SYCL* Thread Mapping and GPU Occupancy
The SYCL* execution model exposes an abstract view of GPU execution. The SYCL thread hierarchy consists of a 1-, 2-, or 3-dimensional grid of work-items. These work-items are grouped into equal sized thread groups called work-groups. Threads in a work-group are further divided into equal sized vector groups called sub-groups (see the illustration that follows).
- Work-item
-
A work-item represents one of a collection of parallel executions of a kernel.
- Sub-group
-
A sub-group represents a short range of consecutive work-items that are processed together as a SIMD vector of length 8, 16, 32, or a multiple of the native vector length of a CPU with Intel® UHD Graphics.
- Work-group
-
A work-group is a 1-, 2-, or 3-dimensional set of threads within the thread hierarchy. In SYCL, synchronization across work-items is only possible with barriers for the work-items within the same work-group.
nd_range
An nd_range divides the thread hierarchy into 1-, 2-, or 3-dimensional grids of work-groups. It is represented by the global range, the local range of each work-group.
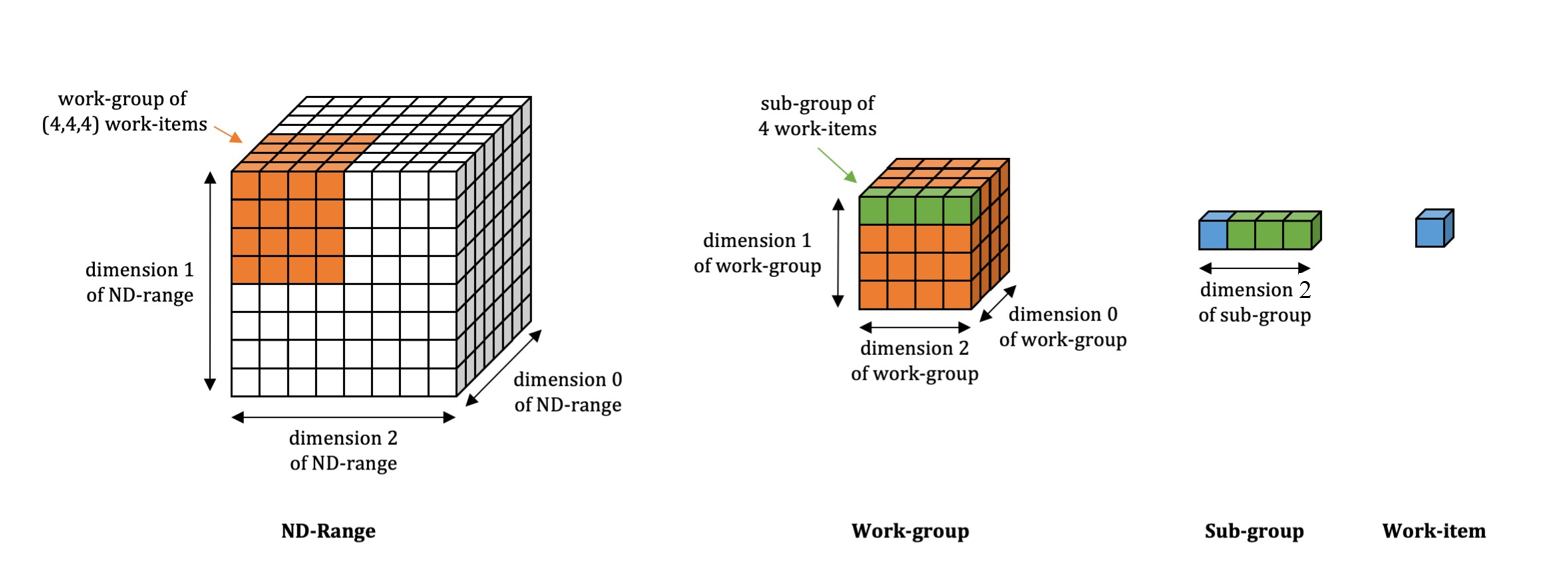
The diagram above illustrates the relationship among ND-Range, work-group, sub-group, and work-item.
Thread Synchronization
SYCL provides two synchronization mechanisms that can be called within a kernel function. Both are only defined for work-items within the same work-group. SYCL does not provide any global synchronization mechanism inside a kernel for all work-items across the entire nd_range.
``mem_fence`` inserts a memory fence on global and local memory access across all work-items in a work-group.
