Introduction
This paper discusses the new features and enhancements available in the second generation Intel® Xeon® processor Scalable family and how developers can take advantage of them. The latest processor shares all the same features as the previous generation of Intel Xeon processor Scalable family as well as providing additional new technologies, including Intel® AVX512-Deep Learning Boost (Intel® AVX512-DL Boost) to help with AI workloads, Intel® Optane™ DC persistent memory, and Intel® Speed Select Technology.
Table 1. The Next-Generation Intel® Xeon® Processor Scalable Family Microarchitecture Overview
Note New capabilities and changes relative to the previous generation in Italic.
| CPU | Second Generation Intel Xeon processor Scalable family: Up to 28 cores with Intel® Hyper-Threading Technology at 70 W to 205 W |
|---|---|
| New Capabilities | Processor frequency increase |
| Intel® AVX512-Deep Learning Boost (Intel® AVX512-DL Boost) | |
| Intel® Speed Select Technology on select SKUs | |
| Socket | Socket P |
| Scalability | 2S, 4S, & glueless 8S (>8S via xNC support) |
| Memory | 6 channels DDR4 R/LRDIMM per CPU/ 12 DIMMs per socket, up to 2666 MT/s 2DPC, up to 2933 MT/s 1DPC; 16 GB DDR4 based DIMMs support on select SKUs |
| Intel® Optane™ DC persistent memory (up to 512 GB / module) on select SKUs | |
| UPI | Up to 3 links per CPU |
| Ultra Path Interconnect | x20, speed: 9.6 and 10.4 GTS |
| PCIe | PCIe Gen 3: 48 lanes per CPU (bifurcation support: x16, x8, x4) |
| Host Fabric | Discrete Cornelis Networks adapter (100 GB/s) |
| [Integrated Fabric SKUs available on previous Intel Xeon processor Scalable family only] | |
| Intel® C620 Series Chipsets | Intel® QuickAssist Technology (Intel® QAT) Enhanced Serial Peripheral Interface (eSPI) Integrated Intel® Ethernet Connection |
| up to 4x10 GB/1 GB ports, Up to 20 ports PCIe* 3.0 (8 GT/s) | |
| Up to 14 SATA 3, up to 14 USB 2.0, up to 10 USB 3.0 |
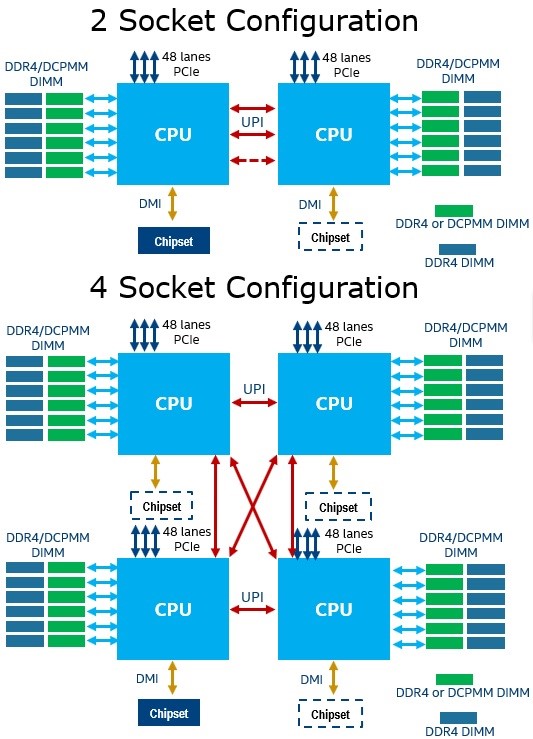
Figure 1. Diagram of platform configurations
Intel® Optane™ DC Persistent Memory Technology
Intel Optane DC persistent memory modules are a new form of large capacity memory that can function in either a volatile or non-volatile state and provides a new tier positioned between DRAM and storage. Traditional memory in computer architecture is volatile. The content of volatile memory is only able to exist so long as the system supplies power. If there is a power loss, the data is immediately lost. Persistent memory maintains the integrity of the information stored in it, even when power has been lost or cycled on the system. The persistent memory is byte addressable, cache coherent, and provides software with direct access to persistence without paging.
Hardware Design
Intel Optane DC persistent memory module-based DIMMs insert into a standard DDR4 unbuffered/registered/load reduced connector on Intel® architecture (IA) server platforms. While being compliant with DDR4 hardware specifications, it is not compatible with a native DDR4 interface protocol; instead, communication uses a unique encoded transactional protocol referred to as DDR-T.
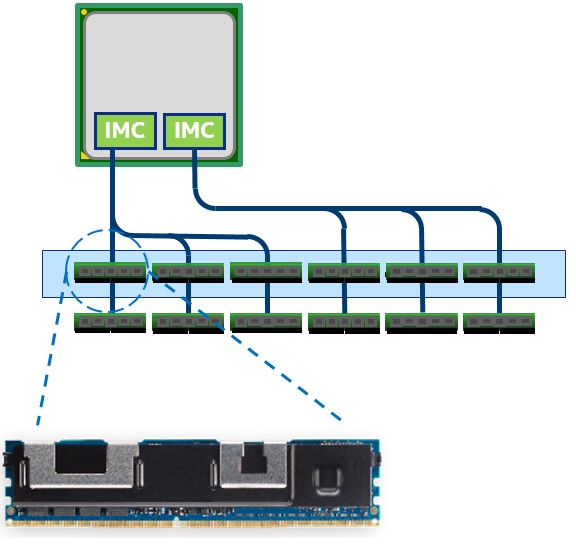
Figure 2. Intel® Optane™ DC persistent memory module-based DIMM, memory controller, and memory channels
The processor package has two memory controllers, each with three memory channels and two DIMMs per channel. All memory slots can be fully populated with standard DDR4 memory or half the slots (shown in blue in Figure 2) with persistent memory modules. Additional benefits can be obtained from populating the system with both persistent memory modules and DDR4 memory. The DIMM capacities available with the persistent memory technology are 128 GB, 256 GB, and 512 GB with up to 3 TB per processor socket. Processor models that support a 3 TB scheme can be found with an “L” at the end of the model number. This denotes support for up to 4.5 TB per socket of memory which includes up to 3 TB of persistent memory plus additional standard memory. The Intel Optane DC memory-based DIMMs operate at speeds of up to 2666 MT/sec.
