Introduction
The GNU Compiler Collection (GCC)* team at Intel has actively worked with the GCC community to contribute innovative and performance enhancements (general and x86-specific) into GCC 12. A very-cheap cost model is used to enable vectorization at the -O2 optimization level, bringing vectorization performance gains to O2 users, with a small impact to the code size. Vectorization enabling has been boosting the performance of SPECrate* 2017 Integer suites built by GCC 12.1 O2 by 5.9% since GCC 8.5.
The x86 back end was enabled to support Intel® Advanced Vector Extensions 512 (Intel® AVX-512) for FP16, which was introduced in Intel® Xeon® processors (formerly code named Sapphire Rapids). Intel AVX-512 for FP16 can be widely used with increased throughput and decreased storage that includes signal processing, media or video processing, AI and machine learning, and more.
Several auto-vectorization enhancements have been developed for Intel AVX-512 and Intel AVX-512 for vector neural network instructions (VNNI) in the GCC 12 compiler based on the vectorization framework. Many patches were contributed, improving quality and performance for the back end.
Also, -mtune=tremont and -mtune=alderlake were fine-tuned with significant performance gains.
Generation-to-Generation Performance Improvement
As measured by SPECrate 2017 Integer suites, GCC performance was constantly improved from generation to generation on Intel® 64. As demonstrated in Figure 1, GCC 12.1 has the best performance ever on Intel 64, a 19% improvement when compared to GCC 7.5.
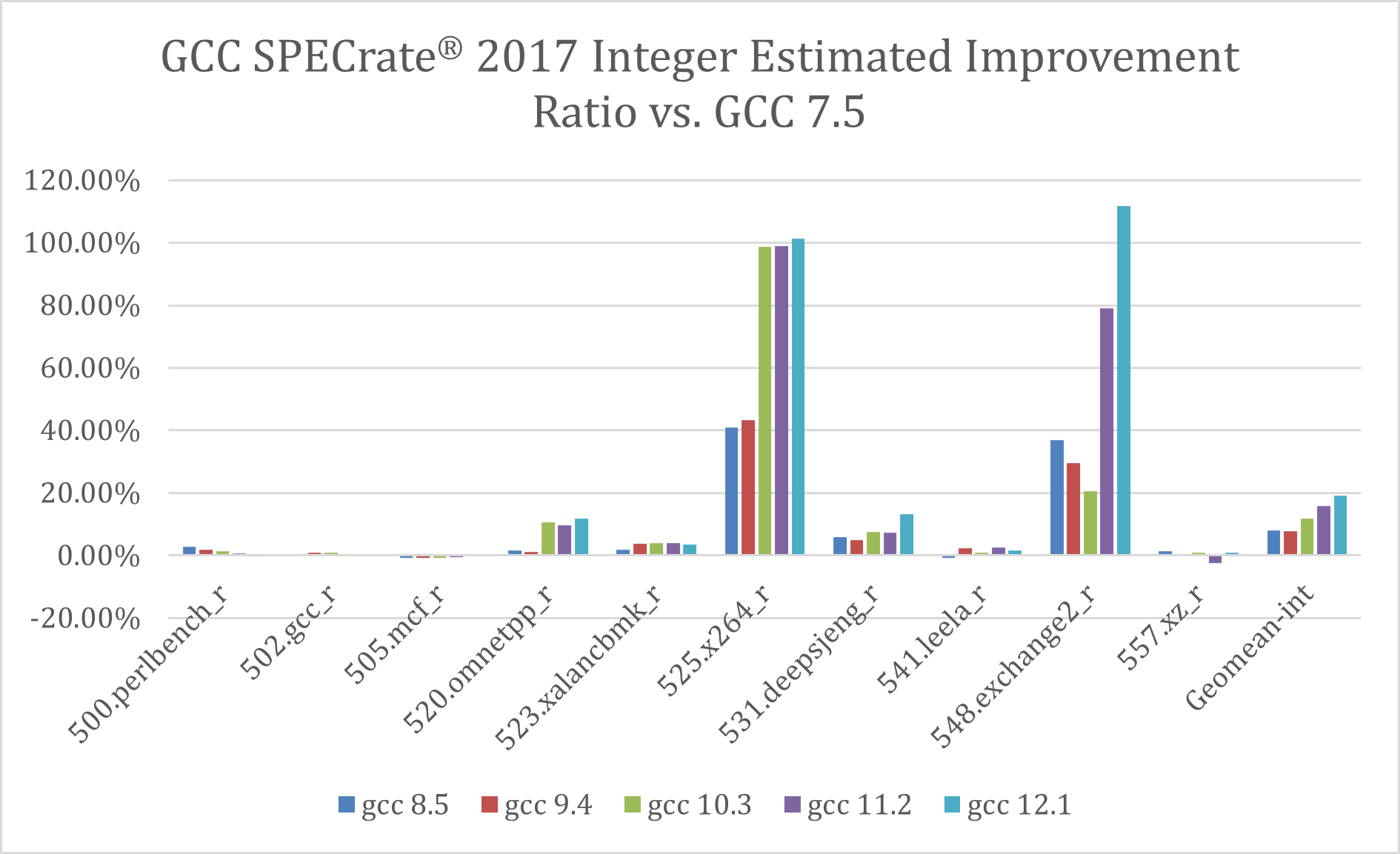
Figure 1. A generation-to-generation estimated improvement ratio of SPECrate 2017 Integer (multicore) when compared to GCC 7.5
Support for Intel® Xeon® Processors
Intel AVX-512 for FP16 instruction set architecture (ISA) was introduced for Intel® Xeon® processors (formerly code named Sapphire Rapids). It gives wide support for arithmetic operations with an IEEE 754-2019 compliant half-precision floating-point (also known officially as binary16, or unofficially as FP16). Compared to FP32 and FP64 floating-point formats, FP16 gives increased throughput and reduced storage by reducing the data range and precision. The ISA information is available in Architecture Specification. For more information, see the Technology Guide.
