In this two-part series, Mambwe Mumba and I discuss how developers can use containers together with Wind River Simics® virtual platforms. Part 1 deals with the technology of containers and how to use them with Simics, and Part 2 will discuss the applications and workflows enabled by containerizing Simics.

In domains like cloud applications and DevOps workflows, containers provide a way to manage and deploy applications with less overhead than a VM and less hassle than native host application installation. Containers provide multiple benefits, including: isolating applications; simple packaging and delivery; and easy application provisioning and management. While much container usage happens on servers and in the cloud, these benefits are also compelling for local usage on a client system.
 [Mambwe Mumba] is a software engineer for Intel’s System Simulation Center (SSC) where he played a critical early role in pushing and supporting adoption of Wind River Simics® virtual platforms. Simics is used extensively across Intel and by its partners for firmware and BIOS development, test and continuous integration, architectural studies, fault injection, and pretty much anything for which actual silicon doesn't yet exist or is too expensive or inconvenient to use at scale. Mambwe recently embarked on a sojourn through artificial neural networks and deep learning, including exploring extensions into simulation and containerizations. He holds a PhD in theoretical physics with a focus on Quantum Optics from the University of Arkansas. Having a fascination for cultures and languages of the world, he dabbles in learning different spoken languages in his spare time.
[Mambwe Mumba] is a software engineer for Intel’s System Simulation Center (SSC) where he played a critical early role in pushing and supporting adoption of Wind River Simics® virtual platforms. Simics is used extensively across Intel and by its partners for firmware and BIOS development, test and continuous integration, architectural studies, fault injection, and pretty much anything for which actual silicon doesn't yet exist or is too expensive or inconvenient to use at scale. Mambwe recently embarked on a sojourn through artificial neural networks and deep learning, including exploring extensions into simulation and containerizations. He holds a PhD in theoretical physics with a focus on Quantum Optics from the University of Arkansas. Having a fascination for cultures and languages of the world, he dabbles in learning different spoken languages in his spare time.
What is a Container?
JE: Can you give us a fundamental description of what a container is?
MM: A container is a way to package an application along with all the other files and resources that it needs to run, except for the operating system kernel. Instead of running an installation process and making sure all needed libraries and other resources are in place, you can take a containerized application and just drop it onto a host and run it, and it should just work, with no installation or administration needed.
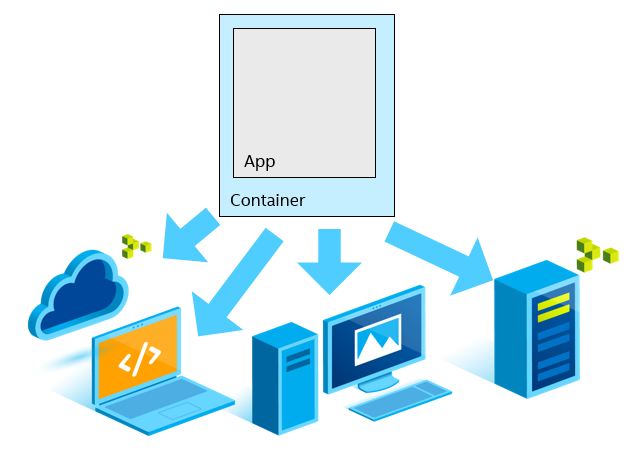
An app inside a container is easy to run on a variety of hosts.
The container includes the shared libraries and other files that an application needs. The host OS kernel is used directly from the containerized application but using a namespace to virtually separate it from other applications running on the host. What this effectively means is that you now have an application packaged into an environment that is not only isolated from other applications running on the same host, but also is portable across hosts. All resources and shared libraries used by the application will always be the versions that were defined in creating this container, so you have effectively created an environment for the application with fixed dependencies that won’t be changing from one host installation to the next.
Each host can run any number of containers, right alongside standard native apps.