Hardware and Software Requirements
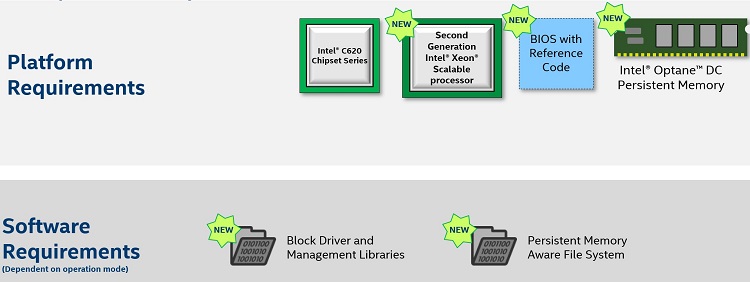
Figure 3. Intel® Optane™ DC persistent memory modules technology requirements
To take advantage of Intel Optane DC persistent memory modules requires a BIOS, CPU, and platform that supports this new technology. Also required is an operating system that provides supporting block driver and management libraries, and a persistent memory-aware file system (PMFS) to take full advantage of the Intel Optane DC persistent memory modules.
To configure the Intel Optane DC persistent memory modules as either volatile, persistent, or a combination of the two, provision this through the BIOS or the operating system. When the system boots to the operating system level, the OS will then load the appropriate drivers to take advantage of the chosen configuration. From a data center perspective, the provisioning of the Intel Optane DC persistent memory modules can also be done remotely if desired through the Base Management Controller (BMC).
Intel Optane DC Memory Modes of Operation
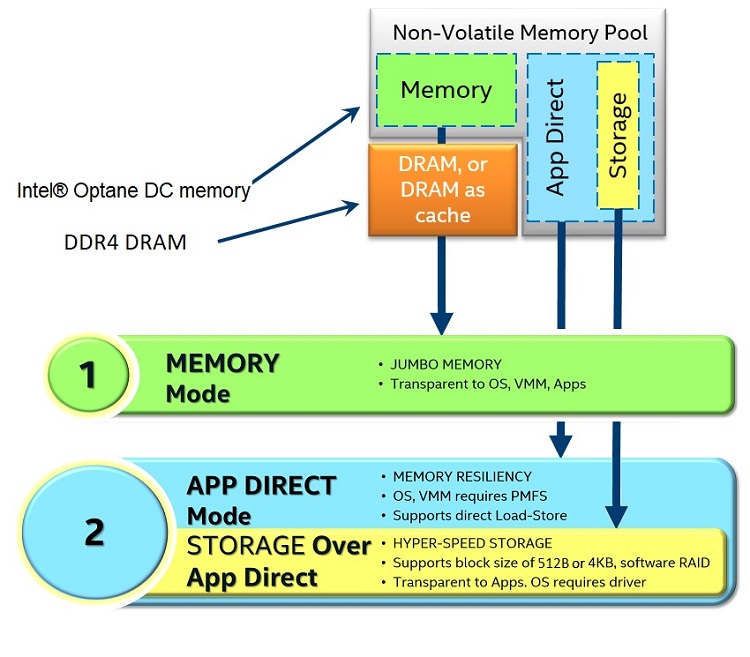
Figure 4. Intel Optane DC memory modes of operation
The three modes of operation for Intel Optane DC persistent memory modules are Memory mode, Application Direct (App Direct) mode and Storage over App Direct mode. In Memory mode, the Intel Optane DC persistent memory module is transparent to the operating system, applications, or virtual machine monitors (VMMs) appearing as traditional volatile memory. The DRAM memory on the system automatically shifts its role to become cache for the memory system. When the DRAM memory is operating as a memory cache, it will not be included as part of the total volatile memory pool available to the operating system.
App Direct mode allows the Intel Optane DC persistent memory modules to operate as persistent memory and to be explicitly exposed to applications. In this mode of operation, the operating system or VMM requires a persistent memory file system. App Direct enables applications to directly apply, load, and store operations into the persistent memory in 64 byte cache line sizes. The DRAM memory will appear as a separate pool of volatile memory on the system.
Applications will need to decide what data to put into the volatile DRAM memory and what data to place within the Intel Optane DC persistent memory modules creating optimization considerations for the software developer. Workloads that cycle data through the DRAM cache in memory mode too quickly can cause a high number of cache misses. In Memory mode the DRAM cache will not be addressable and while in App Direct mode the DRAM is exposed to the developer. This allows developers to optimize the performance of their application by placing frequently used code into the faster DRAM memory, and data that needs to be faster than storage but not as low latency as DRAM into persistent memory.
The last mode of operation is Storage over App Direct, which utilizes the OS native non-volatile dual in-line memory module (NVDIMM) driver to provide the ability to work with existing applications that talk to block devices. The driver can communicate in 512 bytes and 4KB block sizes, allowing an application to use the persistent memory as a storage device.
From a programming perspective, App Direct mode can access a persistent memory region in two different ways: through a more traditional route using a standard file API, and through memory mapping a file. This allows for direct load and store operations, in effect providing access in the size of a 64B cache line.

Figure 5. Programming to the persistent memory region
Software Architecture
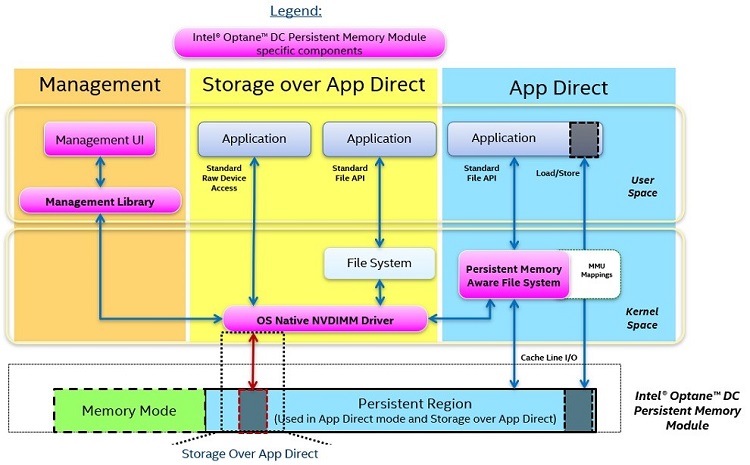
Figure 6. Software Architecture Diagram
Figure 6 represents a system with a pool of Intel Optane DC persistent memory modules, which has a portion of the memory provisioned as volatile memory and a portion provisioned as persistent memory. The figure focuses on how the App Direct mode and Storage over App Direct mode work from a software perspective with the persistent memory region.
