Introduction
Solid-state storage media is in the process of taking over the data center. Current- generation flash storage enjoys significant advantages in performance, power consumption, and rack density over rotational media. These advantages will continue to grow as next-generation media enter the marketplace.
 Customers integrating current solid-state media, such as the Intel® SSD DC P3700 Series Non-Volatile Memory Express* (NVMe*) drive, face a major challenge: because the throughput and latency performance are so much better than that of a spinning disk, the storage software now consumes a larger percentage of the total transaction time. In other words, the performance and efficiency of the storage software stack is increasingly critical to the overall storage system. As storage media continues to evolve, it risks outstripping the software architectures that use it, and in coming years the storage media landscape will continue evolving at an incredible pace.
Customers integrating current solid-state media, such as the Intel® SSD DC P3700 Series Non-Volatile Memory Express* (NVMe*) drive, face a major challenge: because the throughput and latency performance are so much better than that of a spinning disk, the storage software now consumes a larger percentage of the total transaction time. In other words, the performance and efficiency of the storage software stack is increasingly critical to the overall storage system. As storage media continues to evolve, it risks outstripping the software architectures that use it, and in coming years the storage media landscape will continue evolving at an incredible pace.
To help storage OEMs and ISVs integrate this hardware, Intel has created a set of drivers and a complete, end-to-end reference storage architecture called the Storage Performance Development Kit (SPDK). The goal of SPDK is to highlight the outstanding efficiency and performance enabled by using Intel’s networking, processing, and storage technologies together. By running software designed from the silicon up, SPDK has demonstrated that millions of I/Os per second are easily attainable by using a few processor cores and a few NVMe drives for storage with no additional offload hardware. Intel provides the entire Linux* reference architecture source code under the broad and permissive BSD license and is distributed to the community through GitHub*. A blog, mailing list, and additional documentation can be found at spdk.io.
Software Architectural Overview
How does SPDK work? The extremely high performance is achieved by combining two key techniques: running at user level and using Poll Mode Drivers (PMDs). Let’s take a closer look at these two software engineering terms.
First, running our device driver code at user level means that, by definition, driver code does not run in the kernel. Avoiding the kernel context switches and interrupts saves a significant amount of processing overhead, allowing more cycles to be spent doing the actual storing of the data. Regardless of the complexity of the storage algorithms (deduplication, encryption, compression, or plain block storage), fewer wasted cycles means better performance and latency. This is not to say that the kernel is adding unnecessary overhead; rather, the kernel adds overhead relevant to general-purpose computing use cases that may not be applicable to a dedicated storage stack. The guiding principle of SPDK is to provide the lowest latency and highest efficiency by eliminating every source of additional software overhead.
Second, PMDs change the basic model for an I/O. In the traditional I/O model, the application submits a request for a read or a write, and then sleeps while awaiting an interrupt to wake it up once the I/O has been completed. PMDs work differently; an application submits the request for a read or write, and then goes off to do other work, checking back at some interval to see if the I/O has yet been completed. This avoids the latency and overhead of using interrupts and allows the application to improve I/O efficiency. In the era of spinning media (tape and HDDs), the overhead of an interrupt was a small percentage of the overall I/O time, thus was a tremendous efficiency boost to the system. However, as the age of solid-state media continues to introduce lower-latency persistent media, interrupt overhead has become a non-trivial portion of the overall I/O time. This challenge will only become more glaring with lower latency media. Systems are already able to process many millions of I/Os per second, so the elimination of this overhead for millions of transactions compounds quickly into multiple cores being saved. Packets and blocks are dispatched immediately and time spent waiting is minimized, resulting in lower latency, more consistent latency (less jitter), and improved throughput.
SPDK is composed of numerous subcomponents, interlinked and sharing the common elements of user-level and poll-mode operation. Each of these components was created to overcome a specific performance bottleneck encountered while creating the end-to-end SPDK architecture. However, each of these components can also be integrated into non-SPDK architectures, allowing customers to leverage the experience and techniques used within SPDK to accelerate their own software.
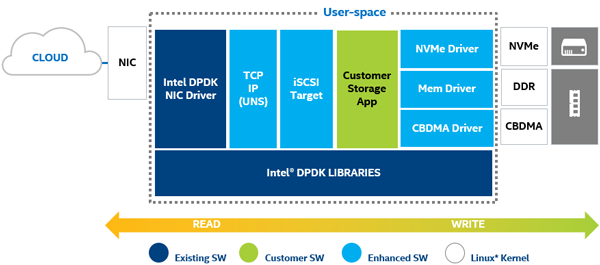
Starting at the bottom and building up:
Hardware Drivers
NVMe driver: The foundational component for SPDK, this highly optimized, lockless driver provides unparalleled scalability, efficiency, and performance.
Intel® QuickData Technology: Also known as Intel® I/O Acceleration Technology (Intel® IOAT), this is a copy offload engine built into the Intel® Xeon® processor-based platform. By providing user space access, the threshold for DMA data movement is reduced, allowing greater utilization for small-size I/Os or NTB.
