Introduction
Last year we introduced Intel® Advanced Vector Extensions 512 (Intel® AVX-512) support in Microsoft Visual Studio* 2017 through this VC++ blog post. In this follow-on post, we cover some examples to give you a taste of how Intel AVX-512 provides performance benefits. These examples include calculating the average of an array, matrix vector multiplication, and the calculation of the Mandelbrot set. Microsoft Visual Studio 2017 version 15.5 or later (we recommend the latest) is required to compile these demos, and a computer with an Intel® processor which supports the Intel AVX-512 instruction set is required to run them. See the ARK web site for a list of the processors.
Test System Configuration
Here is the hardware and software configuration we used for compiling and running these examples:
- Processor: Intel® Core™ i9 7980XE CPU @ 2.60GHz, 18 cores/36 threads
- Memory: 64GB
- OS: Windows® 10 Enterprise version 10.0.17134.112
- Power option in Windows: Balanced
- Microsoft Visual Studio 2017 version 15.8.3
Note The performance of any modern processor depends on many factors, including the amount and type of memory and storage, the graphics and display system, the particular processor configuration, and how effectively the program takes advantage of it all. As such, the results we obtained may not exactly match results on other configurations.
Sample Walkthrough: Array Average
Let’s walk through a simple example of how to write some code using Intel AVX-512 intrinsic functions. As the name implies, Intel® Advanced Vector Extensions (Intel® AVX) and Intel AVX-512 instructions are designed to enhance calculations using computational vectors, which contain several elements of the same data type. We will use these Intel® AVX and Intel AVX-512 intrinsic functions to speed up the calculation of the average of an array of floating-point numbers.
First we start with a function that calculates the average of array “a” using scalar (non-vector) operations:
static const int length = 1024*8;
static float a[length];
float scalarAverage() {
float sum = 0.0;
for (uint32_t j = 0; j < _countof(a); ++j) {
sum += a[j];
}
return sum / _countof(a);
}
This routine sums all the elements of the array and then divides it by the number of elements. To “vectorize” this calculation we break the array into groups of elements or “vectors” that we can calculate simultaneously. For Intel AVX we can fit 8 float elements in each vector, as each float is 32 bits and the vector is 256 bits, so 256/32 = 8 float elements. We sum all the groups into a vector of partial sums, and then add the elements of that vector to get the final sum. For simplicity, we assume that the number of elements is a multiple of 8 or 16 for Intel AVX and Intel AVX-512, respectively, in the sample code shown below. If the number of total elements doesn’t cleanly fit into these vectors, you would have to write a special case to handle the remainder.
Here is the new function:
float avxAverage () {
__m256 sumx8 = _mm256_setzero_ps();
for (uint32_t j = 0; j < _countof(a); j = j + 8) {
sumx8 = _mm256_add_ps(sumx8, _mm256_loadu_ps(&(a[j])));
}
float sum = sumx8.m256_f32[0] + sumx8.m256_f32[1] +
sumx8.m256_f32[2] + sumx8.m256_f32[3] +
sumx8.m256_f32[4] + sumx8.m256_f32[5] +
sumx8.m256_f32[6] + sumx8.m256_f32[7];
return sum / _countof(a);
}
Here, _mm256_setzero_ps creates a vector with eight zero values, which is assigned to sumx8. Then, for each set of eight contiguous elements from the array, _mm256_loadu_ps loads them into a 256-bit vector which _mm256_add_ps adds to the corresponding elements in sumx8, making sumx8 a vector of eight subtotals. Finally, these subtotals are added to create the total number.
Compared to the scalar implementation, this single instruction, multiple data (SIMD) implementation executes fewer add instructions. For an array with n elements, a scalar implementation will execute n add instructions, but using Intel AVX only (n/8 + 7) add instructions are needed. As a result, Intel AVX can potentially be up to 8X faster than the scalar implementation.