The operating system utilizes an OS-native NVDIMM driver or set of drivers to interface between the different modes and the Intel Optane DC persistent memory modules. Shown in the orange box of Figure 6, the driver allows manageability software to interface with the memory, providing the ability to provision the memory, check on the health of the memory, check on various sensory data associated with the memory, etc. This can be accomplished by a command line interface or software management APIs.
The App Direct mode has two ways to interact with the persistent memory region shown in the blue box in Figure 6. The first is through a persistent memory aware file system that has been modified to understand what persistent memory is. The persistent memory aware file system works with the OS Native NVDIMM driver to obtain the address range for the persistent memory. Once this has been accomplished, the persistent memory aware file system can communicate with both normal file system operations like open, read, and write, as well as using direct load and store operations without having to go through the block stack. The persistent memory aware file systems include NTFS on Windows* and EXT4 and XFS on Linux*.
The second way that App Direct mode can interact with the persistent memory is through a memory mapped file. Memory mapping has been around for a long time and is supported in virtually every operating system today. There is typically a performance impact of memory mapping with standard DRAM. This happens because to access the memory in a byte addressable way, the file must be paged into the memory space, which causes context switching. The persistent memory is a different story, as there is no paging that occurs with a memory mapped file and instead the application gets direct access. An application that has memory mapped a file will have the shortest code path possible for load and store operations while avoiding context switches and interrupts normally associated with memory mapping. This direct method of access is also known as DAX. As with memory mapping on DRAM, the stores are not persistent until they’re flushed using APIs like msync() in Linux and FlushFileBuffers() in Windows. Flushing the CPU caches can also be done directly using the CFLUSHOPT and CLWB instructions, which are covered later in this article.
In the Storage over App Direct Mode shown in the yellow box of Figure 6, the OS Native NVDIMM driver reads and writes in block sizes to the persistent memory region. This makes it very easy for existing block storage applications or file systems to directly interface with the persistent memory region in a transparent way where it will just appear as a storage device.
The Persistence Domain
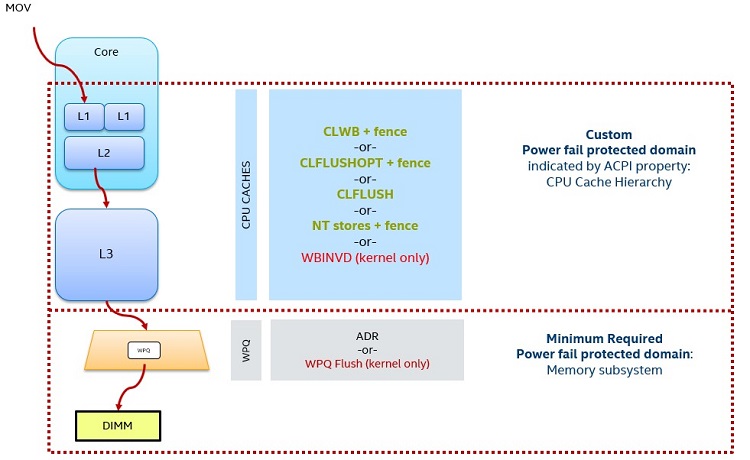
Figure 7. Persistent Domain Overview
The persistence domain represents the condition when a store instruction is considered persistent. Not every store can be made persistent right away because the processor caches provide a performance benefit — to make the cache write through would impact performance. The large size of the processor caches makes it difficult to do an automatic flush if the system went down. This is because of the amount of extra power required from a backup source of energy to clear those large processor caches.
This means that applications are required to perform processor cache flushing. They do this through the list of green commands in figure 7. In the event that stores make it out of the processor cache and into the chipset’s write pending queue (WPQ), consider what happens if the system goes down: the platform has enough power to ensure that the WPQ is flushed on fail and the store makes it into persistent memory. A store that can make it into the bottom red box in figure 7, which is identified as the persistent domain, is guaranteed to make it the persistent memory. The Persistent Memory Development Kit (see section below) provides APIs that follow these rules.
Intel Optane DC Memory Regions and Usage Namespaces
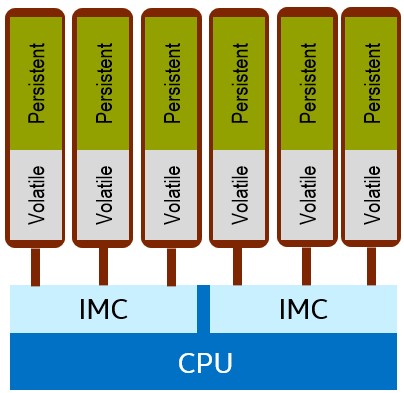
Figure 8. Memory Regions
Intel Optane DC persistent memory modules allow developers to set up regions that can be volatile, persistent, or a combination of the two. Within the persistent region, it’s possible to create a further division between App Direct (load/store sized data) and Storage over App Direct (block sized data). The regions created on a socket must be identical across the DIMMs, as seen in Figure 8, where the Intel Optane DC persistent memory modules have both volatile and persistent regions. To help configure and manage the regions on the DIMMs in either Linux or UEFI use Ipmctl.
When planning how to carve up portions of a persistent region, they can be broken into logical devices called namespaces. Namespaces expose capacity from a persistent interleaved or non-interleaved set to an operating system. The namespaces come in two types, either block or DAX capable persistent memory. Also, to help configure and manage namespaces in Linux, use ndctl.
