Introduction
The Storage Performance Development Kit (SPDK) is an open source set of tools and libraries hosted on GitHub that helps developers create high-performance and scalable storage applications. This tutorial will focus on the userspace NVMe driver provided by SPDK and will show you a Hello World example running on an Intel® architecture platform.
Hardware and Software Configuration
| CPU and Chipset |
Intel® Xeon® processor E5-2697 v2 @ 2.7 GHz
|
| Memory |
Memory size: 8 GB (8X8 GB) DDR3 1866 Brand/model: Samsung – M393B1G73BH0* |
| Storage | Intel® SSD DC P3700 Series |
| Operating System |
CentOS* 7.2.1511 with kernel 3.10.0 |
Why is There a Need for a Userspace NVMe Driver?
Historically, storage devices have been orders of magnitude slower than other parts of a computer system, such as RAM and CPU. This meant that applications would interact with storage via the operating system using interrupts:
- A request is made to the OS to read data from a disk.
- The driver processes the request and communicates with the hardware.
- The disk platter is spun up.
- The needle is moved across the platter to start reading data.
- Data is read and copied into a buffer.
- An interrupt is generated, notifying the CPU that the data is now ready.
- Finally, the data is read from the buffer.
The interrupt model does incur an overhead; however, historically this has been significantly smaller than the latency of disk-based storage devices, and therefore using interrupts has proved effective. Storage devices such as solid-state drives (SSDs) and next-generation technology like 3D XPoint™ storage are now significantly faster than disks and the bottleneck has moved away from hardware (e.g., disks) back to software (e.g., interrupts + kernel) as Figure 1 shows:
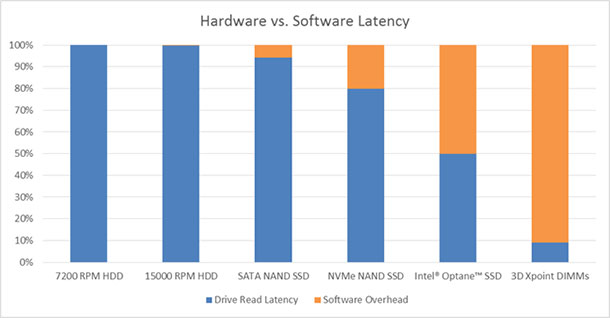
Figure 1. Solid state drives (SSDs) and 3D XPoint™ storage are significantly faster than disks. Bottlenecks have moved away from hardware.
The software latency proportion in Figure 1 above is a fixed quantity based on measurements of the Linux block stack, while the drive latency varies to reflect the capabilities of representative examples of each given class of device. Note that this is a “best case scenario” for software overhead, neglecting any application software overhead above the driver stack.
The SPDK NVMe device driver uses three techniques to minimize software (driver) overhead: avoiding interrupts, avoiding system calls, and avoiding locks. The SPDK NVMe driver addresses the issue of interrupt latency by instead polling the storage device. While this would be prohibitive for single-core CPUs, with modern CPUs containing many cores, the relative cost of dedicating a core to polling can be quite low. As shown in Figure 2, devoting a single core to polling can actually save a significant number of CPU cycles in high-I/O workloads: the crossover is approximately 500k I/O operations per second, roughly the saturation point of a single Intel® Optane™ SSD DC P4800X, and the single CPU core running the SPDK can process roughly 3.6M I/O per second.
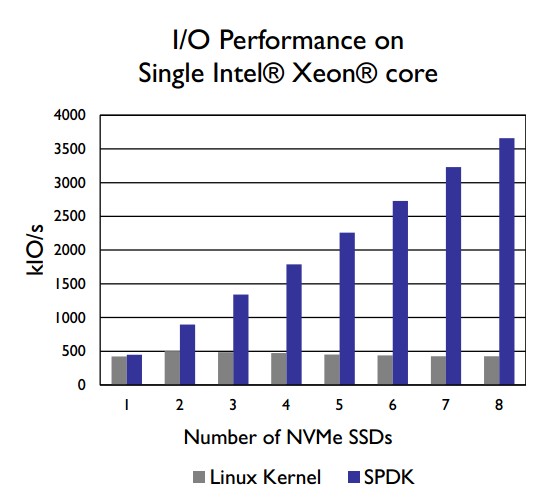
Figure 2. Dedication of a single core to polling can save a significant number of CPU cycles in high-I/O workloads.