``barrier`` inserts a memory fence and blocks the execution of all work-items within the work-group until all work-items have reached its location.
Mapping Work-groups to Xe-cores for Maximum Occupancy
The rest of this chapter explains how to pick a proper work-group size to maximize the occupancy of the GPU resources. The example system is the Tiger Lake processors with Xe-LP GPU as the execution target. The examples also use the new terminologies Xe-core (XC) for Dual Subslice, and Xe Vector Engine (XVE) for Execution Unit.
From the Key architecture parameters, Intel UHD Graphics table, we summarize the architecture parameters for Xe-LP Graphics (TGL) GPU below:
VEs |
Threads |
Operations |
Maximum Work Group Size |
|
|---|---|---|---|---|
Each Xe-core |
16 |
|
|
512 |
Total |
|
|
|
512 |
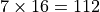
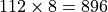

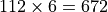

The maximum work-group size is a constraint imposed by the hardware and GPU driver. You can query the maximum work-group using device::get_info<cl::sycl::info::device::max_work_group_size>() on the supported size.
Let’s start with a simple kernel:
auto command_group =
[&](auto &cgh) {
cgh.parallel_for(sycl::range<3>(64, 64, 64), // global range
[=](item<3> it) {
// (kernel code)
})
}
This kernel contains 262,144 work-items structured as a 3D range of 64 x 64 x 64. It leaves the work-group and sub-group size selection to the compiler. To fully utilize the 5376 parallel operations available in the GPU slice, the compiler must choose a proper work group size.
The two most important GPU resources are:
Thread Contexts:: The kernel should have a sufficient number of threads to utilize the GPU’s thread contexts.
SIMD Units and SIMD Registers:: The kernel should be organized to vectorize the work-items and utilize the SIMD registers.
In a SYCL kernel, the programmer can affect the work distribution by structuring the kernel with proper work-group size, sub-group size, and organizing the work-items for efficient vector execution. Writing efficient vector kernels is covered in a separate section. This chapter focuses on work-group and sub-group size selection.
Thread contexts are easier to utilize than SIMD vector. Therefore, start with selecting the number of threads in a work-group. Each Xe-core has 112 thread contexts, but usually you cannot use all the threads if the kernel is also vectorized by 8 (112 x 8 = 896 > 512). From this, we can derive that the maximum number of threads in a work-group is 64 (512 / 8).
SYCL does not provide a mechanism to directly set the number of threads in a work-group. However, you can use work-group size and SIMD sub-group size to set the number of threads:
Work group size = Threads x SIMD sub-group size
You can increase the sub-group size as long as there are a sufficient number of registers for the kernel after widening. Note that each VE has 128 SIMD8 registers so there is a lot of room for widening on simple kernels. The effect of increasing sub-group size is similar to loop unrolling: while each VE still executes eight 32-bit operations per cycle, the amount of work per work-group interaction is doubled/quadrupled. In SYCL, a programmer can explicitly specify sub-group size using intel::reqd_sub_group_size({8|16|32}) to override the compiler’s selection.
The table below summarizes the selection criteria of threads and sub-group sizes to keep all GPU resources occupied for TGL:
Maximum Threads |
Minimum Sub-group Size |
Maximum Sub-group Size |
Maximum Work-group Size |
Constraint |
|---|---|---|---|---|
64 |
8 |
32 |
512 |
|
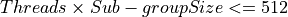
In general, choosing a larger work-group size has the advantage of reducing the number of rounds of work-group dispatching. Increasing sub-group size can reduce the number of threads required for a work-group at the expense of longer latency and higher register pressure for each sub-group execution.
Impact of Work-item Synchronization Within Work-group
Let’s look at a kernel requiring work-item synchronization:
auto command_group =
[&](auto &cgh) {
cgh.parallel_for(nd_range(sycl::range(64, 64, 128), // global range
sycl::range(1, R, 128) // local range
),
[=](sycl::nd_item<3> item) {
// (kernel code)
// Internal synchronization
item.barrier(access::fence_space::global_space);
// (kernel code)
})
}
This kernel is similar to the previous example, except it requires work-group barrier synchronization. Work-item synchronization is only available to work-items within the same work-group. You must pick a work-group local range using nd_range and nd_item. All the work-items of a work-group must be allocated to the same Xe-core, which affects Xe-core occupancy and kernel performance.