Persistent Memory Libraries
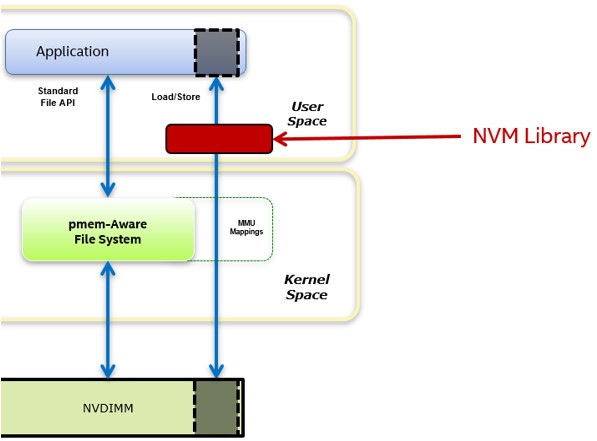
Figure 9. Non-volatile memory (NVM) libraries
The Persistent Memory Development Kit (PMDK) builds on open persistent memory programming model to expedite development. The libraries are open source and include C and C++ language libraries for malloc/free-like programming, transaction support, hardware independence, and high availability. Although it is not a requirement, this approach helps facilitate the development of persistent memory applications.
One important aspect for programmers: these libraries take the complexity out of dealing with transactional algorithms to ensure that memory data structures remain intact and consistent in the event of a system or application crash. There are libraries to support use cases that need persistent memory to act as if it is volatile.
CLWB Instruction
When storing changes in a memory map to disk, those changes are not guaranteed to occur until performing a flush operation like msync on Linux or FlushFileBuffers on Windows. When a memory map is stored within persistent memory, then a CPU cache flush operation is needed. On Intel Optane DC persistent memory modules this is accomplished through the CLWB instruction.
Example Code
MOV X1, 10 - Store 10 to X1
MOV X2, 20 - Store 20 to X2
MOV R1, X1 - Stores to X1 and X2 are globally visible, but still potentially volatile
CLWB X1 - X1 and X2 flushed from caches
CLWB X2
SFENCE - Ensures stores are ordered ahead of any following code
Intel Optane DC Memory Use Cases
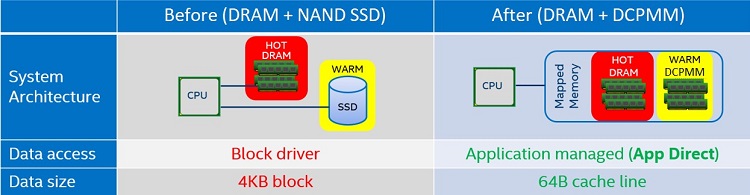
Figure 10. In-memory database comparison
Databases that reside in-memory will always benefit from increased memory capacity, and this is one obvious benefit of Intel Optane DC persistent memory modules for this particular use case. Another benefit occurs when an in-memory database needs to be shut down – for example, to apply a security patch to the operating system. After the patch is applied and the system is brought back up, the database would need to be read back into memory. That could take some time with an extensive database, say, in the terabyte range. Intel Optane DC persistent memory modules in this scenario can eliminate the need for paging the data between the DRAM and the SSD due to the persistence of the memory.
A less obvious benefit of the technology is that it creates an opportunity to access the database with smaller data sizes. Normally using a block driver forces developers to access the data in 4KB blocks. The App Direct mode allows for byte addressability, providing a new option to read and write 64-byte cache lines into the database or to flush a portion of the block to disk rather than the entire 4KB. The database software can also choose whether the data will be stored in the DRAM or on the Intel Optane DC persistent memory modules, depending on the priority of the data per the service level agreement requirements.

Figure 11. Memcached comparison
As with the previous use case of an in-memory database, there are similar benefits with memcached use cases. The larger capacity of the Intel Optane DC persistent memory modules allows memory capacity that sits closer to the processor than an SSD would, and DRAM provides a cache for system memory. Consider an additional aspect: from a cost of ownership perspective, Intel Optane DC persistent memory modules allow for fewer nodes to provide the same number of clients due to the memory density per socket.

Figure 12. Multi-tenancy and memory scaling comparison
For multi-tenancy VM use cases, Intel Optane DC persistent memory modules provide a larger memory capacity per socket than is typically possible with DRAM, enabling support for more virtual machine (VM) instances or providing larger memory per VM and eliminating the need for paging data between the DRAM and the SSD.

Figure 13. Direct-attached storage or HPC Journaling
Storage over App Direct provides advantages for different use cases. For typical storage use cases, the solution will be faster due to the direct-attach aspect of the memory as compared to a storage array. If the storage data needs to be duplicated due to concerns over a single point of failure, one option is remote direct memory access (RDMA), which can be used to access persistent memory on a remote node directly. The libraries found in the PMDK can help with this. It should be noted that the PMDK libraries will work for anything built on top of RDMA, including message passing interface (MPI) applications that need to write to persistent memory remotely.
Persistent memory also improves availability for high performance computing (HPC) data and can act as a reliable write cache for journaling in blocks or cache lines on an HPC fat node. In HPC use cases during a long calculation, it can be desirable to take a snapshot of the data to not lose the calculations if the machine crashes. This is typically known as journaling or a checkpoint. When a snapshot is taken, the calculation must be paused before continuing. If the snapshot is done over the network to storage, then the pause can be very long, due to the size of the data. But if the snapshot is taken to local persistent memory, it will be much faster. The checkpoint can even be migrated off from the Intel Optane DC persistent memory modules to the remote storage location while the calculation continues to run.
Intel Optane DC Memory Reliability, Availability, and Serviceability (RAS) Features
The second generation Intel Xeon processor Scalable family has a specific set of Reliability, Availability, and Serviceability (RAS) features for Intel Optane DC persistent memory modules. The RAS features are designed to help maintain the integrity of the data within the Intel Optane DC persistent memory modules and at the DDR-T protocol level. They attempt to identify errors and protection against corruption within the memory space. It is worth noting that any error found with the Intel Optane DC persistent memory modules that might be identified by the RAS features will be reported back to an application in the same way that would occur with standard memory. For information on the set of RAS features associated with the DRAM see Intel® Xeon® Processor Scalable Family Technical Overview.