Back-End Block Devices
NVMe over Fabrics (NVMe-oF) initiator: From a programmer’s perspective, the local SPDK NVMe driver and the NVMe-oF initiator share a common set of API commands. This means that local/remote replication, for example, is extraordinarily easy to enable.
Ceph* RADOS Block Device (RBD): Enables Ceph as a back-end device for SPDK. This might allow Ceph to be used as another storage tier, for example.
Blobstore Block Device: A block device allocated by the SPDK Blobstore, this is a virtual device that VMs or databases could interact with. These devices enjoy the benefits of the SPDK infrastructure, meaning zero locks and incredibly scalable performance.
Linux* Asynchronous I/O (AIO): Allows SPDK to interact with kernel devices like HDDs.
Storage Services
Block device abstraction layer (bdev): This generic block device abstraction is the glue that connects the storage protocols to the various device drivers and block devices. Also provides flexible APIs for additional customer functionality (RAID, compression, dedup, and so on) in the block layer.
Blobstore: Implements a highly streamlined file-like semantic (non-POSIX*) for SPDK. This can provide high-performance underpinnings for databases, containers, virtual machines (VMs), or other workloads that do not depend on much of a POSIX file system’s feature set, such as user access control.
Storage Protocols
iSCSI target: Implementation of the established specification for block traffic over Ethernet; about twice as efficient as kernel LIO. Current version uses the kernel TCP/IP stack by default.
NVMe-oF target: Implements the new NVMe-oF specification. Though it depends on RDMA hardware, the NVMe-oF target can serve up to 40 Gbps of traffic per CPU core.
vhost-scsi target: A feature for KVM/QEMU that utilizes the SPDK NVMe driver, giving guest VMs lower latency access to the storage media and reducing the overall CPU load for I/O intensive workloads.
SPDK does not fit every storage architecture. Here are a few questions that might help you determine whether SPDK components are a good fit for your architecture.
Is the storage system based on Linux or or FreeBSD*?
SPDK is primarily tested and supported on Linux. The hardware drivers are supported on both FreeBSD and Linux.
Is the hardware platform for the storage system Intel® architecture?
SPDK is designed to take full advantage of Intel® platform characteristics and is tested and tuned for Intel® chips and systems.
Does the performance path of the storage system currently run in user mode?
SPDK is able to improve performance and efficiency by running more of the performance path in user space. By combining applications with SPDK features like the NVMe-oF target, initiator, or Blobstore, the entire data path may be able to run in user space, offering substantial efficiencies.
Can the system architecture incorporate lockless PMDs into its threading model?
Since PMDs continually run on their threads (instead of sleeping or ceding the processor when unused), they have specific thread model requirements.
Does the system currently use the Data Plane Development Kit (DPDK) to handle network packet workloads?
SPDK shares primitives and programming models with DPDK, so customers currently using DPDK will likely find the close integration with SPDK useful. Similarly, if customers are using SPDK, adding DPDK features for network processing may present a significant opportunity.
Does the development team have the expertise to understand and troubleshoot problems themselves?
Intel shall have no support obligations for this reference software. While Intel and the open source community around SPDK will use commercially reasonable efforts to investigate potential errata of unmodified released software, under no circumstances will Intel have any obligation to customers with respect to providing any maintenance or support of the software.
If you’d like to find out more about SPDK, please fill out the contact request form or check out SPDK.io for access to the mailing list, documentation, and blogs.
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. Check with your system manufacturer or retailer or learn more at intel.com.
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark* and MobileMark*, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.
Performance testing configuration:
- 2S Intel® Xeon® processor E5-2699 v3: 18 C, 2.3 GHz (hyper-threading off)
- Note: Single socket was used while performance testing
- 32 GB DDR4 2133 MT/s
- 4 Memory Channel per CPU
- 1x 4GB 2R DIMM per channel
- 4 Memory Channel per CPU
- Ubuntu* (Linux) Server 14.10
- 3.16.0-30-generic kernel
- Intel® Ethernet Controller XL710 for 40GbE
- 8x P3700 NVMe drive for storage
- NVMe configuration
- Total 8 PCIe* Gen 3 x 4 NVMes
- 4 NVMes coming from first x16 slot
(bifurcated to 4 x4s in the BIOS) - Another 4 NVMes coming from second x16 slot (bifurcated to 4 x4s in the BIOS)
- 4 NVMes coming from first x16 slot
- Intel® SSD DC P3700 Series 800 GB
- Firmware: 8DV10102
- Total 8 PCIe* Gen 3 x 4 NVMes
- FIO BenchMark Configuration
- Direct: Yes
- Queue depth
- 4KB Random I/O: 32 outstanding I/O
- 64KB Seq. I/O: 8 outstanding I/O
- Ramp Time: 30 seconds
- Run Time:180 seconds
- Norandommap: 1
- I/O Engine: Libaio
- Numjobs: 1
- BIOS Configuration
- Speed Step: Disabled
- Turbo Boost: Disabled
- CPU Power and Performance Policy: Performance