
When working with microservices, where multiple services are interconnected and constantly communicating, security becomes a paramount concern for preventing unauthorized access and data breaches. Many organizations use a service mesh, a dedicated infrastructure layer for microservices that provides traffic management, security, and observability capabilities. However, service meshes can leave private keys exposed to attacks and result in performance penalties. With the right technologies and tools, developers can significantly enhance the inherent security and speed of their service meshes.
In this post, we’ll guide you through how you can bolster the security and performance of your service mesh deployments using Istio, an open source service mesh, and Envoy, a sidecar proxy. We’ll focus on how Intel® hardware capabilities can be leveraged to secure private keys and accelerate demanding operations such as TLS handshakes, regular expression matching, and load balancing, thereby enabling a more secure and efficient service mesh environment.
We’ll also demonstrate how to install Intel® QuickAssist Technology (Intel® QAT) to help you run your workloads with reduced latency and increased throughput. Watch the full demo here.
Secure your Service Mesh
Security is a key feature of the Istio service mesh. However, in a default Istio mesh deployment, private keys for the certificate authority (CA), gateway, and mutual TLS (mTLS) are stored in clear text in Kubernetes or in the sidecar without encryption, leaving mesh communications vulnerable to attackers.
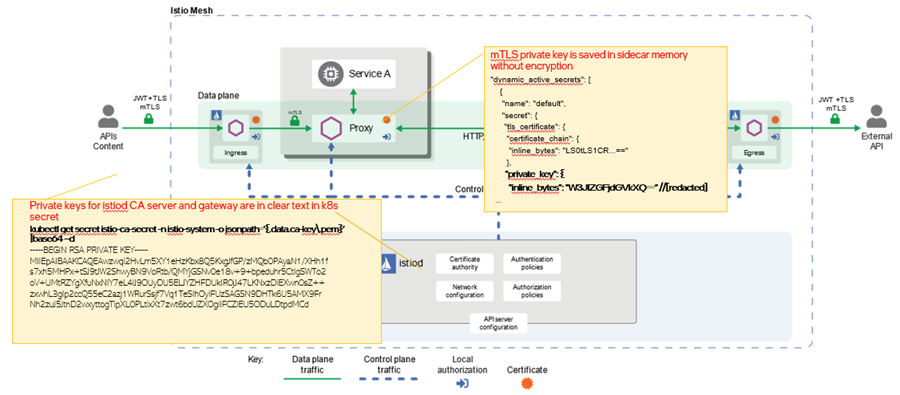
In a default upstream Istio mesh deployment, private keys for the CA, gateway, and mTLS are unencrypted and vulnerable to cyberattacks.
Intel® service mesh provides a secure solution to safeguard private keys via Intel® Software Guard Extensions (Intel® SGX). Intel SGX helps protect data actively being used in the processor and memory by creating a hardware-enforced trusted execution environment (TEE) , called an enclave. Outside the enclave data is encrypted, while inside the enclave only authorized software or parties may access data. Users can store and use the private keys inside the Intel SGX enclave to help ensure communications are secure. The solution relies purely on the Intel® Xeon® processors , so you can take advantage of secure enclaves without needing any additional hardware. Visit the GitHub repo to try this secure solution.