The _Float16 data type is supported in both C and C++ and works on hardware with or without Intel AVX-512 for FP16 instructions to give backward compatibility. Without the compiler option -mavx512fp16 or -march=sapphirerapids, the float instructions and software emulation emulate all operations on _Float16. With the option -mavx512fp16 or -march=sapphirerapids, GCC 12 compiler can automatically generate scalar and vector Intel AVX-512 for FP16 instructions. For example:
void
foo (_Float16* a, _Float16 *b, _Float16 *__restrict p)
{
for (int i = 0; i < 32; i++)
p[i] = a[i] + b[i];
}
foo:
vmovdqu16 (%rdi), %zmm0
vaddph (%rsi), %zmm0, %zmm0
vmovdqu16 %zmm0, (%rdx)
vzeroupper
ret
Figure 2. GCC (-O2 -mavx512fp16) auto-vectorize _Float16 operations
More GCC auto-vectorization on Intel AVX-512 for FP16 is described in the next section. Besides auto-vectorization, users can generate Intel AVX-512 for FP16 instructions by hundreds of intrinsics newly added in GCC 12.
Use those intrinsics with -mavx512fp16 or -march=sapphirerapids compiler options. For more information on the intrinsics, see the Intel® Intrinsics Guide.
Auto-Vectorization Enhancement
Several auto-vectorization enhancements were developed in GCC 12 compiler. One of the significant changes is that the team worked with the community to enable auto-vectorization in O2 optimization level using a very-cheap cost model. So, most of the O2 users can benefit from vector instructions while keeping the code size impact under control.
GCC did not enable auto-vectorization in the default O2 optimization level but only in O3 and higher for the sake of code size, stability, and compiling time. So, O2 users could not take advantage of performant vectorization instructions in modern architectures.
Starting from GCC 12, Intel worked with the community to enable auto-vectorization at -O2 by default using a very-cheap cost model, which does the lightest vectorization. It permits the loop vectorization if the trip count of a scalar vectorizable loop is known as a multiple of the hardware vector length, and the code size impact is not much. For example, Figure 3 shows an example of a GCC O2 auto-vectorization using Intel® Streaming SIMD Extensions 4.2 (Intel® SSE 4.2).
void ArrayAdd(int* __restrict a, int* b)
{
for (int i = 0; i < 32; i++)
a[i] += b[i];
}
ArrayAdd:
xorl %eax, %eax
.L2:
movdqu (%rdi,%rax), %xmm0
movdqu (%rsi,%rax), %xmm1
paddd %xmm1, %xmm0
movups %xmm0, (%rdi,%rax)
addq $16, %rax
cmpq $128, %rax
jne .L2
ret
Figure 3. GCC (-O2) auto-vectorization example
GCC vectorization for the _Float16 type was enabled to generate corresponding Intel AVX-512 for FP16 instructions. In addition to Single Instruction Multiple Data (SIMD) instructions that are similar to their float or double variants, the vectorizer also supports vectorization for the complex _Float16 type. For example, Figure 4 performs a conjugate complex multiply and accumulate operations on three arrays, and the vectorizable loop can be optimized to generate vfcmaddcph instruction.