Additionally and importantly, the NVMe driver operates within userspace, which means the application is able to directly interface with the NVMe device without going through the kernel. The invocation of a system call is called a context switch and this incurs an overhead as the state has to be both stored and then restored when interfacing with the kernel. A userspace device driver bypasses this context switch, further reducing processing latency. Finally, the NVMe driver uses a lockless design, avoiding the use of CPU cycles synchronizing data between threads. This lockless approach also supports parallel IO command execution.The results of this approach to latency reduction can be seen in Figure 3. When comparing the SPDK userspace NVMe driver to the Linux Kernel 4.4, the latency is up to 10x lower:
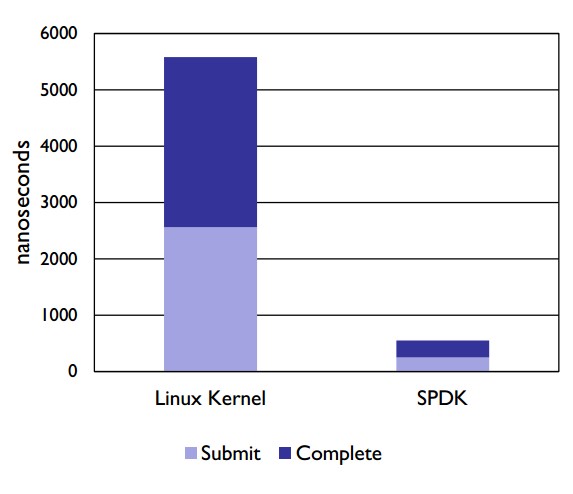
Figure 3. A comparison of latency between the SPDK userspace NVMe driver and the Linux Kernel 4.4.
Note that this comparison is with an older longterm maintenance kernel – more recent kernel versions (e.g. 4.11) have adopted polling techniques to improve support for low-latency media and may come closer to SPDK.
Prerequisites and Building SPDK
SPDK has known support for Fedora*, CentOS*, Ubuntu*, Debian*, and FreeBSD*. A full list of prerequisite packages can be found here.
Before building SPDK, you are required to first install the Data Plane Development Kit (DPDK) as SPDK relies on the memory management and queuing capabilities already found in DPDK. DPDK is a mature library typically used for network packet processing and has been highly optimized to manage memory and queue data with low latency.
The source code for SPDK can be cloned from GitHub using the following:
git clone https://github.com/spdk/spdk.git
Building DPDK (for Linux*):
cd /path/to/build/spdk
wget http://fast.dpdk.org/rel/dpdk-16.07.tar.xz
tar xf dpdk-16.07.tar.xz
cd dpdk-16.07 && make install T=x86_64-native-linuxapp-gcc DESTDIR=.
Building SPDK (for Linux):
Now that we have DPDK built inside of the SPDK folder, we need to change directory back to SPDK and build SPDK by passing the location of DPDK to make:
cd /path/to/build/spdk
make DPDK_DIR=./dpdk-16.07/x86_64-native-linuxapp-gcc
Setting Up Your System Before Running an SPDK Application
The command below sets up hugepages as well as unbinds any NVMe and I/OAT devices from the kernel drivers:
sudo scripts/setup.sh
Using hugepages is important to performance as they are 2MiB in size compared to the default 4KiB page size and this reduces the likelihood of a Translation Lookaside Buffer (TLB) miss. The TLB is a component inside a CPU responsible for translating virtual addresses into physical memory addresses and therefore using larger pages (hugepages) results in efficient use of the TLB.
Getting Started with ‘Hello World’
SPDK includes a number of examples as well as quality documentation to quickly get started. We will go through an example of storing ‘Hello World’ to an NVMe device and then reading it back into a buffer.