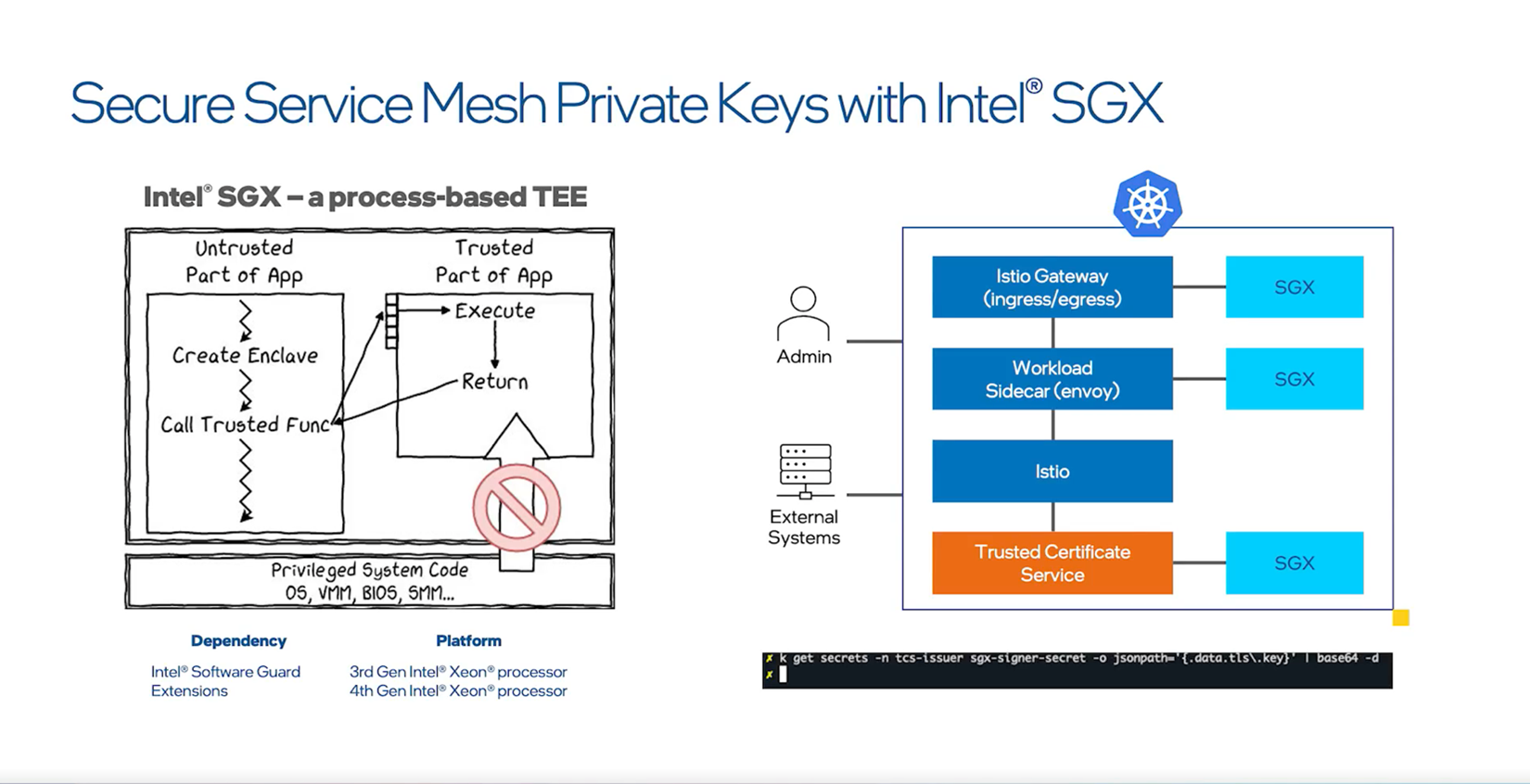
The Intel® service mesh solution provides secure enclaves to protect private keys.
Boost Performance
In many deployments, service meshes add sidecar proxies , which are additional functions that run alongside containers in a platform-agnostic manner and are often used to enable traffic management, security control, and observability. Istio, for example, uses the sidecar proxy Envoy to handle data plane traffic. This often results in a workload performance penalty, but there are a few ways Intel service mesh can help you accelerate data plane traffic.
