Tune MPI Collective Communication with the mpitune_fast Utility
Dr. Amarpal S Kapoor, technical consulting engineer, and
Marat Shamshetdinov, software development engineer, Intel Corporation
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
This article is reproduced from Parallel Universe Magazine series on tuning utilities in Intel® MPI Library. For previous tuning articles, see Issue 41 (Page 53) and Issue 42 (Page 43). While the previous articles primarily focused on application-specific tuning tools and methodologies, this one focuses on cluster-wide tuning using a utility called mpitune_fast. Ideally, mpitune_fast should be run by a cluster administrator to ensure that users get an optimally tuned configuration of Intel MPI Library. However, mpitune_fast can be run by unprivileged users at any time. This article introduces mpitune_fast and describes a tuning methodology and the resulting performance gains for the Intel® MPI Benchmarks. All experiments in this article use Intel MPI Library 2019 U9. Results are presented from two clusters based on the Intel® Xeon® processor: Endeavor and the Intel® DevCloud.
The ease of use, low overhead, and potential performance gains of Autotuner inspired the Intel MPI Library development team to extend its scope beyond application-specific tuning to cluster-wide tuning. IMB is used to generate tuning data that is generalizable to most MPI applications. Combining Autotuner and IMB resulted in a cluster-wide tuning utility called mpitune_fast (Figure 1).
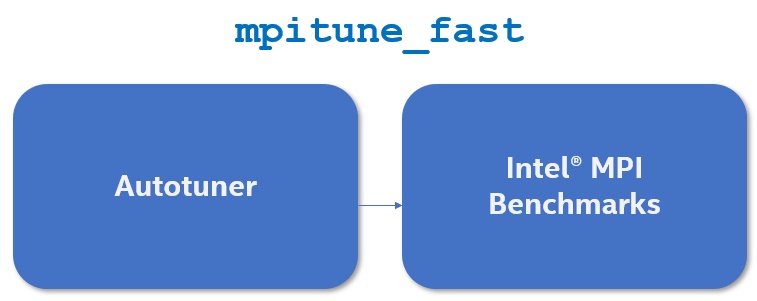
Figure 1. Components of mpitune_fast
mpitune_fast iteratively runs IMB with predefined settings to generate cluster-specific tuning parameters that are better than the Intel MPI Library default settings. The resulting configuration is stored in a file that can be used by all MPI applications running on the cluster. Cluster administrators can set the I_MPI_TUNING_BIN environment variable to point to this file so that all MPI applications running on the cluster can benefit from the mpitune_fast analysis.
Key Features of mpitune_fast
Cluster-Wide Tuning
Cluster-wide tuning refers to two capabilities:
- Generation of tuning data that remains valid for any application running on the cluster
- Generation of tuning settings that combine multiple nodes (one to Nmax ) and processes per node (one to Cmax )
Consequently, mpitune_fast only needs to be run once as long as there are no changes to the cluster configuration.
Dynamic Tuning
mpitune_fast is based on Autotuner, so it inherits dynamic tuning capabilities, which greatly reduces the overall tuning overhead and simplifies user workflows.
Parallel Tuning
mpitune_fast is a cluster-wide tuning tool, so it’s important to tune for multiple MPI rank placement schemes and a variable number of nodes. This is achieved by tuning in parallel for multiple values of processes per node (-ppn) and total number of nodes (-n), whenever possible. When tuning for high values of -ppn (tending towards the number of physical cores per node) and -n (tending towards the total number of nodes in the hostfile), the tuning runs are inherently serial. However, for smaller -ppn and -n values, mpitune_fast automatically launches parallel tuning instances to better use the hardware and reduce the overall tuning overhead.
Ease of Use
A design goal of mpitune_fast is to maintain a simple user workflow and invocation scheme. Therefore, any complexity associated with running IMB and Autotuner is hidden from the users. mpitune_fast carefully configures underlying tools through runtime options and environment variables.
Methodology
The following command launches mpitune_fast on clusters running the LSF or Slurm job schedulers (automatic detection of hostfile is enabled):

For clusters running other job schedulers, a file containing the list of nodes on which to run mpitune_fast must also be specified:

mpitune_fast only has a handful of arguments. They can be viewed using the following help option:

By default, mpitune_fast tunes for multiple processes per node (-ppn) and number of nodes (-n). In other words, all powers of two up to the physical core count including the physical core count for -ppn and all powers of two up to the host count. For example, for a cluster with 50 nodes and 24 physical cores per node, by default mpitune_fast tests -n values of 1, 2, 4 , 8, 16, 32, and 50 and -ppn values of 1, 2, 4, 8, 16, and 24. If common usage patterns for -n and -ppn used by jobs on a cluster are known, one may optionally limit the -ppn and -n values to one or more values (in addition to specifying custom values) by a comma-separated list:
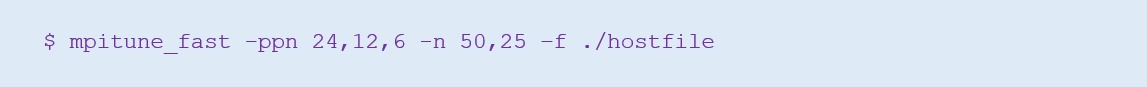
Tuning overhead may be further reduced by restricting the scope of collectives to tune using the -c option (allreduce, reduce, bcast, and barrier are tuned by default):

Running these commands generates a tuning file that can be used as the default tuning file for all MPI applications running on the cluster in question. One must be careful when using the -n option to mpitune_fast. Here, it represents the number of nodes. In the context of mpirun or mpiexec.hydra, -n represents the total number of ranks. mpitune_fast also accepts the -d option to store the tuning results in a user-specified directory.
To evaluate the performance benefits of mpitune_fast, we use IMB to measure the performance of common MPI collective communication functions: Allreduce, Bcast, Reduce, Scatter, and Gather. Our test script performed three main steps.
First, IMB was run with the default tuning configuration in Intel MPI Library using the following command:

Table 1 shows the values of variables used for this command.
Table 1. Test configuration
| Variable | Value | |
| Endeavor | DevCloud | |
| NRANKS | 768 | 96 |
| PPN | 48 | 12 |
| NODES | 16 | 8 |
| LIST | allreduce,bcast,reduce,scatter,gather | |
| REP_LARGE | 1000 | |
| MEM_LIMIT | 999,999 | |
| TIME_LIMIT | 100,000 | |
To have tighter control over the number of repetitions to run per message size in IMB, instead of running a single command to test performance over the entire 1 B to 4 MB message range, we chose to split it into three separate runs. The arguments to -iter and -msglog changed across the three executions as shown in Table 2.
Table 2. Message size driven repetition selection logic
| -iter | -mslog |
| 1,000 | 1:16 |
| 600 | 17:19 |
| 20 | 20:22 |
As shown in Table 2, we performed 1,000 repetitions for small messages of sizes 21 B to 216 B, 600 repetitions for medium messages of sizes 217 B to 219 B, and 20 repetitions for large messages of sizes 220 B to 222 B.
The performance data collected from this step served as baseline performance. We chose to track IMB’s t_max metric per message size, which is the worst observed performance across all ranks in a collective call, and therefore a safe performance measure.
We then ran mpitune_fast as an unprivileged user (to extend the scope of this article to all cluster users, not just cluster administrators):

We restricted tuning to a specified number of nodes, number of processes per node, and MPI functions of interest. This step generated a binary file with tuned settings.
Finally, the tuning file was used to assess the benefit of the mpitune_fast analysis. The following environment variable directs Intel MPI Library to use a specified tuning file:

Results
This section presents the data we collected from running the steps described in the previous section on two clusters that are based on an Intel Xeon processor: Endeavour and Intel DevCloud. On Endeavour, 16 dual-socket nodes for the Intel® Xeon® Platinum 8268 processor are connected through a Mellanox Quantum* HDR interconnect. On Intel DevCloud eight dual-socket nodes were used for the Intel® Xeon® Gold 6128 processor that are connected through an Ethernet interconnect.
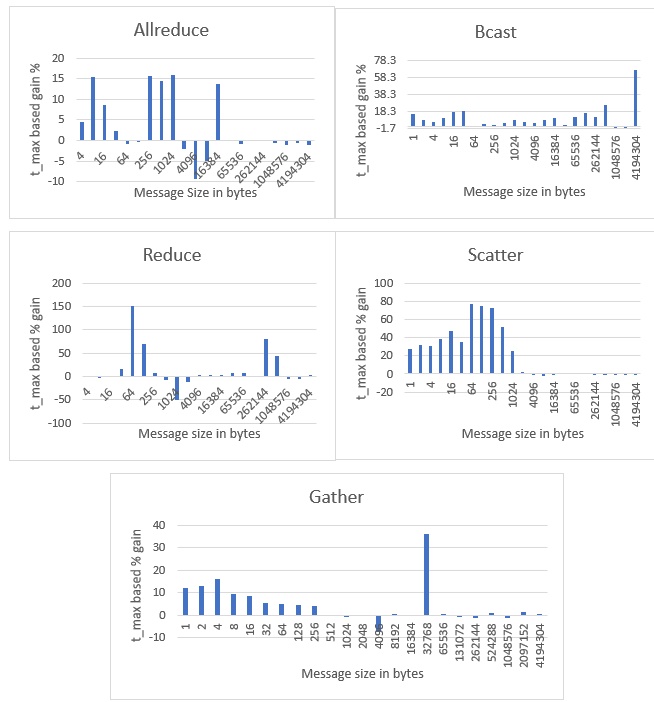
Figure 2. Performance improvement for five common MPI collective communication functions on Endeavour
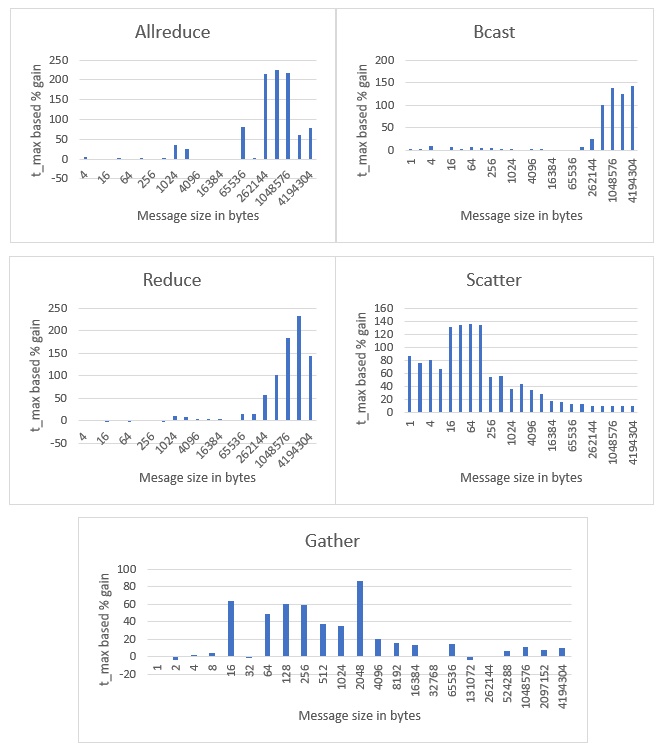
Figure 3. Performance improvement for five common MPI collective communication functions on the Intel DevCloud
Figure 2 shows the performance gains observed on Endeavour. An average gain of 11.15% was observed for all functions over the entire range of message sizes. Out of the 111 data points shown in Figure 2, five data points show some performance degradation. Developers of mpitune_fast are working on refining the tuning methodologies to eliminate such behavior. Also, such minor degradations may be attributed to noise and network traffic coming from other applications running on nodes connected to the same switch.
Figure 3 shows the performance gains observed on Intel DevCloud. An average gain of 36.35% was observed for all functions over the entire range of message sizes. Unlike Endeavour, no performance degradations were observed.
Limitations
The 2019 U9 version of mpitune_fast has the following limitations:
- Non-blocking collectives aren’t supported yet.
- By design, mpitune_fast currently only supports IMB to generate tuning data. Tuning based on user-specified benchmark applications is not supported.
- Conditional tuning specific to user-defined message sizes is not currently available.
Summary
This article introduced mpitune_fast, one of the tuning utilities in Intel MPI Library, to conveniently generate cluster-wide tuning data. Both cluster administrators and unprivileged users can run this utility. Average gains of 11.15% and 36.35% were observed for five common MPI functions on Endeavour and Intel DevCloud, respectively. While the tuning data generated by mpitune_fast is applicable to any application, Autotuner can generate application-specific tuning data, thereby providing additional performance gains in user applications. The recommended workflow is for cluster administrators to first run mpitune_fast to generate optimal Intel MPI Library tuning settings for their clusters. Cluster users can then run Autotuner to generate even better settings for their applications.
______
You May Also Like
Hybrid Parallel Programming for HPC Clusters with MPI and DPC++
Overlap Computation and Communication in HPC Applications
Intel® MPI Library
Deliver flexible, efficient, and scalable cluster messaging with this multifabric message-passing library. Intel MPI Library is included in the Intel® oneAPI HPC Toolkit.