Before jumping to code it is worth noting how NVMe devices are structured and provide a high-level example of how this will utilize the NVMe driver to detect NVMe devices, write and then read data.
An NVMe device (also called an NVMe controller) is structured with the following in mind:
- A system can have one or more NVMe devices.
- Each NVMe device consists of a number of namespaces (it can be only one).
- Each namespace consists of a number of Logical Block Addresses (LBAs).
This example will go through the following steps:
Setup
- Initialize the DPDK Environment Abstraction Layer (EAL). -c is a bitmask of the cores to run on, -n is the core ID for the master and --proc-type is the directory where a hugetlbfs is mounted.
static char *ealargs[] = { "hello_world", "-c 0x1", "-n 4", "--proc-type=auto", }; rte_eal_init(sizeof(ealargs) / sizeof(ealargs[0]), ealargs); - Create a request buffer pool that is used internally by SPDK to store request data for each I/O request:
request_mempool = rte_mempool_create("nvme_request", 8192, spdk_nvme_request_size(), 128, 0, NULL, NULL, NULL, NULL, SOCKET_ID_ANY, 0); - Probe the system for NVMe devices:
rc = spdk_nvme_probe(NULL, probe_cb, attach_cb, NULL); - Enumerate the NVMe devices, returning a boolean value to SPDK as to whether the device should be attached:
static bool probe_cb(void *cb_ctx, struct spdk_pci_device *dev, struct spdk_nvme_ctrlr_opts *opts) { printf("Attaching to %04x:%02x:%02x.%02x\n", spdk_pci_device_get_domain(dev), spdk_pci_device_get_bus(dev), spdk_pci_device_get_dev(dev), spdk_pci_device_get_func(dev)); return true; } - The device is attached; we can now request information about the number of namespaces:
static void attach_cb(void *cb_ctx, struct spdk_pci_device *dev, struct spdk_nvme_ctrlr *ctrlr, const struct spdk_nvme_ctrlr_opts *opts) { int nsid, num_ns; const struct spdk_nvme_ctrlr_data *cdata = spdk_nvme_ctrlr_get_data(ctrlr); printf("Attached to %04x:%02x:%02x.%02x\n", spdk_pci_device_get_domain(dev), spdk_pci_device_get_bus(dev), spdk_pci_device_get_dev(dev), spdk_pci_device_get_func(dev)); snprintf(entry->name, sizeof(entry->name), "%-20.20s (%-20.20s)", cdata->mn, cdata->sn); num_ns = spdk_nvme_ctrlr_get_num_ns(ctrlr); printf("Using controller %s with %d namespaces.\n", entry->name, num_ns); for (nsid = 1; nsid <= num_ns; nsid++) { register_ns(ctrlr, spdk_nvme_ctrlr_get_ns(ctrlr, nsid)); } } - Enumerate the namespaces to retrieve information such as the size:
static void register_ns(struct spdk_nvme_ctrlr *ctrlr, struct spdk_nvme_ns *ns) { printf(" Namespace ID: %d size: %juGB\n", spdk_nvme_ns_get_id(ns), spdk_nvme_ns_get_size(ns) / 1000000000); } - Create an I/O queue pair to submit read/write requests to a namespace:
ns_entry->qpair = spdk_nvme_ctrlr_alloc_io_qpair(ns_entry->ctrlr, 0);Reading/writing data
- Allocate a buffer for the data that will be read/written:
sequence.buf = rte_zmalloc(NULL, 0x1000, 0x1000); - Copy ‘Hello World’ into the buffer:
sprintf(sequence.buf, "Hello world!\n"); - Submit a write request to a specified namespace providing a queue pair, pointer to the buffer, index of the LBA, a callback for when the data is written, and a pointer to any data that should be passed to the callback:
rc = spdk_nvme_ns_cmd_write(ns_entry->ns, ns_entry->qpair, sequence.buf, 0, /* LBA start */ 1, /* number of LBAs */ write_complete, &sequence, 0); - The write completion callback will be called synchronously.