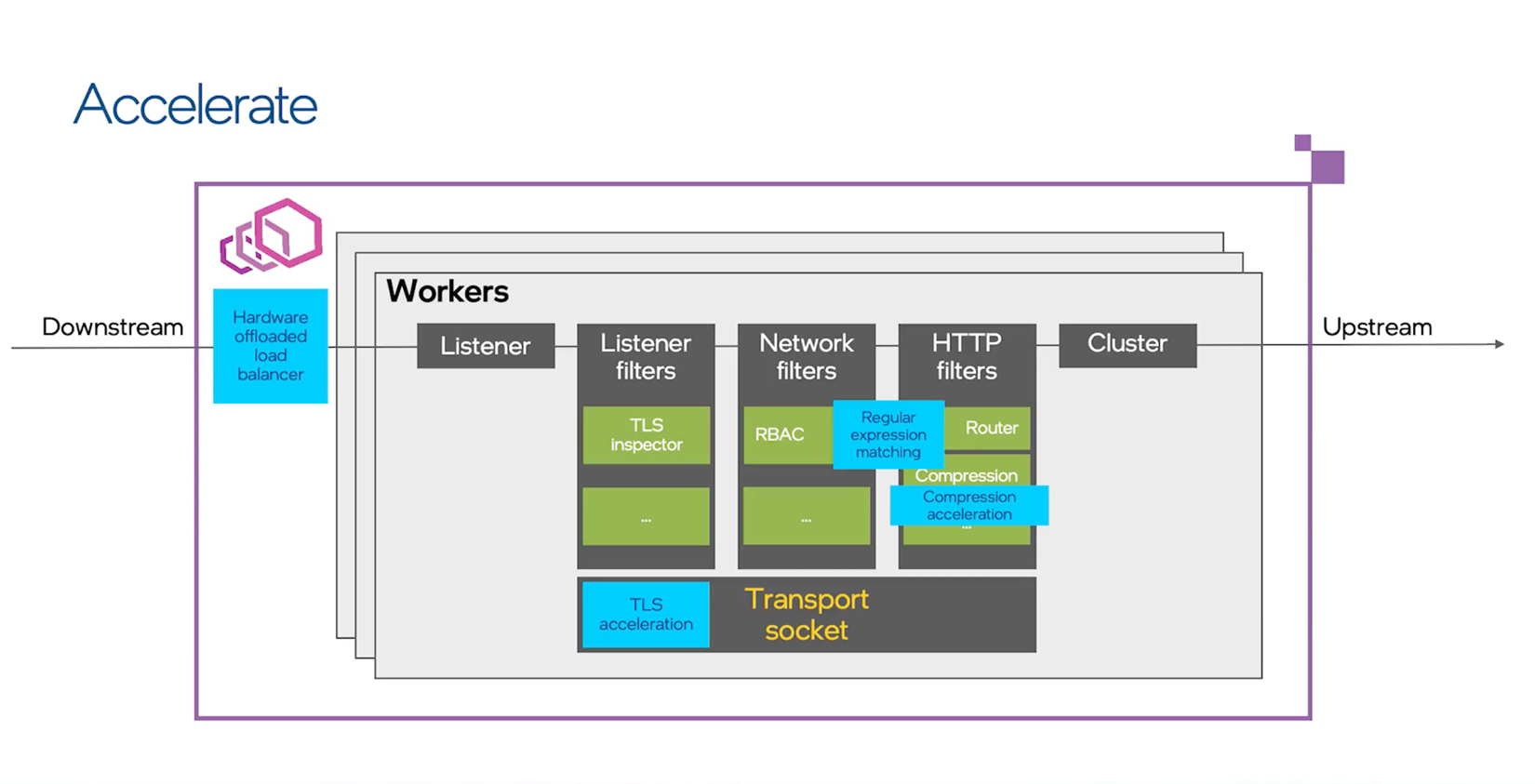
Intel® service mesh adds hardware capabilities (in blue) to accelerate throughput.
TLS Handshake Acceleration via Intel QAT and CryptoMB
The service mesh gateway must handle many concurrent connections, and TLS handshakes are a CPU-intensive operation. Intel QAT is a hardware accelerator that is available starting from 4th Gen Intel® Xeon® Scalable processors. In a Kubernetes environment, the Intel QAT device plugin will pass Intel QAT virtual functions to the workload pod. The Envoy private key provider delegates sign/decrypt operations to the Intel QAT device asynchronously, freeing up CPU cycles and boosting overall performance.
For even more TLS handshake acceleration, you can take advantage of the CryptoMB private key provider, an Envoy extension that handles demanding cryptographic operations. The multibuffer cryptography is implemented with Intel® Advanced Vector Extensions 512 (Intel® AVX-512) instructions using a SIMD (single instruction, multiple data) mechanism. Up to eight RSA or ECDSA operations are gathered into a buffer and processed at the same time, providing greater throughput than processing separately. Intel AVX-512 is available starting from 3rd Gen Intel® Xeon® Scalable processors.