Highlights of the available RAS features:
- Patrol Scrubbing - Autonomously looks for correctable and uncorrectable error-correcting code (ECC) errors. Both the DDR4 and non-volatile DDR DIMM memory have their own scrubber, which operates asynchronously of each other.
- Error Injection - Several error injection mechanisms that can be used to test the software error handling at the OS kernel or application levels.
- Viral Error containment - Viral is a platform-wide containment mechanism for errors that cannot be contained through the data poisoning mechanism.
- Data Poisoning - When the NVDIMM encounters an uncorrectable error, it will return POISON status, and it will work to contain the corrupt data.
Intel Optane DC Memory Security Features
A key feature is that Intel Optane DC persistent memory modules help to protect the data residing in memory from various forms of attack such as memory scraping. One way this is accomplished is that the memory controller firmware is fully authenticated at boot by a read only memory based root of trust to help provide a secure boot. The other way is that a level of XTS-AES 256 encryption protects all the data in memory for both persistent and volatile memory regions.
The encryption for persistent memory interacts with a passphrase that is supplied by the customer at the BIOS level. The passphrase will need to be managed to maintain the integrity of the persistent data within the memory through each boot cycle. Cryptographic erasure of the persistent memory is also provided via both in and out of band options.
The volatile memory region encryption is automatically managed by the system and requires no effort on the part of the end user. The encryption key for the volatile memory is automatically cleared on system shutdown or a loss of power and is regenerated on every boot cycle of the system. This is even more secure than standard DRAM, which can occasionally retain some of its data after a loss of power.
Intel Optane DC Memory and DIMM Failure
In the event of a failed DIMM, the serviceability is no different from standard DRAM, bringing the system down and replacing the unit. If utilizing the storage mode via App Direct with software RAID such as RAID 5/1, the data will be reconstructed on the new DIMM. If storage mode via App Direct is being utilized without RAID, then the data must be backed up before replacing the DIMM. Once the system is brought back up with the new DIMM, the data will need to be restored from the backup copy. If utilizing memory mode, the data will be lost.
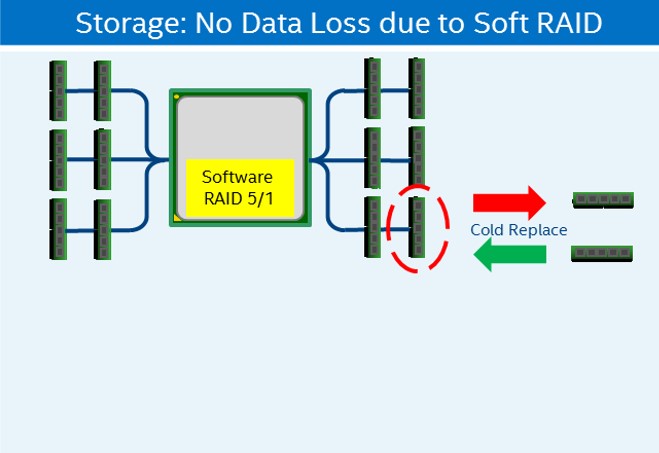
Figure 14. Software Raid and Intel Optane DC persistent memory modules
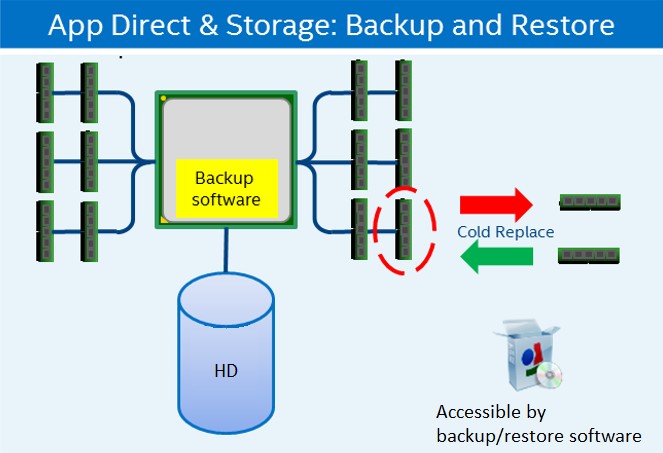
Figure 15. Backup and Restore with Intel Optane DC persistent memory modules
Intel Optane DC Memory and Platform Failure
In the event of a failure on the platform, the data will be preserved for persistent memory regions without requiring saving and restoring the data manually. However, data within volatile memory will be lost. The DIMMs will need to be moved over to an identical replacement motherboard and populated in the exact same order on the DIMM slots from the original motherboard. Due to the encrypted security feature of the persistent memory space, end users must also supply the correct passphrase to the BIOS to access the persistent memory region on the new system.
Intel Optane DC Memory Policy Provisioning
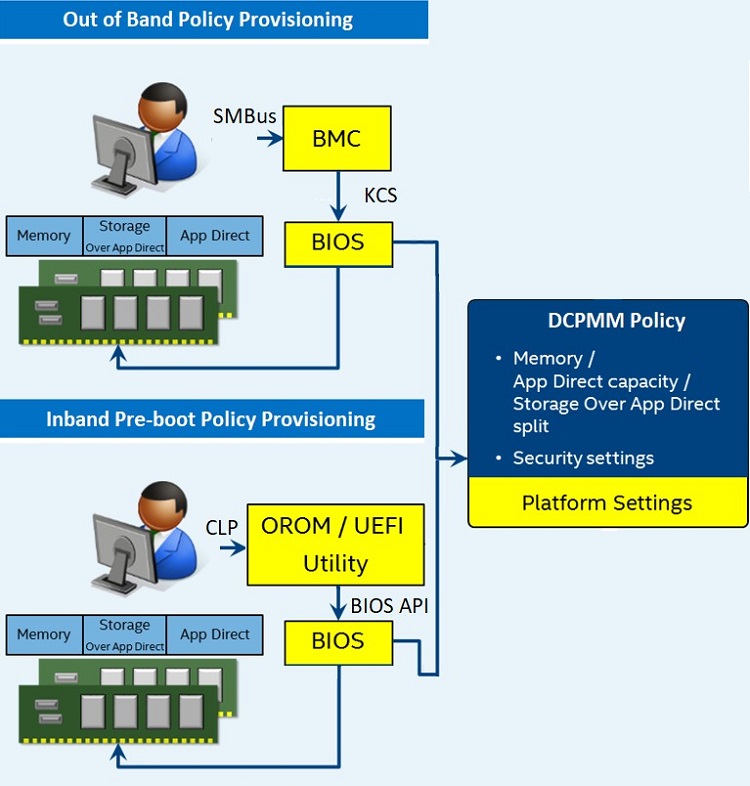
Figure 16. Overview of memory provisioning
There are scenarios for cloud workloads and data center environments where the ability to provision the Intel Optane DC persistent memory modules via policies is of benefit. Intel Optane DC persistent memory modules can simultaneously support memory and App Direct partitions including partitioning done at boot time. This helps provide flexibility for a manager to make changes across the data center via a platform agent through a partitioning policy. In the cloud environment, policies can allocate portions of the partition under the control of the VMM or OS. This process can be performed in band via a command line protocol communicating with the ODROM/UEFI or out of band through communication with the BMC. In addition to provisioning, these in band and out of band options provide the ability to make other changes with the memory space, such as initiating a secure cryptographic erase of a persistent memory region or changing the security passphrase.