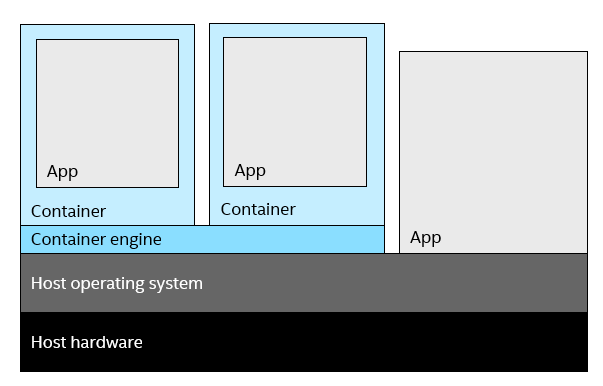
The container engine lets containers run on a host, alongside standard applications.
The most common container system in use today is Docker*, which is used both on its own and as a supporting technology for container orchestration systems like Kubernetes* for containers running in a cloud environment.
JE: Do you have some concrete example to help illustrate this?
MM: Working on a deep learning project required the use of a few tools that are well known in the data science community. I noticed that people usually have these complex installations that can be time consuming to install and replicate. If you’ve ever tried to follow and replicate a deep learning setup, which is usually shared as a Git repository, it becomes evident very quickly that there is a very large amount of work needed to make sure the right combination of versions of all these pieces are setup or installed. What seemed to be a well laid-out process for getting, say, a specific convolutional neural net architecture setup to run object detection on a host running a specific operating system (OS) flavor and version, is not so simple. There are a lot of supporting libraries whose versions may have to match the deep learning framework being run, such as BigDL or TensorFlow*, that will be running training either on a host’s processor cores or a GPU. If you’re lucky, and you magically have all the right versions that match the Git repo, it may work the first time. But it is far more likely you’ll be spending a good amount of time trying to figure out how to resolve all the dependency and version issues that inevitably arise. Any complex environment setup will face this barrier.
I noticed that a growing trend to address this in the data science and AI communities was the use of containers. It is becoming a more common practice to use containerized applications with everything a data scientist would need, such as containerized Jupyter* Notebook applications. Containers provided a solid, host-agnostic way to package an application’s code, libraries, and dependencies into a single unit that can be distributed and deployed on any machine by anyone without IT assistance.
The Docker hub Jupyter image page shown below has 60 layers, where each represents a step in the process of setting up the environment required to run Jupyter notebooks. It is easy to see why having to setup this environment from scratch would not be very appealing, even to experienced users. That makes it compelling to have the option of just running the setup as a containerized application. Every user can take advantage of the setup work already done by the initial containerization process. At its simplest, it would only involve downloading the Docker image and running it to create an instantly useable Jupyter application, running on the host.
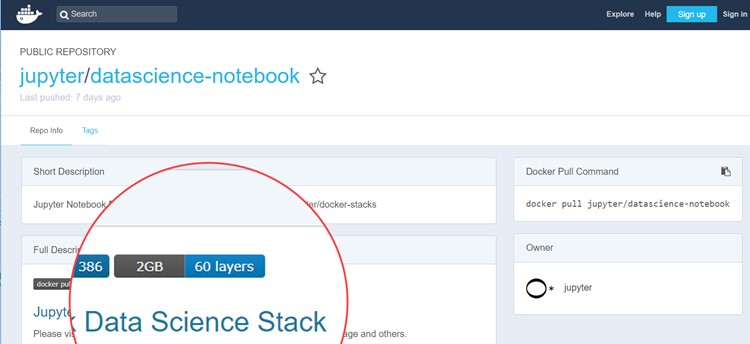
Screenshot of a Jupyter Notebook docker image, featuring 60 layers of software.
(from https://hub.docker.com/r/jupyter/datascience-notebook/)
This was the light-bulb moment, when I thought, why not introduce this as an alternative way to work with Simics? It has many dependencies and host requirements that are not always easy to replicate in terms of setup, so why not have a containerized workflow for Simics?
Like this:
Simics in a container.
JE: How do containers compare to classic virtual machines (VMs)? They also provide isolation and easy deployment onto any host machine, don’t they?
MM: The most important difference is the footprint. Each VM claims a good portion of hardware resources on the host, whether the application running in it needs all the resources or not. A full operating system is installed in each VM to run the target application(s).