Intel® QAT and CryptoMB improve overall performance, with Intel QAT providing the best performance for both requests per second and latency.
Regular Expression Matching Acceleration
Envoy uses regular expression (regex) matching in multiple places, such as filter matching, access matching, and routing matching. When using RE2, Envoy’s default regular expression matching engine, this process can take a long time, especially when the routine rules have more entries.
Hyperscan is a high-performance, multiple-regex matching library based on Intel AVX-512. Hyperscan has been implemented in Envoy both as an input matcher and a generic matcher, enabling you to easily replace RE2 with Hyperscan for nearly every regex in the data plane. Doing so delivers performance boosts for both latency and queries per second (QPS).
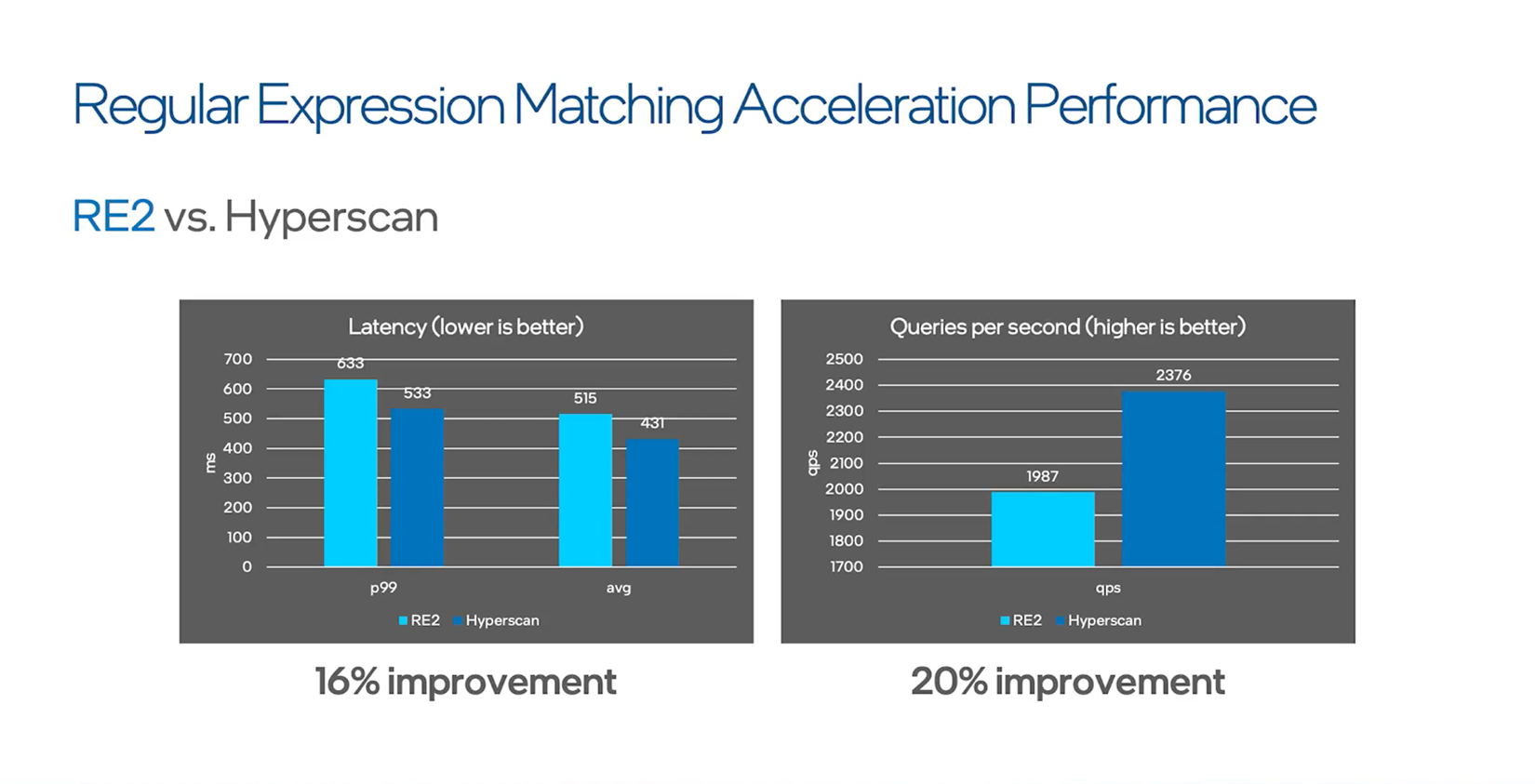
Hyperscan delivers a 16 percent improvement in latency and a 20 percent improvement in queries per second.