Similarly, here is the code for the Intel AVX-512 version:
float avx512AverageKernel() {
__m512 sumx16 = _mm512_setzero_ps();
for (uint32_t j = 0; j < _countof(a); j = j + 16) {
sumx16 = _mm512_add_ps(sumx16, _mm512_loadu_ps(&(a[j])));
}
float sum = _mm512_reduce_add_ps (sumx16);
return sum / _countof(a);
}
As you can see, this version is almost identical to the previous function except for the way the final sum is calculated. With 16 elements in the vector, we would need 16 array references and 15 additions to calculate the final sum if we were to do it the same way as the Intel AVX version. Fortunately, Intel AVX-512 provides the _mm512_reduce_add_ps intrinsic function to generate the same result, which makes the code much easier to read. This function adds the first eight elements to the rest, then adds the first four of that vector to the rest, then two and finally sums those to get the total with just four addition instructions. Using Intel AVX-512 to find the average of an array with n elements requires the execution of (n/16+4) addition instructions which is about half of what was needed for Intel AVX when n is large. As a result, Intel AVX-512 can potentially be up to 2x faster than Intel AVX.
For this example, we used only a few of the most basic Intel AVX-512 intrinsic functions, but there are hundreds of vector intrinsic functions available which perform various operations on a selection of different data types in 128-bit, 256-bit, and 512-bit vectors with options such as masking and rounding. These functions may use instructions from various Intel instruction set extensions, including Intel AVX-512. For example, the intrinsic function _mm512_add_ps() is implemented using the Intel AVX-512 vaddps instruction. You can use the Intel Software Developer Manuals to learn more about Intel AVX-512 instructions, and the Intel Intrinsics Guide to find particular intrinsic functions. Click on a function entry in the Intrinsics Guide and it will expand to show more details, such as Synopsis, Description, and Operation.
These functions are declared using the immintrin.h header. Microsoft* also offers the intrin.h header, which declares almost all Microsoft Visual C++* (MSVC) intrinsic functions, including the ones from immintrin.h. You can include either of these headers in your source file.
Sample Walkthrough: Matrix Vector Multiplication
Mathematical vector and matrix arithmetic involves lots of multiplications and additions. For example, here is a simple multiplication of a matrix and a vector:

A computer can do this simple calculation almost instantly but multiplying very large vectors and matrices can take hundreds or thousands of multiplications and additions like this. Let’s see how we can “vectorize” those computations to make them faster. Let’s start with a scalar function which multiplies matrix t1 with vector t2:
static float *out;
static const int row = 16;
static const int col = 4096;
static float *scalarMultiply() {
for (uint64_t i = 0; i < row; i++) {
float sum = 0;
for (uint64_t j = 0; j < col; j++)
sum = sum + t1[i*col + j] * t2[j];
out[i] = sum;
}
return out;
}
As with the previous example, we “vectorize” this calculation by breaking each row into vectors. For Intel AVX-512, because each float is 32 bits and a vector is 512 bits, a vector can have 512/32 = 16 float elements. Note that this is a computational vector, which is different from the mathematical vector that is being multiplied. For each row in the matrix we load 16 columns as well as the corresponding 16 elements from the vector, multiply them together, and add the products to a 16-element accumulator. When the row is complete, we can sum the accumulator elements to get an element of the result.
Note that we can do this with Intel AVX or Intel® Streaming SIMD Extensions (Intel® SSE) as well, and the maximum vector sizes with those extensions are 8 (256/32) and 4 (128/32) elements respectively.
A version of the multiply routine using Intel AVX-512 intrinsic functions is shown here:
static float *outx16;
static float *avx512Multiply() {
for (uint64_t i = 0; i < row; i++) {
__m512 sumx16 = _mm512_set1_ps(0.0);
for (uint64_t j = 0; j < col; j += 16) {
__m512 a = _mm512_loadu_ps(&(t1[i*col + j]));
__m512 b = _mm512_loadu_ps(&(t2[j]));
sumx16 = _mm512_fmadd_ps(a, b, sumx16);
}
outx16[i] = _mm512_reduce_add_ps(sum16);
}
return outx16;
}
You can see that many of the scalar expressions have been replaced by intrinsic function calls that perform the same operation on a vector.