By comparison, containerized applications run directly on the host operating system kernel. They use their own namespace in the kernel, so the application effectively sees its own private operating system instance. Without this namespacing, the applications would risk conflicting and interfering with other applications. The idea behind containers is not new—it goes back 40 years—but the idea has exploded in popularity over the last decade. That’s because it has been packaged in a way that doesn’t require developers to have an intimate knowledge of the Linux kernel.
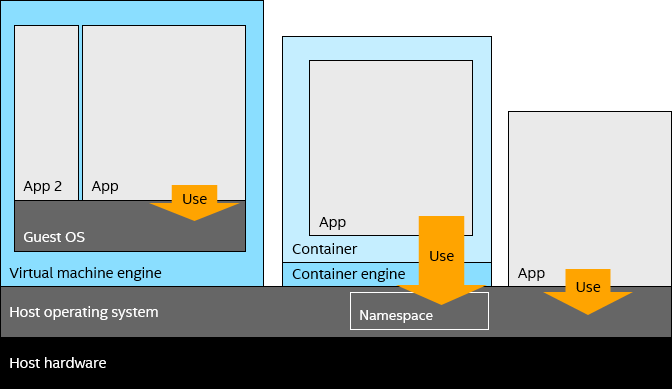
Comparing how VMs and containers provide an operating system to applications.
Containerized applications are very similar to native applications in terms of overhead, needing only the resources provided by the host kernel. The only additional complexity is the container engine installed and running on the host OS.
Inside the Container
JE: If we look a bit closer at what is going on, what is really inside that container? And what is being provided by the host operating system?
MM: The container that is instantiated to run the application is aware of a base operating system image, and various layers are built on top of that OS image. The application is one or more of these layers. You can instantiate any number of containers from a single image, running on the same or different machines.
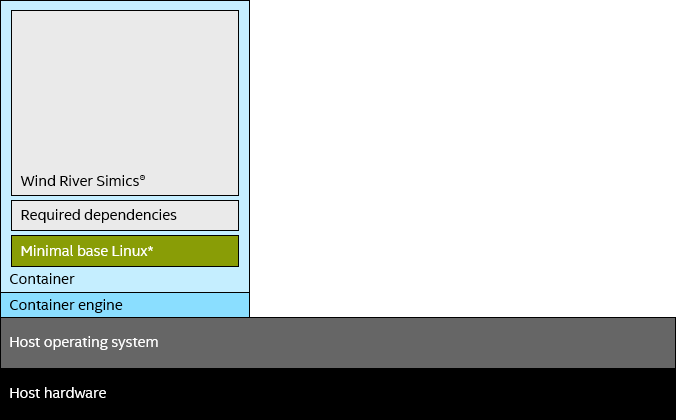
The difference here is that instead of a full OS such as Ubuntu* Linux*, that would have to be installed on a VM before installing the target application, the container image has a layer with only a minimal Ubuntu Linux file system. For the application, it looks just like an Ubuntu installation, but the container can still run on another OS, say Fedora* Linux*, without the application noticing any differences. The kernel is the same, but the details of the Linux distribution are provided by the containers. The key is to provide the right files and executables in the right locations to make the applications perceive the environment of a certain Linux distribution, and then the application does not have to worry about how to adapt to different distributions; it can just select one that works and use that everywhere.
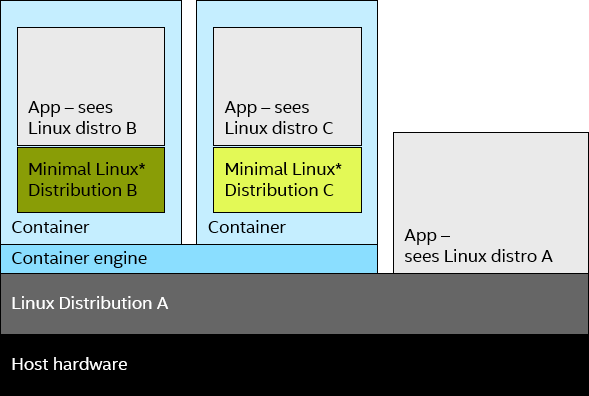
Containers provide an alternative Linux distribution to applications, while still using the same kernel.
JE: In the block diagram above, what does “minimal” mean?