Load Balancer Optimization with Intel® DLB
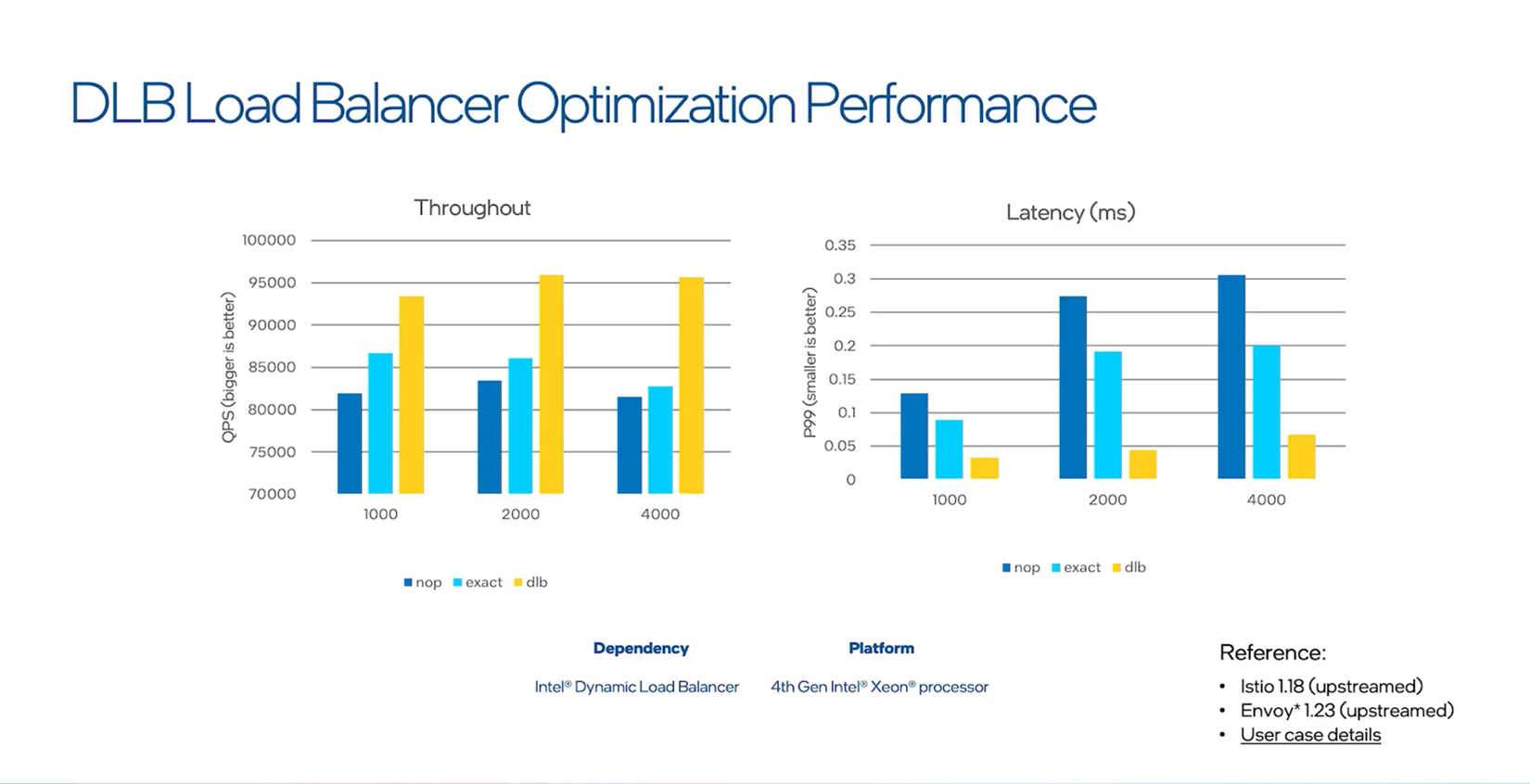
Intel® Dynamic Load Balancer (Intel® DLB) is a hardware-managed system of queues and arbiters that connect producers and consumers. As a PCI device in the server CPU uncore that interacts with software running on cores, Intel DLB provides lock-free multiple consumer-producer operations. Intel DLB is integrated in select Intel Xeon processors to optimize CPU cores and memory.