Intel Optane DC Memory Monitoring
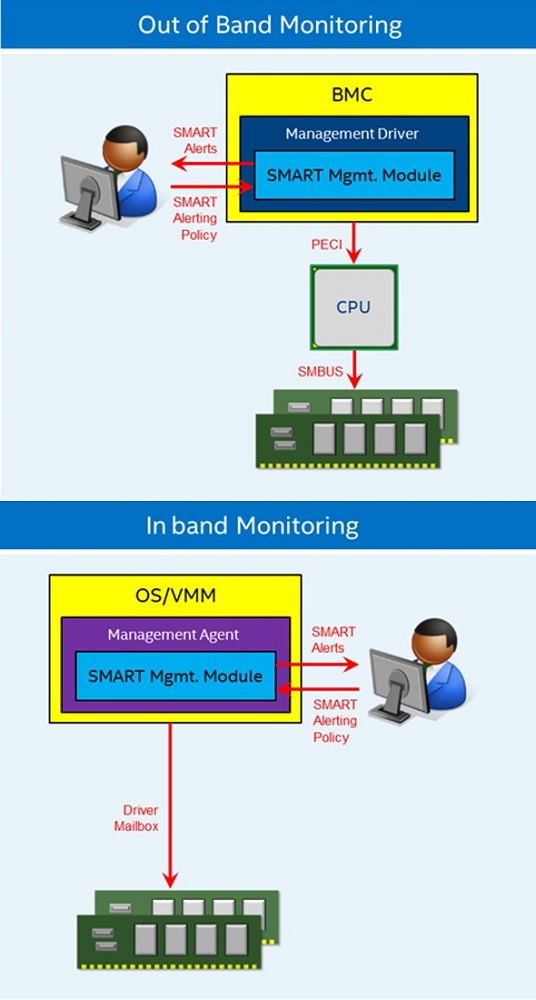
Figure 17. Overview of memory monitoring
There are in band and out of band options for monitoring the status of the Intel Optane DC persistent memory modules. Depending on which method is chosen to monitor the memory, different sensory information is available including such things as power, temperature, and health of the memory, as well as setup for alerts. One option to help monitor memory and other platform aspects is Intel® Node Manager (Intel® NM).
Persistent Memory Resources
These articles, videos, and code samples associated with persistent memory are provided to help accelerate adoption of Intel Optane DC persistent memory modules.
- Persistent Memory on Intel® Developer Zone (Intel® DZ)
- Introducing the Low Level Persistent Library (LLPL) for Java* (video)
- Discover Persistent Memory Programming Errors with Pmemcheck
- Find Your Leaked Persistent Memory Objects Using PMDK
- Making NoSQL Databases Persistent Memory Aware - The Apache Cassandra* Example
- Introduction to the Java* API for Persistent Memory Programming
- Boost Your C++ Applications with Persistent Memory? A Simple grep Example
- Introducing the Low Level Persistent Library (LLPL) for Java
- Code Sample: Panaconda - A Persistent Memory Version of the Game Snake
- The Apache Cassandra* Transformation for Persistent Memory
- Persistent Memory Development Kit (PMDK)
- Open persistent memory programming model
- Entry into overall architecture
- Emulate persistent memory
Intel® AVX512-Deep Learning Boost (Intel® AVX512-DL Boost)
Improving the compute throughput for 8-bit integer data types, Intel® AVX512-DL Boost is a new AVX512 instruction designed to help with the inference aspect of deep learning in neural networks. Deep learning has two aspects: training and inference.
Deep learning uses a variety of algorithms, but the primary use cases are image recognition, voice recognition, and language translation. All of these cases involve a computational model that has a training phase through lots of known inputs. For example, an image recognition algorithm that is designed to predict if a photo contains a cat or a dog would train the model using many known images of cats and dogs. As the algorithm processes each photo, it would come up with a prediction of whether the image depicted a cat or a dog. If a given image of a cat returned a prediction of 80% cat and 20% dog, then the algorithm would need some correction to improve its accuracy.
The algorithm would automatically adjust certain weights to improve accuracy on each subsequent pass of a known input to try and achieve a prediction closer to 100% for each of the known photos of a cat or dog. This is what the training phase entails and it is more compute intensive. The accuracy of the computation is much more valuable and what necessitates a much broader range of numbers. For the accuracy of these numbers to be preserved, floating point data types are more useful for the training phase.
Intel AVX512-DL Boost uses smaller data types and is designed to help with the inference aspect of the workload. The analysis and comparison of the inference process uses smaller batches of data as compared to the training phase. The inference aspect of deep learning is when the algorithm has already been trained with known images, and then an unknown image is provided for analysis. Based on the training phase, the algorithm tries to infer what the unknown image is; in this case, it will try to determine the likelihood that the image it is being shown depicts a cat or dog. Software development support for Intel AVX512-DL Boost is enabled in the Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN). If the foundational Intel® AVX-512 is already being utilized for an application, then enabling of Intel AVX512-DL Boost for the operating system or VMM will be minimal.