In this kernel, the local range of work-group is given as range(1, R, 128). Assuming the sub-group size is eight, let’s look at how the values of variable R affect VE occupancy. In the case of R=1, the local group range is (1, 1, 128) and work-group size is 128. The Xe-core allocated for a work-group contains only 16 threads out of 112 available thread contexts (i.e., very low occupancy). However, the system can dispatch 7 work-groups to the same Xe-core to reach full occupancy at the expense of a higher number of dispatches.
In the case of R>4, the work-group size will exceed the system-supported maximum work-group size of 512, and the kernel will fail to launch. In the case of R=4, an Xe-core is only 57% occupied (4/7) and the three unused thread contexts are not sufficient to accommodate another work-group, wasting 43% of the available VE capacities. Note that the driver may still be able to dispatch a partial work-group to an unused Xe-core. However, because of the barrier in the kernel, the partially dispatched work items would not be able to pass the barriers until the rest of the work group is dispatched. In most cases, the kernel’s performance would not benefit much from the partial dispatch. Hence, it is important to avoid this problem by properly choosing the work-group size.
The table below summarizes the tradeoffs between group size, number of threads, Xe-core utilization, and occupancy.
Work-items |
Group Size |
Threads |
Xe-core Utilization |
Xe-core Occupancy |
|---|---|---|---|---|
|
(R=1) 128 |
16 |
|
|
|
(R=2) |
|
|
|
|
(R=3) |
|
|
|
|
(R=4) |
|
|
|
|
(R>4) 640+ |
Fail to launch |
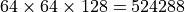
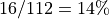
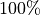 with 7 work-groups
with 7 work-groups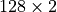

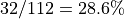
 with 3 work-groups
with 3 work-groups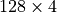
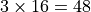
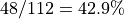
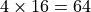
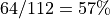
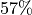 maximum
maximumImpact of Local Memory Within Work-group
Let’s look at an example where a kernel allocates local memory for a work-group:
auto command_group =
[&](auto &cgh) {
// local memory variables shared among work items
sycl::accessor<int, 1, sycl::access::mode::read_write,
sycl::access::target::local>
myLocal(sycl::range(R), cgh);
cgh.parallel_for(nd_range(sycl::range<3>(64, 64, 128), // global range
sycl::range<3>(1, R, 128) // local range
),
[=](ngroup<3> myGroup) {
// (work group code)
myLocal[myGroup.get_local_id()[1]] = ...
})
}
Because work-group local variables are shared among its work-items, they are allocated in a Xe-core’s SLM. Therefore, this work-group must be allocated to a single Xe-core, same as the intra-group synchronization. In addition, you must also weigh the sizes of local variables under different group size options such that the local variables fit within an Xe-core’s 128KB SLM capacity limit.
A Detailed Example
Before concluding this section, let’s look at the hardware occupancies from the variants of a simple vector add example. Using Intel® Iris® Xe graphics from TGL platform as the underlying hardware with the resource parameters specified in Xe-LP (TGL) GPU.
int VectorAdd1(sycl::queue &q, const IntArray &a, const IntArray &b,
IntArray &sum, int iter) {
sycl::range num_items{a.size()};
sycl::buffer a_buf(a);
sycl::buffer b_buf(b);
sycl::buffer sum_buf(sum.data(), num_items);
auto start = std::chrono::steady_clock::now();
auto e = q.submit([&](auto &h) {
// Input accessors
sycl::accessor a_acc(a_buf, h, sycl::read_only);
sycl::accessor b_acc(b_buf, h, sycl::read_only);
// Output accessor
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(num_items, [=](auto i) {
for (int j = 0; j < iter; j++)
sum_acc[i] = a_acc[i] + b_acc[i];
});
});
q.wait();
auto end = std::chrono::steady_clock::now();
std::cout << "VectorAdd1 completed on device - took " << (end - start).count()
<< " u-secs\n";
return ((end - start).count());
} // end VectorAdd1
The VectorAdd1 above lets the compiler select the work-group size and SIMD width. In this case, the compiler selects a work-group size of 512 and a SIMD width of 32 because the kernel’s register pressure is low.