We replace the initialization of sum to zero with a call of the _mm512_set1_ps() function that creates a vector with 16 zero elements and assign that to sumx16. Inside the inner loop we load 16 elements of t1 and t2 into vector variables a and b respectively using _mm512_loadu_ps(). The _mm512_fmadd_ps() function adds the product of each element in a and b to the corresponding elements in sumx16.
At the end of the inner loop we have 16 partial sums in sumx16 rather than a single sum. To calculate the final result we must add these 16 elements together using the _mm512_reduce_add_ps() function that we used in the array average example.
Floating-Point vs. Real Numbers
At this point we should note that this vectorized version does not calculate exactly the same thing as the scalar version. If we were doing all of this computation using mathematical real numbers it wouldn’t matter what order we add the partial products, but that isn’t true of floating-point values. When floating-point values are added, the precise result may not be representable as a floating-point value. In that case the result must be rounded to one of the two closest values that can be represented. The difference between the precise result and the representable result is the rounding error.
When computing the sum of products like this the calculated result will differ from the precise result by the sum of all the rounding errors. Because the vectorized matrix multiply adds the partial products in a different order from the scalar version the rounding errors for each addition can also be different. Furthermore, the _mm512_fmadd_ps() function does not round the partial products before adding them to the partial sums, so only the addition adds a rounding error. If the rounding errors differ between the scalar and vectorized computations the result may also differ. However, this doesn’t mean that either version is wrong. It just shows the peculiarities of floating-point computation.
Mandelbrot Set
The Mandelbrot set is the set of all complex numbers z for which the sequence defined by the iteration
z(0) = z, z(n+1) = z(n)*z(n) + z, n=0,1,2, ...
remains bounded. This means that there is a number B such that the absolute value of all iterates z(n) never gets larger than B. The calculation of the Mandelbrot set is often used to make colorful images of the points that are not in the set where each color indicates how many terms are needed to exceed the bound. It is widely used as a sample to demonstrate vector computation performance. The kernel code of calculating the Mandelbrot set where B is 2.0 is available.
static int mandel(float c_re, float c_im, int count) {
float z_re = c_re, z_im = c_im;
int i;
for (i = 0; i < count; ++i) {
if (z_re * z_re + z_im * z_im > 4.f)
break;
float new_re = z_re*z_re - z_im*z_im;
float new_im = 2.f * z_re * z_im;
z_re = c_re + new_re;
z_im = c_im + new_im;
}
return i;
}
Of course, it is impossible to evaluate every term of an infinite series, so this function evaluates no more than the number of terms specified by count, and we assume that if the series hasn’t diverged by that point, it isn’t going to. The value returned indicates how many terms did not diverge, and it is typically used to select a color for that point. If the function returns count the point is assumed to be in the Mandelbrot set.
We can vectorize this by replacing each scalar operation with a vector equivalent similar to the way we vectorized matrix vector multiplication. But a complication arises with the following source line: “if (z_re * z_re + z_im * z_im > 4.0f) break;”. How do you vectorize a conditional break?
In this instance we know that once the series exceeds the bound all later terms will also exceed it, so we can unconditionally continue calculating all elements until all of them have exceeded the bound or we have reached the iteration limit. We can handle the condition by using a vector comparison to mask the elements that have exceeded the bound and use that to update the results for the remaining elements. Here is the code for a version using Intel® Advanced Vector Extensions 2 (Intel® AVX2) functions.