Envoy uses Linux kernel for scheduling incoming connections to different Envoy worker threads. The dispatch is based purely on hash computing and is unbalanced on the CPU cores, resulting in some worker threads being busy while other threads are idle. By using Intel DLB as a load balancer, Envoy can detect each queue’s status and dispatch client requests in the most precise and efficient way.
Intel® DLB offers better throughput and latency compared to Envoy’s connection load balance implementation, which is called Exact connection balance, and no load balancer.
Demo: Accelerating TLS Handshakes with Intel QAT
Let’s walk through how to use Intel QAT to accelerate TLS handshakes.
Preparation and Installation
First, verify that the Intel QAT device plugin is installed and working. Then check to make sure the Intel QAT devices are present in the Kubernetes node.
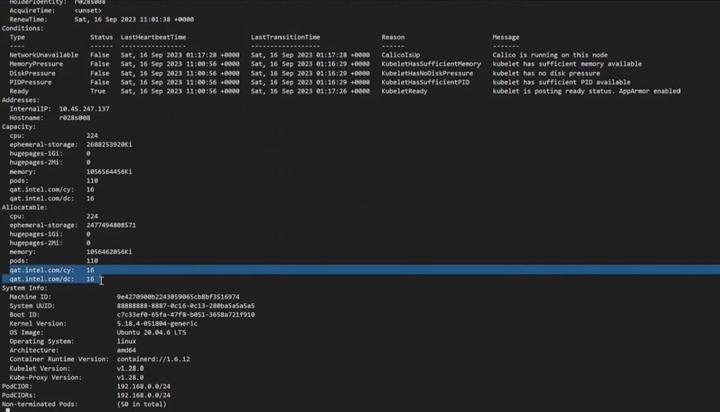
Verify that the Intel® QAT devices are present in your Kubernetes node.
Next, place the Intel QAT devices into the ingress gateway using the Istio operator. In this deployment, we’re allocating four cy and dc Intel QAT devices to the ingress gateway and using Intel QAT as the private key provider.
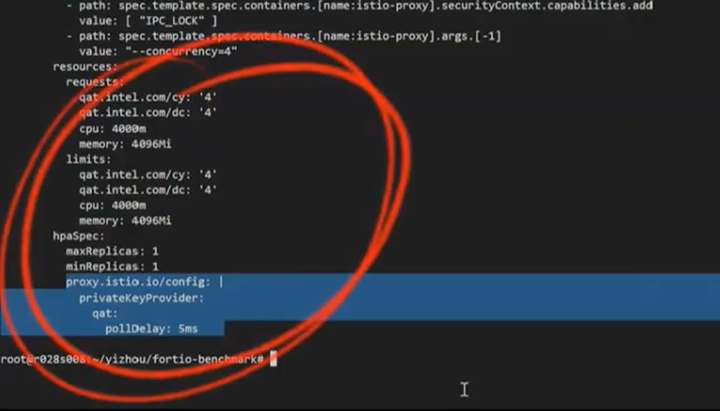
In your configuration file, place the Intel® QAT devices in the ingress gateway and enable Intel QAT as the private key provider.
Then, clean up the environment and install Istio, which should take a few seconds.
Benchmark on the Gateway with Intel QAT
With Istio installed, you’re ready to install and run the Fortio server, which will serve as the workload. We’ll send the request from the Fortio client through the ingress gateway to see how it behaves with Intel QAT acceleration. In this example, the ingress gateway is hosted on fortio.com:38878, and the connection is about 2,000. It should take a minute or so to finish the requests.
