This article was originally published on anaconda.cloud
Summary
Anaconda—the most popular data science platform—conducted a multitude of experiments using the scikit-learn benchmark on Amazon Web Services to investigate the impact of using Intel® Extension for Scikit-learn* on “green AI”.
The results:
- 8x acceleration in compute time
- Up to 8.5x less CPU energy consumed
- Up to 7x less energy footprint on DRAM
Introduction
Artificial intelligence (AI) has become an essential part of our daily lives, from helping us to navigate through city traffic to recommending products online. However, developing and running AI systems may have a significant impact on the environment—processing large amounts of data with these systems generally requires considerable energy and computing power and, therefore, significant CO2 emissions are generated to supply servers and other hardware.
For these reasons, there is more and more interest in focusing on green AI, which aims at developing best practices to reduce the environmental footprints of AI systems.
One way to achieve this is through specialized software optimizations, which can help reduce the overall compute time (and, by extension, energy) required to run machine learning (ML) experiments.
In this article, we explore the use of Scikit-learn-intelex (sklearnex), the free and open source extension package designed by Intel to accelerate the Scikit-learn library. This acceleration is achieved via patching1, so it is:
- very easy to use and integrate into any existing machine learning project with minimal disruption and;
-
automatically included in the Anaconda Distribution. So if your computer is running on an Intel® CPU, you can immediately install sklearnex using conda: conda install scikit-learn-intelex.
To investigate the potential impact of the software optimizations included in sklearnex on the energy required to run complex machine learning pipelines2, we conducted several experiments using the scikit-learn benchmark (scikit-learn-bench) on Amazon Web Services* (AWS). We compare the performance of stock (that is, non-optimized) sklearn algorithms with the corresponding Intel-accelerated ones included in sklearnex. For each experiment, we measure the amount of consumed energy for CPU and RAM, along with the overall execution time.
Results show that the Intel-optimized software can speed up the computation by running 8x faster on the whole benchmark, with significantly less energy consumed: up to 8.5x and 7x less footprint on CPU and DRAM, respectively.
Setup and Experimental Settings