#include<complex.h>
void fmaconj (_Complex _Float16 a[restrict 16],
_Complex _Float16 b[restrict 16],
_Complex _Float16 c[restrict 16]) {
for (int i = 0; i < 16; i++)
c[i] += a[i] * ~b[i];
}
fmaconj:
vmovdqu16 (%rdx), %zmm0
vmovdqu16 (%rdi), %zmm1
vfcmaddcph (%rsi), %zmm1, %zmm0
vmovdqu16 %zmm0, (%rdx)
vzeroupper
ret
Figure 4. GCC(-Ofast -mavx512fp16) auto-vectorization of using Intel AVX-512 for FP16 vfcmaddcph instruction
Auto-vectorization was enhanced to perform idiom recognition (such as the dot-production idiom) that triggers instruction generation for Intel AVX and Intel AVX-512 for VNNI. Figure 5 shows that the compiler generates the vpdpbusd instruction plus a sum reduction.
int usdot_prod_qi (unsigned char * restrict a,
char *restrict b, int c, int n) {
for (int i = 0; i < 32; i++) {
c += ((int) a[i] * (int) b[i]);
}
return c;
}
usdot_prod_qi:
vmovdqu (%rdi), %ymm0
vpxor %xmm1, %xmm1, %xmm1
vpdpbusd (%rsi), %ymm0, %ymm1
vmovdqa %xmm1, %xmm0
vextracti128 $0x1, %ymm1, %xmm1
vpaddd %xmm1, %xmm0, %xmm0
vpsrldq $8, %xmm0, %xmm1
vpaddd %xmm1, %xmm0, %xmm0
vpsrldq $4, %xmm0, %xmm1
vpaddd %xmm1, %xmm0, %xmm0
vmovd %xmm0, %eax
addl %edx, %eax
vzeroupper
ret
Figure 5: Intel AVX-512 for VNNI idiom recognition in a
GCC(-O2 -mavx512vl -mavx512vnni) auto-vectorization
GCC now generates vpopcnt[b,w,d,q] instructions when the vectorizer recognizes a redundant zero extension and truncation. These improvements significantly extend GCC auto-vectorization capability for Intel® Xeon® Scalable Processors.
Codegen Optimizations for the x86 Back End
Several codegen optimizations have been developed in GCC 12.
_atomic_fetch_{xor,or,and} Optimization
The spin loop for __atomic_fetch_{xor,or,and} was optimized out for certain cases. For unoptimized cases, an option -mrelax-cmpxchg-loop was added in GCC 12 to relax a spin loop, benefiting thread synchronization. In GCC 12, the option is off by default. Figure 6 is an example of the compiler optimizing __atomic_fetch_or with a lightweight lock bts.
int
f1 (int *a, int bit)
{
int mask = 1 << bit;
return (__sync_fetch_and_or (a, mask) & mask) != 0;
}
f1:
movl %esi, %ecx
xorl %eax, %eax
lock btsl %esi, (%rdi)
setc %al
sall %cl, %eax
testl %eax, %eax
setne %al
movzbl %al, %eax
ret
Figure 6. GCC(-O2) optimizes __atomic_fetch_or with lock bts
Ternary Logic Operation Optimization
A single vpternlog instruction optimized the ternary logic operation sequence. The example in Figure 7 demonstrates that GCC 12 generates vpternlogq for (a & ~b) | (c & b).
#include<immintrin.h>
__m256i
__attribute__((target("avx512vl")))
foo (__m256i src1, __m256i src2, __m256i src3)
{
return (src2 & ~src1) | (src3 & src1);
}
foo:
vpternlogq $202, %ymm1, %ymm2, %ymm0
ret
Figure 7. A truth-table reduction to ternary logic operations vpternlog with GCC(-O2)
Inline Math Function ldexp
Instead of a libcall, the GCC 12 compiler inlined the math function ldexp with the Intel AVX 512 vscalefsd instruction. Figure 8 shows an example.
double
foo (double a, int b)
{
return __builtin_ldexp (a, b);
}
foo:
vxorps %xmm1, %xmm1, %xmm1
vcvtsi2sdl %edi, %xmm1, %xmm1
vscalefsd %xmm1, %xmm0, %xmm0
ret
Figure 8. GCC(-Ofast -mavx512vl) converts b from int to double and uses vscalefsd
Disable Copy Relocation with -mno-direct-extern-access
A compiler option -mno-direct-extern-access now disables copy relocation (the default is ON). It always uses a global offset table (GOT) to access external data and function symbols with the option. Without copy relocation, access to defined symbols in shared libraries can be optimized with protected visibility.