- Submit a read request to a specified namespace providing a queue pair, pointer to a buffer, index of the LBA, a callback for the data that has been read, and a pointer to any data that should be passed to the callback:
rc = spdk_nvme_ns_cmd_read(ns_entry->ns, ns_entry->qpair, sequence->buf, 0, /* LBA start */ 1, /* number of LBAs */ read_complete, (void *)sequence, 0); - The read completion callback will be called synchronously.
- Poll on a flag that marks the completion of both the read and write of the data. If the request is still in flight we can poll for the completions for a given queue pair. Although the actual reading and writing of the data is asynchronous, the spdk_nvme_qpair_process_completions function checks and returns the number completed I/O requests and will also call the read/write completion callbacks described above:
while (!sequence.is_completed) { spdk_nvme_qpair_process_completions(ns_entry->qpair, 0); } - Release the queue pair and complete any cleanup before exiting:
spdk_nvme_ctrlr_free_io_qpair(ns_entry->qpair);
The complete code sample for the Hello World application described here is available on GitHub, and API documentation for the SPDK NVME driver is available at www.spdk.io
Running the Hello World example should give the following output:
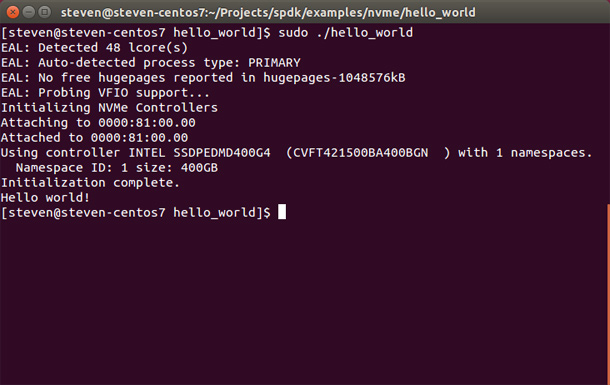
Other Examples Included with SPDK
SPDK includes a number of examples to help you get started and build an understanding of how SPDK works quickly. Here is the output from the perf example that benchmarks the NVMe drive:
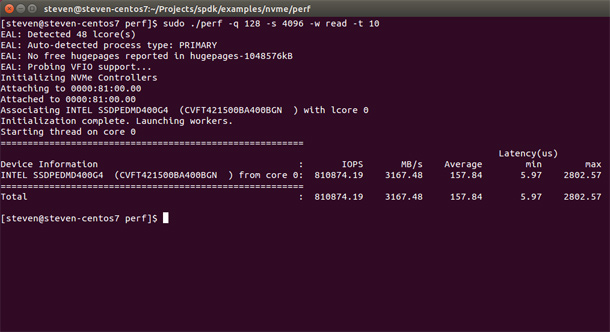
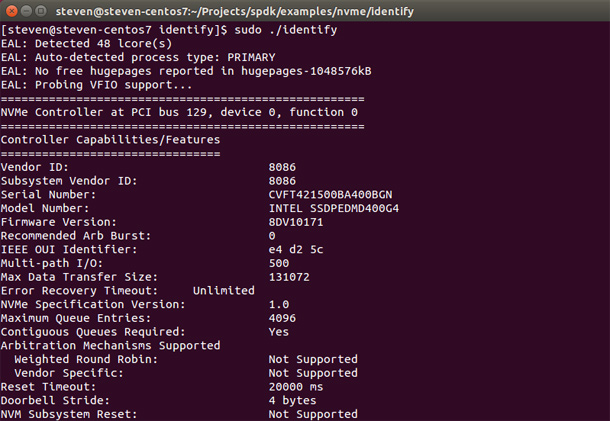
Developers that require access to the NVMe drive information such as features, admin command set attributes, NVMe command set attributes, power management, and health information can use the identify example:
Other Useful Links
- SPDK website
- SPDK documentation
- SPDK Introductory Video
- Accelerating Data Deduplication with ISA-L blog post
Authors
Steven Briscoe is an Application Engineer who focuses on cloud computing within the Software Services Group at Intel (UK).
Thai Le is a Software Engineer who focuses on cloud computing and performance computing analysis at Intel.