MM: It means that the base Ubuntu OS inside the container will not have all the bells and whistles that come with a full Ubuntu distribution. Ubuntu comes with a lot of preinstalled libraries and applications, whether you need to use them or not. The container’s base OS image only contains the bare minimum, and one can install any other dependencies as additional layers required for the target application to run, and nothing else. If you don’t need a web browser or a fancy editor to run the app, why install them?
This difference in architecture means that containers are smaller to ship and faster to start up than virtual machines, and multiple containers can share host resources more efficiently than a set of VMs can.
Simics in a Container
JE: How do you run Simics in a container?
MM: It comes down to constructing a container image containing Simics and its dependencies on top of a base OS image. The net effect is that Simics is contained together with all libraries and other required executables, along with the essential elements of a known-good Linux distribution:
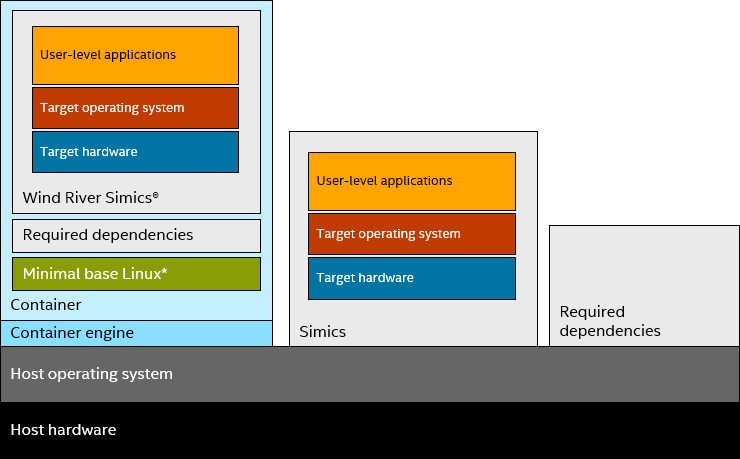
Containers provide an alternative Linux distribution to applications, while still using the same kernel.
Usually, to run Simics on a particular Linux host, the user has to install some required dependencies separately from Simics. These include xterm for all versions of Simics until Simics 5, and sufficiently modern versions of glibc. But inside the container, these are provided without any changes needed on the host. That is how containers provide an easier way to install software that depends on the installation of other software.
JE: So how do you go about building an image?
MM: This varies between container systems. Container images for Docker are built using a Dockerfile. It describes how to build an image by constructing layers one atop the other. Layers make it easy to separate out different aspects of the image that are independent from each other and can be independently updated.
The process typically starts with an initial base layer, for instance a minimal Ubuntu 16.04 LTS layer. The lines in the Dockerfile walk through the process of adding layers on top of this base, installing any dependencies or shared files that your target application—Simics in our case—would need, and finally a layer which installs the target application from its binary.
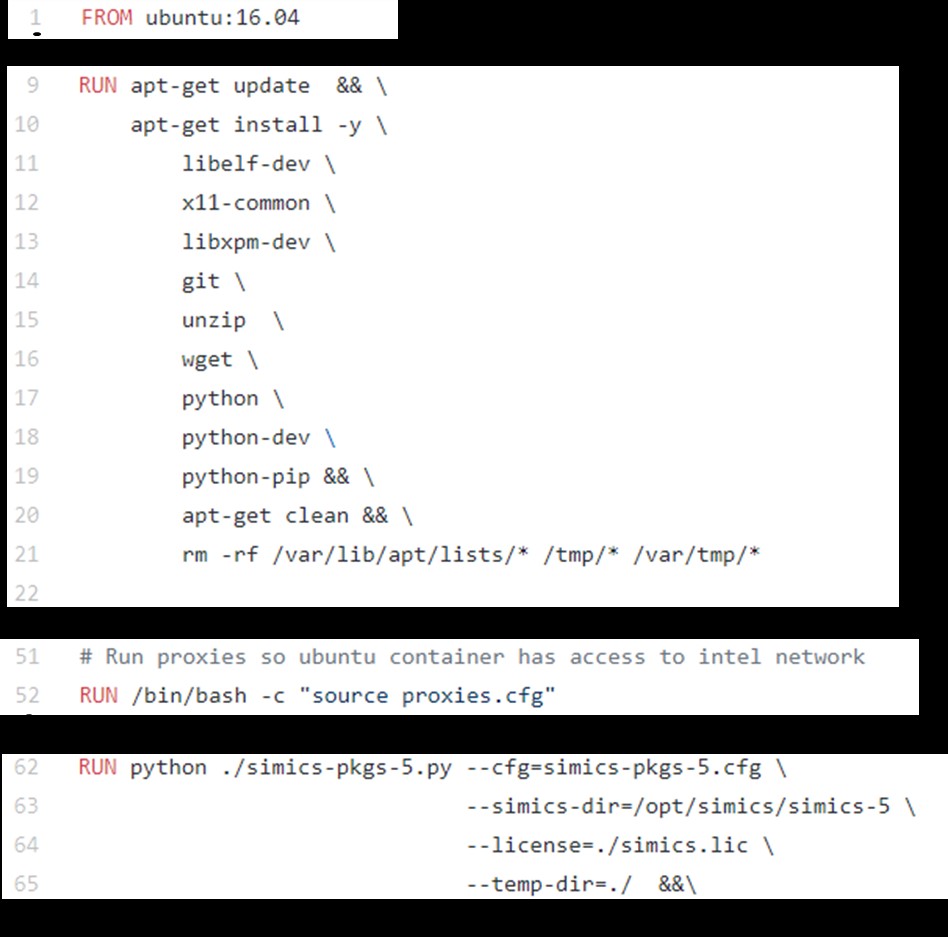
Parts of a Dockerfile building a Simics Docker image.
To install Simics into the container image, the Dockerfile can point to the location of an existing Simics installation on the host. You could also use an automated script to install Simics as part of building the container image. This kind of automation makes it possible to create a new Docker image when Simics is updated—typically, the base Simics product is updated weekly, and target system models are sometimes updated more frequently than that.
The Simics installation step would be followed by more commands that run setup scripts within the image to provide the running container with correctly configured access to the corporate network, etc.