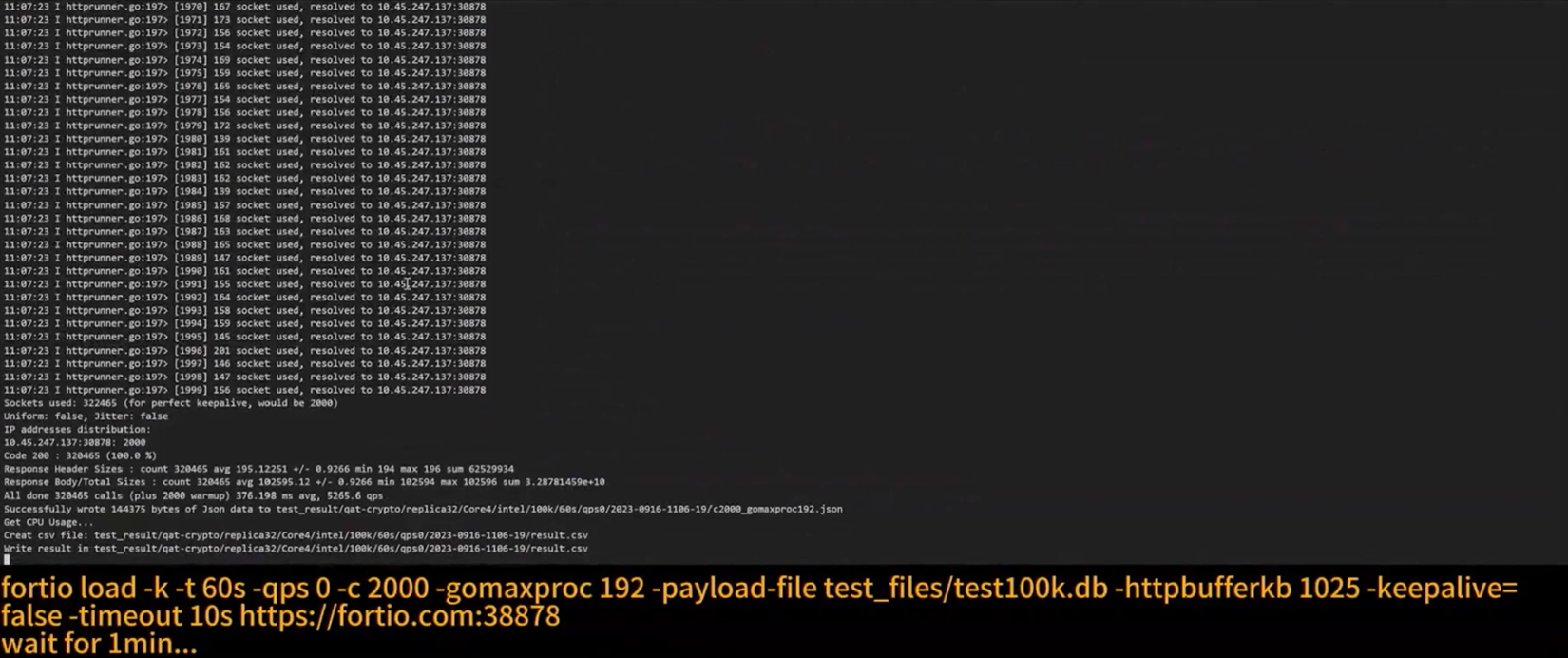
The Fortio client sends requests via the ingress gateway to our workload to benchmark its behavior with Intel® QAT acceleration enabled.
Compare the Results
Once the request is finished running, the benchmark results will be written into a CSV file. Using Intel QAT acceleration, the Fortio server workload has an average latency of 0.376 milliseconds (ms), which is half the latency of the same workload without Intel QAT. Additionally, the Intel QAT-enabled workload has nearly double the average throughput of the workload without Intel QAT.