Microarchitecture Tuning
Modifying -mtune=tremont and -mtune=alderlake significantly improved performance. Both were tested with a SPECrate 2017 benchmark and observed significant improvement. For the SPECrate 2017 single core, -mtune=tremont improved integer suites by 0.95%, floating-point suites by 7.5%, while -mtune=alderlake improved floating-point suites by 4.48% for E-core, 3.43% for P-core. Figures 9-11 show more details about the improvements.
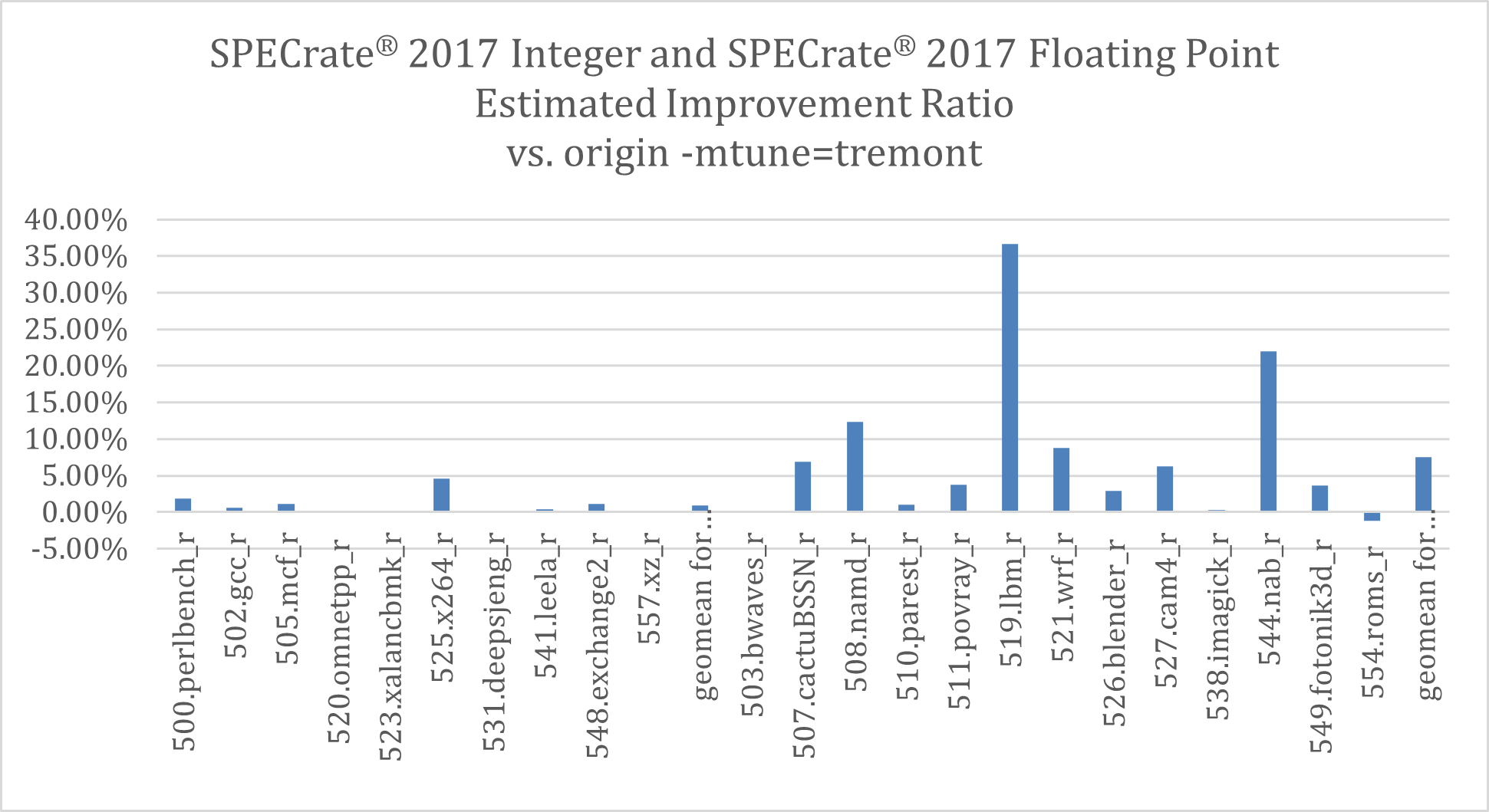
Figure 9. Tuning with -mtune=tremont

Figure 10. Tuning with -mtune=alderlake

Figure 11. Tuning with -mtune=alderlake
Future Work
The GCC team at Intel is continuing to enhance the vectorization, improve performance, bring more new features to Intel® platforms, and fix issues to increase the code quality in the coming releases.