int VectorAdd2(sycl::queue &q, const IntArray &a, const IntArray &b,
IntArray &sum, int iter) {
sycl::range num_items{a.size()};
sycl::buffer a_buf(a);
sycl::buffer b_buf(b);
sycl::buffer sum_buf(sum.data(), num_items);
size_t num_groups = groups;
size_t wg_size = 512;
// get the max wg_sie instead of 512 size_t wg_size = 512;
auto start = std::chrono::steady_clock::now();
q.submit([&](auto &h) {
// Input accessors
sycl::accessor a_acc(a_buf, h, sycl::read_only);
sycl::accessor b_acc(b_buf, h, sycl::read_only);
// Output accessor
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(
sycl::nd_range<1>(num_groups * wg_size, wg_size),
[=](sycl::nd_item<1> index) [[intel::reqd_sub_group_size(32)]] {
size_t grp_id = index.get_group()[0];
size_t loc_id = index.get_local_id();
size_t start = grp_id * mysize;
size_t end = start + mysize;
for (int i = 0; i < iter; i++)
for (size_t i = start + loc_id; i < end; i += wg_size) {
sum_acc[i] = a_acc[i] + b_acc[i];
}
});
});
q.wait();
auto end = std::chrono::steady_clock::now();
std::cout << "VectorAdd2<" << groups << "> completed on device - took "
<< (end - start).count() << " u-secs\n";
return ((end - start).count());
} // end VectorAdd2
The VectorAdd2 example above explicitly specifies the work-group size of 512, SIMD width of 32, and a variable number of work-groups as a function parameter groups.
Dividing the number of threads by the number of available thread contexts in the GPU gives us an estimate of the GPU hardware occupancy. The following table calculates the GPU hardware occupancy using the TGL Intel® Iris® Xe architecture parameters for each of the above two kernels with various arguments.
Program Occupancy |
Work-groups |
Work-items |
Work-group Size |
SIMD |
Threads Work-group |
Threads |
Occupancy |
|---|---|---|---|---|---|---|---|
VectorAdd1 |
53760 |
27.5M |
512 |
32 |
16 |
860K |
100% |
VectorAdd2<1> |
1 |
512 |
512 |
32 |
16 |
16 |
16/672 = 2.4% |
VectorAdd2<2> |
2 |
1024 |
512 |
32 |
16 |
32 |
32/672 = 4.8% |
VectorAdd2<3> |
3 |
1536 |
512 |
32 |
16 |
48 |
48/672 = 7.1% |
VectorAdd2<4> |
4 |
2048 |
512 |
32 |
16 |
64 |
64/672 = 9.5% |
VectorAdd2<5> |
5 |
2560 |
512 |
32 |
16 |
80 |
80/672 = 11.9% |
VectorAdd2<6> |
6 |
3072 |
512 |
32 |
16 |
96 |
96/672 = 14.3% |
VectorAdd2<7> |
7 |
3584 |
512 |
32 |
16 |
112 |
112/672 = 16.7% |
VectorAdd2<8> |
8 |
4096 |
512 |
32 |
16 |
128 |
128/672 = 19% |
VectorAdd2<12> |
12 |
6144 |
512 |
32 |
16 |
192 |
192/672 = 28.6% |
VectorAdd2<16> |
16 |
8192 |
512 |
32 |
16 |
256 |
256/672 = 38.1% |
VectorAdd2<20> |
20 |
10240 |
512 |
32 |
16 |
320 |
320/672 = 47.7% |
VectorAdd2<24> |
24 |
12288 |
512 |
32 |
16 |
384 |
384/672 = 57.1% |
VectorAdd2<28> |
28 |
14336 |
512 |
32 |
16 |
448 |
448/672 = 66.7% |
VectorAdd2<32> |
32 |
16384 |
512 |
32 |
16 |
512 |
512/672 = 76.2% |
VectorAdd2<36> |
36 |
18432 |
512 |
32 |
16 |
576 |
576/672 = 85.7% |
VectorAdd2<40> |
40 |
20480 |
512 |
32 |
16 |
640 |
640/672 = 95.2% |
VectorAdd2<42> |
42 |
21504 |
512 |
32 |
16 |
672 |
672/672 = 100% |
VectorAdd2<44> |
44 |
22528 |
512 |
32 |
16 |
704 |
100% then 4.7% |
VectorAdd2<48> |
48 |
24576 |
512 |
32 |
16 |
768 |
100% then 14.3% |
The following VTune analyzer chart for VectorAdd2 with various work-group sizes confirms the accuracy of our estimate. The numbers in the grid view vary slightly from the estimate because the grid view gives an average across the entire execution.