The scikit-learn-bench is a publicly available benchmark that supports several machine learning algorithms across multiple data analytics frameworks. The frameworks currently supported are Scikit-learn, DAAL4PY, cuML, and XGBoost. The benchmark is also very easy to use, providing all the necessary automations to configure (via JSON files) and run your machine learning experiments on multiple combinations of framework/model/dataset.
We considered our experiments as organized in the skl_public_config.json configuration file. These experiments include a set of diverse scikit-learn models and tasks, which are tested on multiple combinations of datasets and hyper-parameters to vary the demand of computing resources.
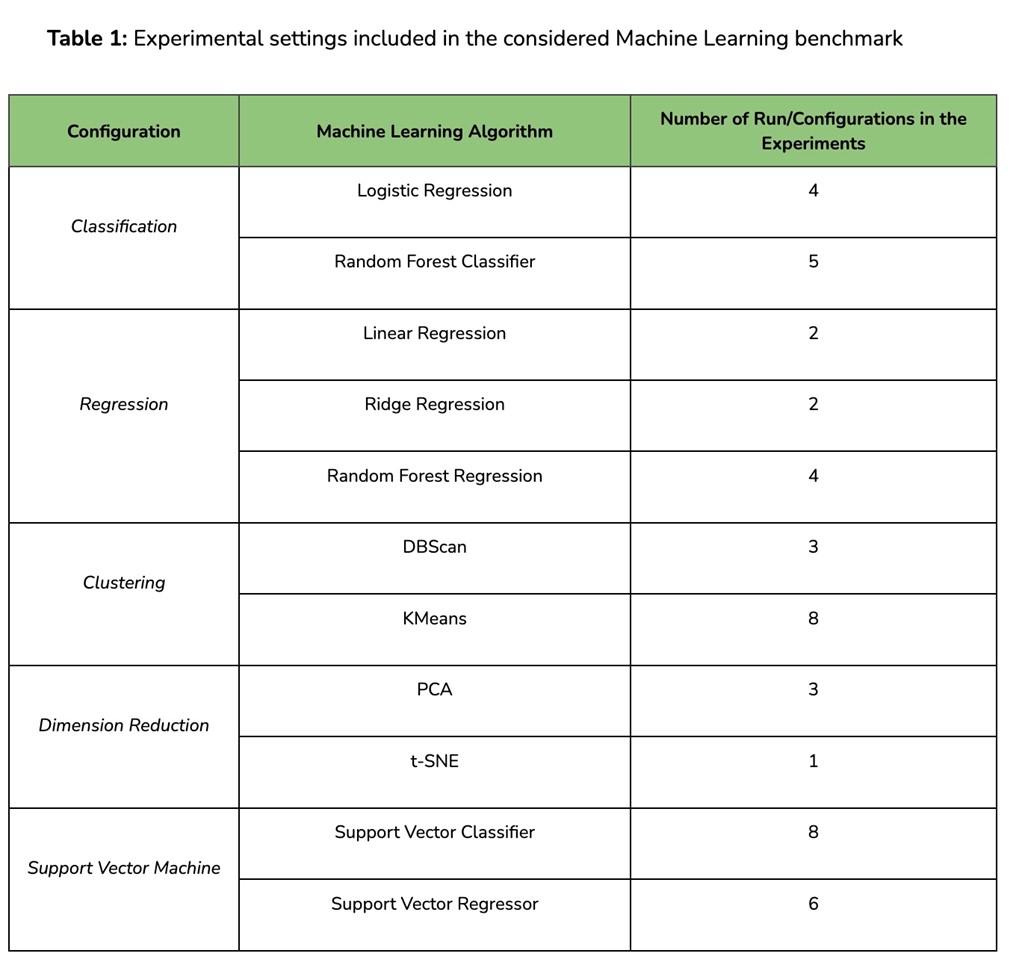
To further investigate the effect of sklearnex optimizations, we defined specialized experimental settings focusing on specific algorithms/tasks combinations: (1) Classification; (2) Regression; (3) Clustering; (4) Dimensionality Reduction. These settings also reflect the same organization of ML tasks as represented in the popular Scikit-learn map.
Finally, an additional set of experiments has also been considered, focusing on the Support Vector Machine algorithm for both classification and regression tasks. This algorithm is well-known to be extremely slow on large amounts of data and very demanding in terms of memory, which makes it a very interesting case in our study. A detailed description of these experimental settings is reported in Table 1.
The bare minimum requirement to run all the experiments in the benchmark is to install sklearn, pandas, and sklearnex in the Python environment. The scikit-learn-intelex package is also automatically included in Anaconda Distribution, so it can be easily added to any existing conda environment:
$ conda install scikit-learn pandas scikit-learn-intelex
To measure the energy consumed by each experiment, we used RAPL (Running Average Power Limit), a technology by Intel that estimates power consumption of the CPU, RAM, and integrated GPU (if any) in real time. This technology has been available on any Intel® CPU since the Sandy Bridge generation (2010, ed.), and it is supported by any operating system (for example, the Power Capping framework on Linux*). To read the energy measurements from RAPL, we use jouleit, a simple script that can be used to monitor the consumption of any program.
All our experiments were run using a c5.metal Amazon EC2 instance. This instance is specifically designed for compute-intensive workloads, featuring 96 cores of custom 2nd generation Intel® Xeon® Scalable Processors (Cascade Lake), and 192 GB of RAM. Moreover, the .metal instances on AWS are among the few instance types that guarantee direct access to the Model-Specific Registers (MSRs) and control the RAPL data from sensors.
All the detailed instructions to set up the experiments, along with necessary replication materials, are available on the anaconda/intel-green-ai GitHub repository.