JE: So – basically, you do the installation of a set of packages once, and then you can give everyone the completed installation instead of them having to do it themselves?
MM: Yes. But there’s an additional means of doing this. You can distribute the final Docker image that results from compiling this Dockerfile, or you can distribute the Dockerfile and let users compile it for themselves. Distributing the Dockerfile has a couple of benefits. The user can make changes to it, such as installing another layer on top of it. It also provides a way to distribute a well-documented and tested process for installing Simics. It’s an added means for engineers to understand the setup process, a self-documenting process, if you will.
JE: What about the project used for running Simics in practice? Would I want to have my own individual project for each separate run?
MM: If you need a Simics project, you can create one inside the Docker image that provides a complete setup for running Simics. Just include a line within the Dockerfile that creates a directory and runs the usual Simics setup within it to provide the Simics project that users are familiar with. The output from any run can be retrieved from this Simics project space quite easily.
This is great for applications like demos and training where you want to provide the user with a ready-to-use setup, without any setup needed and no risk for mistakes. But users would need to remember that when they spin up a container, and it does whatever they want it to do, the container does not save any state. You can think of it as providing a service, and any useful output from running it should be saved on the host, not inside the container, itself. The container will eventually be stopped or even removed. Instantiating this container again will not provide any state saved from any previous run. You will effectively be starting a pristine Simics setup each time.
JE: Interesting – we really do use containers to just hold applications, which is unlike the typical virtual machine setup, in my experience.
MM: That is the usage model in the cloud environment, where each container encapsulates a specific service that it contributes to a larger application. If a container fails, it can be replaced by another which doesn’t have to remember any previous state.
Alternatively, you can think of this like being given a Simics executable to use. You can run this executable in any folder. The folder would contain any collateral you need, as well as hold any output you might want to get from running this “Simics App.” The notion of having a Simics project directory still exists, as it is setup within the container, but as a user of this Simics app, you don’t need to setup another Simics project directory. Any directory works that has the collateral you need, and you just need to point this Simics app to the directory you’d like to have it read from or write to if needed, with the container making some directories on the host visible inside the container.