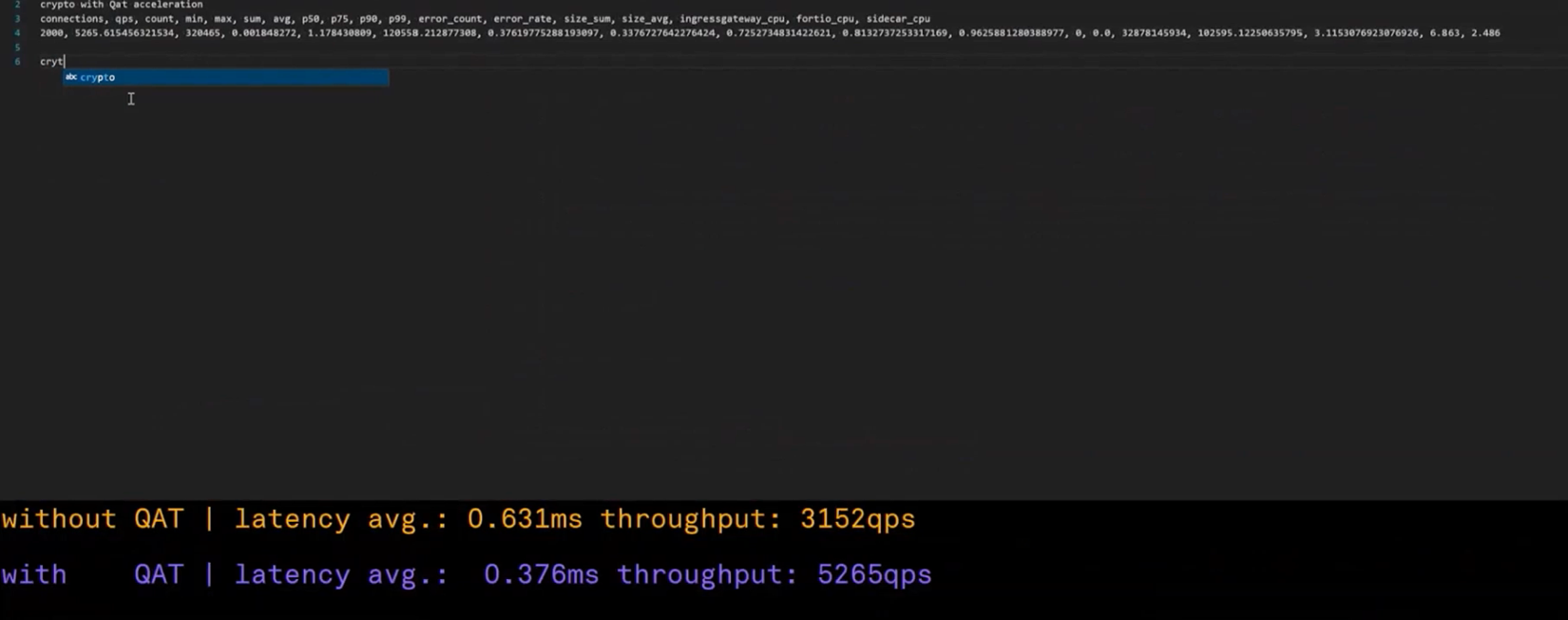
Intel® QAT acceleration delivers almost half the latency and double the throughput as running the same workload without Intel QAT.
Optimize Your Service Mesh
Service meshes offer powerful security and observability features but often come with performance tradeoffs. By leveraging the Intel service mesh solution that takes advantage of key hardware-enabled Intel® technologies, developers can enhance the security of their Istio service mesh deployments while boosting performance. These technologies include Intel SGX, which provides a secure enclave to help protect data in use and safeguard private keys, and Intel QAT, Intel AVX-512, and Intel DLB, which accelerate TLS handshakes, regex matching, and load balancing for better overall performance.
Explore our open source resources below, designed to help you deliver secure, accelerated service mesh deployments.
About the Author
Mrittika Ganguli, Principal Engineer and Architect, Intel
Mrittika Ganguli is a principal engineer and architect with more than 25 years of expertise in cloud native networking, orchestration, telemetry, and service mesh.
Iris Ding, Service Mesh Architect, Intel
Iris Ding is a service mesh architect on Intel’s IAGS team and is currently focused on research in cloud native areas such as Kubernetes and service mesh. She has a rich background in open source development, cloud computing, and middleware development and design.