/* AVX2 Implementation */
__m256i avx2Mandel (__m256 c_re8, __m256 c_im8, uint32_t max_iterations) {
__m256 z_re8 = c_re8;
__m256 z_im8 = c_im8;
__m256 four8 = _mm256_set1_ps(4.0f);
__m256 two8 = _mm256_set1_ps(2.0f);
__m256i result = _mm256_set1_epi32(0);
__m256i one8 = _mm256_set1_epi32(1);
for (auto i = 0; i < max_iterations; i++) {
__m256 z_im8sq = _mm256_mul_ps(z_im8, z_im8);
__m256 z_re8sq = _mm256_mul_ps(z_re8, z_re8);
__m256 new_im8 = _mm256_mul_ps(z_re8, z_im8);
__m256 z_abs8sq = _mm256_add_ps(z_re8sq, z_im8sq);
__m256 new_re8 = _mm256_sub_ps(z_re8sq, z_im8sq);
__m256 mi8 = _mm256_cmp_ps(z_abs8sq, four8, _CMP_LT_OQ);
z_im8 = _mm256_fmadd_ps(two8, new_im8, c_im8);
z_re8 = _mm256_add_ps(new_re8, c_re8);
int mask = _mm256_movemask_ps(mi8);
__m256i masked1 = _mm256_and_si256(_mm256_castps_si256(mi8), one8);
if (0 == mask)
break;
result = _mm256_add_epi32(result, masked1);
}
return result;
};
The scalar function returns a value that represents how many iterations were calculated before the result diverged, so a vector function must return a vector with those same values. We compute that by first generating a vector mi8 that indicates which elements have not exceeded the bound. Each element of this vector is either all zero bits (if the test condition _CMP_LT_OQ is not true) or all one bits (if it is true). If that vector is all zero, then everything has diverged, and we can break out of the loop. Otherwise the vector value is reinterpreted as a vector of 32-bit integer values by _mm256_castps_si256, and then masked with a vector of 32-bit ones. That leaves us with a one value for every element that has not diverged and zeros for those that have. All that is left is to add that vector to the vector accumulator result.
The Intel AVX-512 version of this function is similar, with one significant difference. The _mm256_cmp_ps function returns a vector value of type __m256. You might expect to use a _mm512_cmp_ps function that returns a vector of type __m512, but that function does not exist. Instead we use the _mm512_cmp_ps_mask function that returns a value of type __mmask16. This is a 16-bit value, where each bit represents one element of the vector. These values are held in a separate set of eight registers that are used for vectorized conditional execution. Where the Intel AVX2 function had to calculate the values to be added to result explicitly, Intel AVX-512 allows the mask to be applied directly to the addition with the _mm512_mask_add_epi32 function.
/* AVX512 Implementation */
__m512i avx512Mandel(__m512 c_re16, __m512 c_im16, uint32_t max_iterations) {
__m512 z_re16 = c_re16;
__m512 z_im16 = c_im16;
__m512 four16 = _mm512_set1_ps(4.0f);
__m512 two16 = _mm512_set1_ps(2.0f);
__m512i one16 = _mm512_set1_epi32(1);
__m512i result = _mm512_setzero_si512();
for (auto i = 0; i < max_iterations; i++) {
__m512 z_im16sq = _mm512_mul_ps(z_im16, z_im16);
__m512 z_re16sq = _mm512_mul_ps(z_re16, z_re16);
__m512 new_im16 = _mm512_mul_ps(z_re16, z_im16);
__m512 z_abs16sq = _mm512_add_ps(z_re16sq, z_im16sq);
__m512 new_re16 = _mm512_sub_ps(z_re16sq, z_im16sq);
__mmask16 mask = _mm512_cmp_ps_mask(z_abs16sq, four16, _CMP_LT_OQ);
z_im16 = _mm512_fmadd_ps(two16, new_im16, c_im16);
z_re16 = _mm512_add_ps(new_re16, c_re16);
if (0 == mask)
break;
result = _mm512_mask_add_epi32(result, mask, result, one16);
}
return result;
};
Each of the vectorized Mandelbrot calculations returns a vector instead of a scalar, and the value of each element is the same value that would have been returned by the original scalar function. You may have noticed that the returned value has a different type from the real and imaginary argument vectors. The arguments to the scalar function are type float, and the function returns an unsigned integer. The arguments to the vectorized functions are vector versions of float, and the return value is a vector that can hold 32-bit unsigned integers. If you need to vectorize a function that uses type double, there are vector types for holding elements of that type as well: __m128d, __m256d and __m512d. You may be wondering if there are vector types for other integer types such as signed char and unsigned short. There aren’t. Vectors of type __m128i, __m256i and __m512i are used for all integer elements regardless of size or signedness.