Figure 18. New VPDPBUSD instruction replaces three previous instructions
Highlights of Intel AVX512-DL Boost include:
- The introduction of VPDPBUSD, a new 8-bit fused instruction to replace a sequence of three (VPMADDUBSW, VPMADDWD, and VPADDD) instructions by a single instruction in the inner loop.
- Ability to operate on 128 B and 256 B vectors
Intel® Speed Select
Intel® Speed Select Technology is a collection of features that provide more granular control over CPU performance. Traditionally the processor has certain characteristics that are shared across all the cores on the package, such as a fixed base frequency, a thermal limit, or a power envelope. Intel® Speed Select Technology - Performance Profile (Intel® SST-PP) changes the situation by creating the opportunity to assign specific characteristics to groups of processor cores.
Intel SST-PP is a new feature that provides the capability for the processor to run at three distinct operating points. Each operating point has its own profile consisting of the number of cores, base core frequency, thermal design power, and maximum temperature. These operating points are discovered and implemented by the BIOS when the system boots.
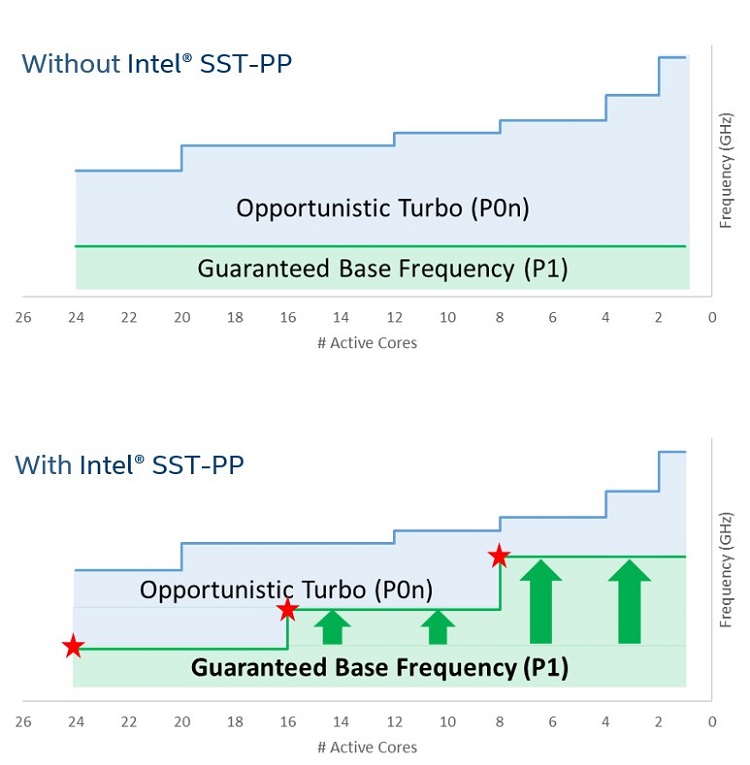
Figure 19. Comparison of a processor with and without Intel® SST-PP. Frequency and core count for illustration purposes only.
Intel Speed Select can improve the guaranteed per-core performance of service level agreements or create multiple processor profiles based on a given workload or virtual machine requirements. The workloads in a data center change over time. Rather than expending manpower to manage the changes or physical movement of resources, Intel Speed Select can provide a remote access solution for automated reconfiguration of a system to meet the changing workload requirements.
The configuration of these different operating points can be done through the BIOS or APIs associated with the RESTful Redfish* management framework. It can also be done through third-party orchestration software that utilizes Intel® Rack Scale Design (Intel® RSD).
Only the second generation Intel® Xeon® processors with a model number ending with the letter “Y” support Intel SST-PP.
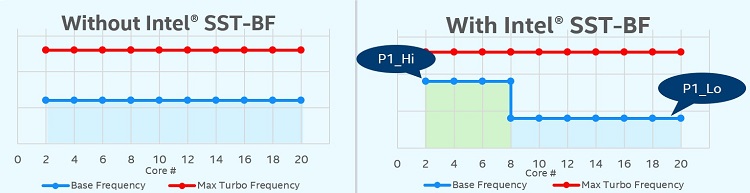
Figure 20. Comparison of a processor with and without Intel® Speed Select Technology - Base Frequency (Intel® SST-BF). Core count for illustration purposes only.
Intel® SST-BF is another new feature that is associated with processor models with an emphasis on network and virtualization workloads. Intel SST-BF provides the capability to increase the base frequency of high priority cores to deal with bottlenecks and lower the base frequency of the other cores for low priority workloads.
Only the select model numbers ending in “N” support Intel SST-PP.
Intel® Resource Director Technology (Intel® RDT)
The set of technologies in the Intel® Resource Director Technology (Intel® RDT) are designed to help monitor and manage shared resources. Intel RDT already has several existing features from previous processor generations that provide benefits such as Cache Monitoring Technology (CMT), Cache Allocation Technology (CAT), Memory Bandwidth Monitoring (MBM), and Code Data Prioritization (CDP).
Intel® Resource Director Technology (Intel® RDT)
For an animation illustrating the key principles behind Intel RDT, see Optimize Resource Utilization with Intel® Resource Director Technology.
