (as shown in Figure 3) against the original solution on a single V1002. Moreover, such a unified solution runs the workflow on a single Xeon cluster, avoids the data transfer overhead between separate systems and turns out to be easier to manage. As a result, Dangdang has successfully migrated their offline recommender model inference pipeline from V100 to Xeon to achieve better end-to-end efficiency.
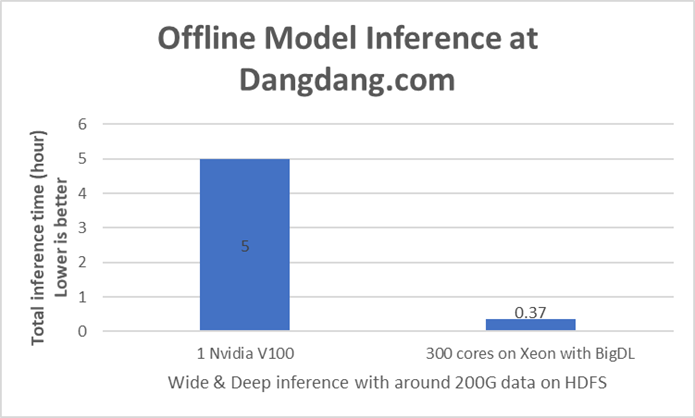
Figure 3: Offline Inference Performance Comparison Results
Part4: Conclusion
BigDL has been proven to be a good framework at Dangdang.com for scaling AI applications on distributed Xeon cluster and has brought significant performance benefits to the overall workloads. Dangdang has productized BigDL for their offline Wide & Deep inference workflow, showing personalized book recommendations to a large number of users on its homepage. Don’t hesitate to checkout BigDL’s GitHub repo and documentation page for more details and instructions to build your own unified data analytics and AI pipelines!
1 This data is from Dangdang’s internal testing.
2 Performance data is based on Dangdang’s internal testing with the config:
CPU: The solution with BigDL runs on Dangdang’s Hadoop/YARN cluster Intel® Xeon E5-2699 v4, uses 300 Spark(Spark 2.3) executors in total, 1 vCore per executor with 1g memory and 1.5g memory overhead. Each Spark executor runs one Wide & Deep model inference with batch size 32.
GPU: 1X NVIDIA Tesla V100, Framework Tensorflow 2.1
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure. Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
Intel does not control or audit third-party data. Please review the content, consult other sources, and independently confirm if the data provided is accurate.
Copyright © Intel Corporation. Intel, the Intel logo, and other Intel trademarks are trademarks of Intel Corporation or its subsidiaries in the U.S. and/or other countries. Other names and brands may be the property of other owners.