You can also convert or cast (reinterpret) vectors that hold elements of one type into a vector with elements of a different type. In the mandelx8 function the _mm256_castps_si256 function is used to reinterpret the __m256 result of the comparison function as a __m256i integer element mask for updating the result vector.
Performance of Intel® AVX-512
We measured the run time of the Mandelbrot, matrix vector multiplication, and array average kernel functions with Intel AVX, Intel AVX2 and Intel® AVX-512 intrinsic functions to compare the performance. The source code is compiled with /O2. On our test platform, Mandelbrot with Intel AVX-512 is 1.77x1 faster than the Intel AVX2 version sample code. Array average (source code) is 1.91x1 faster and matrix vector multiplication (source code) is 1.80x1 faster compared to their Intel AVX2 versions.
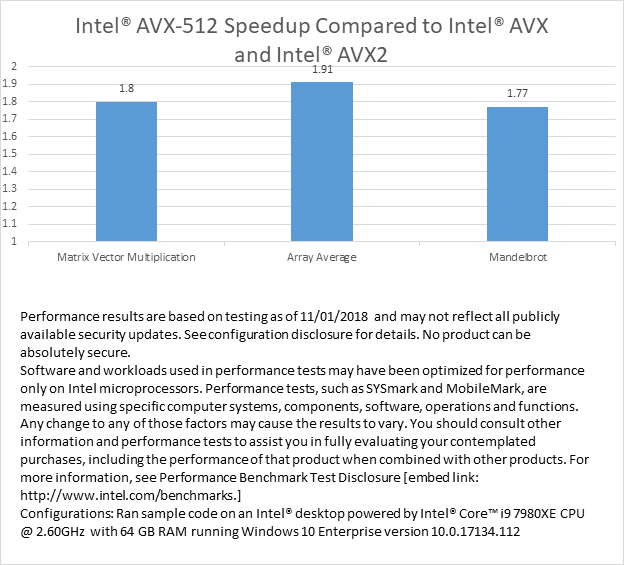
We previously stated that the performance achievable by Intel AVX-512 should approximately double that of Intel AVX2. We see that we don’t quite reach that number, and there are a few reasons why the speedup might not reach the expected value. One is that only the innermost loop of the calculation is sped up by the larger vector instructions, but the total execution time includes time spent executing outer loops and other overhead that did not speed up. Another potential reason is because the bandwidth of the memory system must be shared between all cores doing calculations, and this is a finite resource. When most of that bandwidth is being used, the processor can’t compute faster than the data becomes available.
Conclusions
We have presented several examples of how to vectorize array average and matrix vector multiplication as well as shown code for calculating the Mandelbrot set using Intel AVX2 and Intel AVX-512 functions. This code is a more realistic example of how to use Intel AVX-512 than the sample code from our prior post. From data collected on our test platform, the Intel AVX-512 code shows performance improvements between 77% and 91% when compared to Intel AVX2.
Intel AVX-512 fully utilizes Intel® hardware capabilities to improve performance by doubling the data that can be processed with a single instruction compared to Intel AVX2. This capability can be used in artificial intelligence, deep learning, scientific simulations, financial analytics, 3D modeling, image/audio/video processing, and data compression. Use Intel AVX-512 and unlock your application’s full potential.
(1) As provided in this document § Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. § Configurations: Ran sample code on an Intel® desktop powered by Intel® Core™ i9 7980XE CPU @ 2.60GHz with 64 GB RAM running Windows 10 Enterprise version 10.0.17134.112 § For more information go to https://edc.intel.com/content/www/us/en/products/performance/benchmarks/benchmarks-and-measurements/