Results and Discussion
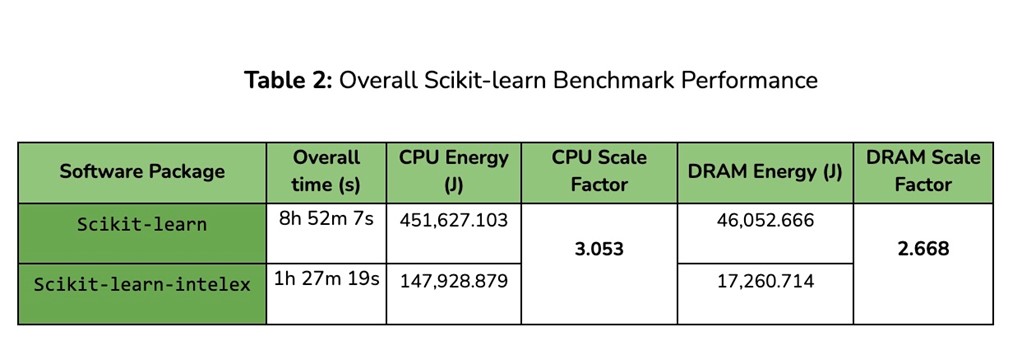
The results of our experiments showed that the scikit-learn-intelex package was able to significantly reduce the amount of compute time required to run machine learning experiments. In fact, to complete the execution of the whole benchmark, the non-optimized code is 8x slower than the Intel-accelerated one (see Table 2).
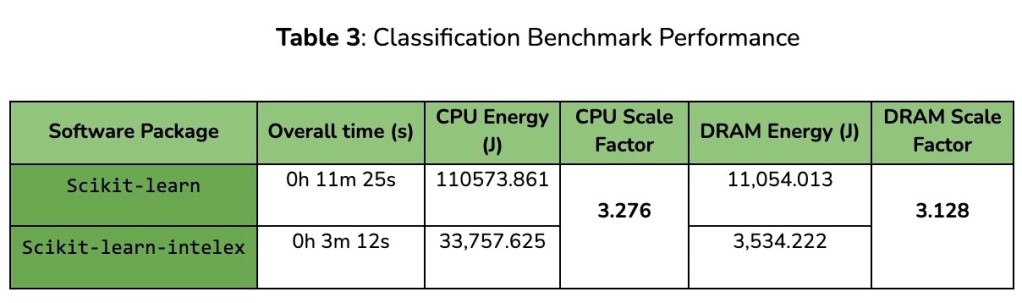
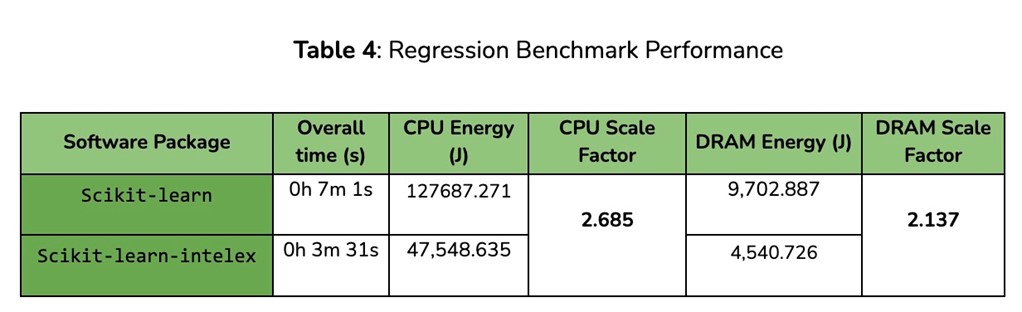
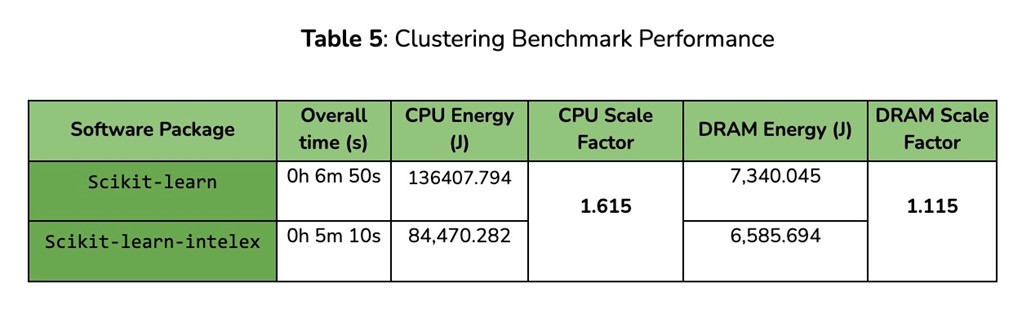
In terms of consumed energy, the scikit-learn-intelex settings required 3x less CPU energy, with a 2.6x less footprint on DRAM on average over the whole benchmark. Similar patterns can also be retrieved in the results of the Classification, Regression, and Clustering experiments (see Tables 3–5).