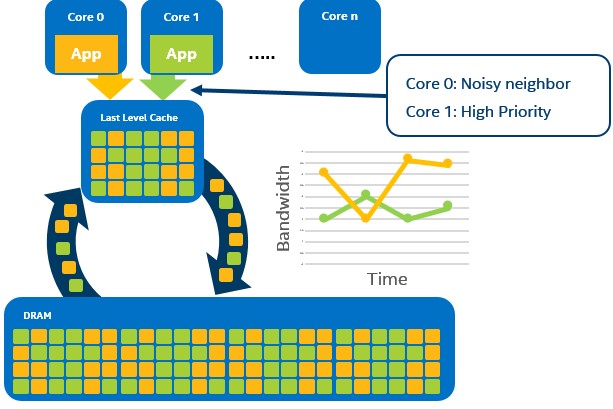
Figure 21. Conceptual diagram of using memory bandwidth monitoring (MBM) to identify noisy neighbor (core 0)
The second generation Intel Xeon processors introduces a new feature called Memory Bandwidth Allocation (MBA), which was added to provide a per-thread memory bandwidth control. This feature can be used in conjunction with MBM to isolate a noisy neighbor. Figure 20 shows an example of a VM or application (orange app in the image on Core 0) that is dominating the memory bandwidth and starving out a second VM or application (green app on Core 1) from the resource. To obtain this level of comprehension of what is happening with the memory bandwidth, use the MBM feature within Intel RDT. MBM utilizes a set of Resource Monitoring IDs (RMIDs) that are assigned to a software thread. The operating system or VMM can then read the memory bandwidth utilization for any given RMID at any time.
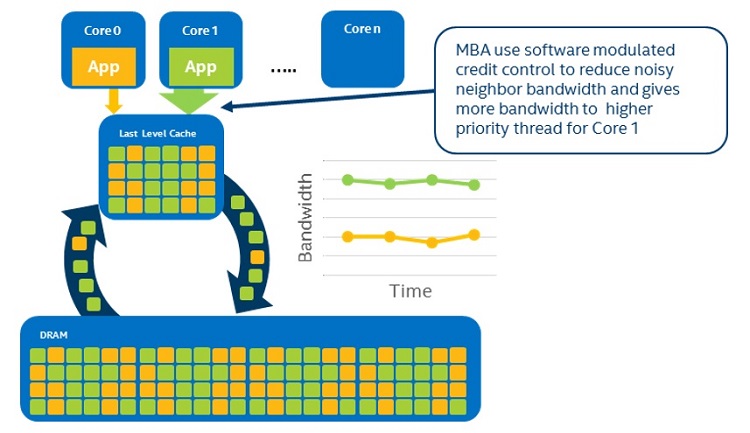
Figure 22. MBA prioritizes memory bandwidth
Once the noisy neighbor has been identified through the MBM, utilize the MBA feature to assign a number of credits to the RMIDs. The noisy neighbor can be given a certain number of credits to allow it to function within the agreed upon service level agreement (SLA), but when it runs out of credits, it will lose access to the memory bandwidth. This then creates enough free overhead for the second VM or application to use the same resource without being starved out.
Intel® 64 and IA-32 Architectures Software Developer’s Manual (Vol. 3) covers programming details of the Intel RDT features in chapter 17.16.
Using this feature requires enabling at the OS or VMM level, and the Intel® Virtualization Technology (Intel® VT) for IA-32, Intel® 64 and Intel® Architecture (Intel® VT-x) feature must be enabled at the BIOS level. For instructions on setting Intel VT-x, refer to your OEM BIOS guide.
Intel RDT Resources
- Reference applications
- Kernel Support Resource Control File System
- Cache Allocation Technology support in c-group
- Cache Monitoring Technology support in perf
- Cache Monitoring Technology support for Intel® Performance Counter Monitor
- Intel RDT errata
Hardware Mitigations for Side-Channel Methods
To improve security vulnerabilities associated with side-channel methods, the second generation Intel Xeon Scalable processor has implemented fixes within the hardware. These changes mitigate Branch Target Injection, Rogue Data Cache Load, and L1 Terminal Fault side channel methods. Hardware fixes are found in all generally available processor SKUs. Some of these hardware fixes require OS kernel and VMM updates please contact your software vendor for support.
Facts about Side-Channel Analysis and Intel Products
Software developer resources and guidance
Software Tools
Below is a list of software tools that are optimized for use with the second generation Intel Xeon Scalable processor.
Table 2. Software tools
| Tool | Version | Description |
|---|---|---|
| Intel® Performance Counter Monitor (Intel® PCM) | 2.11.1 | Provides sample C++ routines and utilities to estimate the internal resource utilization of the processors. |
| Intel® Memory Latency Checker (Intel® MLC) | 3.5 | Test the memory bandwidth of a system. |
| Intel® VTune™ Amplifier 2018 | Analyze and profile the performance of your workload to help with optimization. | |
| Windows* compiler version 18 |
Optimized compiler software and MP LINPACK libraries. |
|
| Linux* compiler version 19 | ||
| Intel® Parallel Studio XE | Optimized MP LINPACK* libraries are included in Intel® Parallel Studio XE | |
|
Optimized developer kits and libraries for storage, network, and persistent memory |
SPDK | spdk.io |
| DPDK | dpdk.org | |
| PMDK | pmem.io | |
| Intel® Xeon® Processor Scalable Memory Family Uncore Performance Monitoring (Zip) | Describes in further detail the uncore and monitoring capabilities of the uncore subcomponents. |
Authors
David Mulnix is a software engineer and has been with Intel Corporation for over 20 years. His areas of focus has included software automation, server power, and performance analysis, and he has contributed to the development support of the Server Efficiency Rating ToolTM.
Contributors: Andy Rudoff
Additional Resources
First Generation Intel Xeon Processor Scalable Family Technical Overview
Intel® 64 and IA-32 Architectures Software Developer’s Manual (SDM)
Intel® Architecture Instruction Set Extensions Programming Reference
Intel Resource Director Technology (Intel RDT)
Intel Xeon Processor Scalable Memory Family Uncore Performance Monitoring (Zip)
Intel® C620 Series Chipset Platform Datasheet
Optimize Resource Utilization with Intel® Resource Director Technology
Intel® Memory Protection Extensions Enabling Guide
Intel® Run Sure Technology
Intel® Hardware-based Security Technologies for Intelligent Retail Devices
Processor Tracing by James Reinders
Intel® Node Manager Programmer’s Reference Kit
Open Source Reference Kit for Intel® Node Manager
How to set up Intel® Node Manager
Intel® Cache Acceleration Software (Intel® CAS)
Intel® Data Center Manager (Intel® DCM)
Intel® Performance Counter Monitor a better way to measure CPU utilization
Intel® Memory Latency Checker (Intel® MLC)
Intel® Data Center Modernization Estimator