Finally, the user could provide an existing Simics project on the host, and run the containerized Simics using this project. This is good if the user already has an existing Simics setup and wants to reuse scripts and disk images with the containerized Simics, as well as any output or checkpoints saved to the Simics project. Containers are highly flexible in this respect, and they can be made to behave like a program installed locally on the host. That is a lot easier to do than using virtual machines.
JE: So, I have written my Dockerfile, what do I do next?
MM: Compiling the Dockerfile yields a Docker image. A Docker image is shareable either by direct transfer between hosts, or by sharing via upload to an accessible public or permissions-based private Docker registry. Users then download the image, or deploy it using a container management and orchestration system. They can use Simics without any need to go through an installation process.
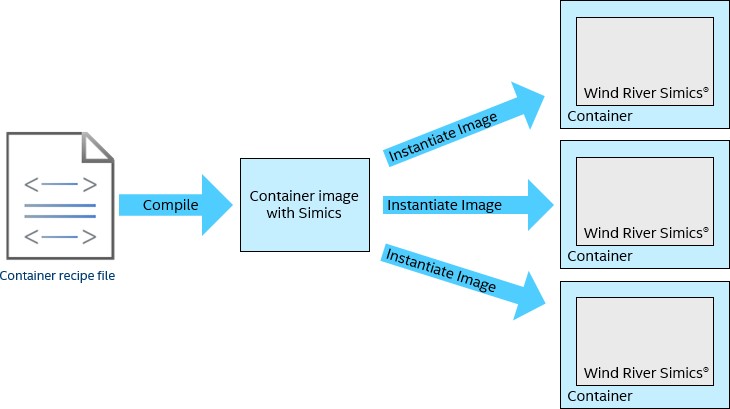
Containerizing Simics virtual platforms: The image can be instantiated many times.
JE: What if I do not want to use it as-is? Say I want to add another target model or a specific target OS image?
MM: That is easy to do. The Docker image you just built can be used as the base layer for another Dockerfile. All the user needs to do is to specify the additional layers that they need to add on top of what is already in the image. Alternatively, a user can just edit the Dockerfile and replace one package with another, or install whatever number of packages they need for that particular Simics container image, and just compile it. Your new image will include the packages you specified in the Dockerfile.
How Well Does It Run?
JE: We know that running Simics in a VM has some overhead associated with it, in particular when you want to use Simics VMP technology to run Intel® architecture (IA) target code directly on the host by using Intel® Virtualization Technology (Intel® VT) for IA. What about overhead with containers?
MM: In the experiments we have made so far, the overhead is very low. First, VMP works. You just install the VMP driver on a Linux host, and give the containerized Simics access to the VMP driver file system nodes. That provides performance very similar to what you see with Simics running natively on the same machine—unlike running on Simics on top of an OS on top of a hypervisor, where we usually see performance loss on the order of 50% or more.
The memory overhead is also small, and the containerized Simics can dynamically grow its memory usage. Containers do allow you to put limits on how much memory a container can use, but if you do not do that, Simics will behave as it would when running natively on the host. That is also a very important difference compared to running Simics under a VM, since a VM has to be provided with a certain fixed memory size when starting up. A VM also has the overhead of the guest OS running inside it, which is essentially missing from the container.
There is a small amount of overhead that you should expect from containers—a few percentage points lower performance than running Simics natively on the host. However, it is not particularly significant, and natural variations are much greater, such as the background load on the machine running Simics and variations in clock frequency due to load. So, containers do not have a substantial impact on Simics performance, at least not as far as we have been able to measure.
Next Time
In the next blog post, we will raise the level of abstraction and look at how you can use Simics in a container to enable new and more efficient workflows.
Related Content
Simplify Hardware Simulation with Containers: How and where a containerized approach for Simics® simulation improves the general workflow, and the impact of organization-wide adoption of a Simics containerized workflow.
The Early Days of Simics – An Interview with Bengt Werner: A look back at what happened before Simics went commercial in June 1998.
Intentional and Accidental Fault Injection in Virtual Platforms: Once nominal functionality is established, questions come up about how to test abnormal and faulty system behaviors.
1000 Machines in a Simulation: Feats from the past and how they reflect into current technology and best practices.
Running “Large” Software on Wind River* Simics® Virtual Platforms, Then and Now: A look at the past, present, and future of Wind River® Simics® virtual platforms.