In addition, these experiments demonstrate a direct correlation between the overall energy gains (obtained by the Intel-optimized software) and their corresponding execution time. For instance, the 3x less energy consumed with the Classification benchmark corresponds to nearly 3x less execution time.
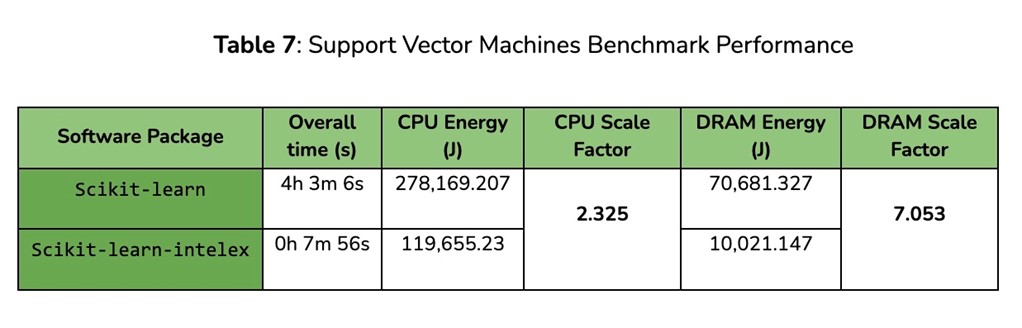
Results for the last two remaining settings are very interesting. Experiments on Dimensionality Reduction tasks achieved the highest energy scale factor on CPU energy overall, with 8.5x less energy consumed. This is mainly due to very efficient optimizations provided with the PCA algorithm. On the other hand, the Support Vector Machines results demonstrated the highest energy scale factor on DRAM (around 7x less memory footprint). This result is particularly promising as it demonstrates that the SVM implementation included in scikit-learn-intelex is capable of processing larger amounts of data that would’ve normally been prohibitive for its corresponding non-optimized implementation. Measured energy consumption accounts for CPU and memory while there would be larger base consumption from the entire system, so overall positive impact on energy consumption and emissions would be even larger.
To put these results in perspective, we can compare the estimated CO2 savings achieved through the use of the scikit-learn-intelex package to other common CO2 reduction activities. In comparison, the use of the stock scikit-learn package on a single AWS C5.metal instance (us-east-01 N. Virginia region) for an hour-long workload would generate 0.2 CO2 kg per hour, while the more intensive but much shorter burst of scikit-learn-intelex would generate just 0.04 CO2 kg, resulting in reduction of 0.16 CO2 kg. Assuming 40 hours per week, we would reach 330 CO2 kg of emissions reduction from a single instance per year.
To further illustrate the impact of these savings, we can compare them to the CO2 cost of everyday goods. For example, the production of a single paper coffee cup generates approximately 0.3 kg of CO2, 10 km drive on Tesla Model 3 generates approximately 0.8 kg of CO2. This means that the CO2 savings achieved through the use of the scikit-learn-intelex package on a single AWS C5.metal instance is equivalent to the CO2 emissions generated by the production of approximately 1,000 coffee cups or driving 350 km on Tesla Model 3.

Conclusion
Overall, the use of software optimizations like the scikit-learn-intelex package can have a significant impact on the amount of energy consumed by machine learning experiments. By enabling faster and more efficient computations, these tools can significantly help to reduce the demand for compute power and lower the environmental impact of AI workloads.
While these savings may seem small on an individual level, the impact can be significant when considering the scale of AI development. By adopting green AI practices, we can help to reduce the environmental impact of AI and contribute to a more sustainable future.
Explore More
Watch the video
See the Anaconda demo in action [31:17]
Download the tools
Get the Intel Extension for Scikit-learn standalone or as part of the Intel® AI Analytics Toolkit.