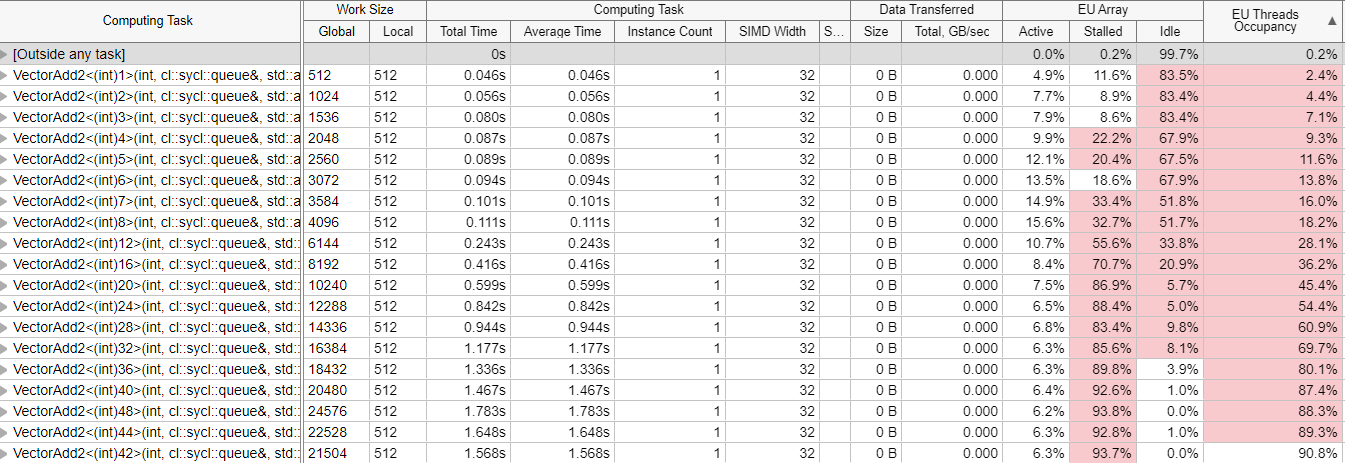
The following timeline view gives the occupancy over a period of time. Note that the occupancy metric is accurate for a large part of the kernel execution and tapers off towards the end, due to the varying times at which each of the threads finish their execution.

The kernel VectorAdd3 shown below is similar to the kernels above with two important differences.
It can be instantiated with the number of work-groups, work-group size, and sub-group size as template parameters. This allows us to do experiments to investigate the impact of number of sub-groups and work-groups on thread occupancy.
The amount of work done inside the kernel is dramatically increased to ensure that these kernels are resident in the execution units doing work for a substantial amount of time.
template <int groups, int wg_size, int sg_size>
int VectorAdd3(sycl::queue &q, const IntArray &a, const IntArray &b,
IntArray &sum, int iter) {
sycl::range num_items{a.size()};
sycl::buffer a_buf(a);
sycl::buffer b_buf(b);
sycl::buffer sum_buf(sum.data(), num_items);
size_t num_groups = groups;
auto start = std::chrono::steady_clock::now();
q.submit([&](auto &h) {
// Input accessors
sycl::accessor a_acc(a_buf, h, sycl::read_only);
sycl::accessor b_acc(b_buf, h, sycl::read_only);
// Output accessor
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(
sycl::nd_range<1>(num_groups * wg_size, wg_size),
[=](sycl::nd_item<1> index) [[intel::reqd_sub_group_size(sg_size)]] {
size_t grp_id = index.get_group()[0];
size_t loc_id = index.get_local_id();
size_t start = grp_id * mysize;
size_t end = start + mysize;
for (int i = 0; i < iter; i++)
for (size_t i = start + loc_id; i < end; i += wg_size) {
sum_acc[i] = a_acc[i] + b_acc[i];
}
});
});
q.wait();
auto end = std::chrono::steady_clock::now();
std::cout << "VectorAdd3<" << groups << "> completed on device - took "
<< (end - start).count() << " u-secs\n";
return ((end - start).count());
} // end VectorAdd3
The kernel VectorAdd4 is similar to the kernel VectorAdd3 above except that it has a barrier synchronization at the beginning and end of the kernel execution. This barrier is functionally not needed, but will significantly impact the way in which threads are scheduled on the hardware.
template <int groups, int wg_size, int sg_size>
int VectorAdd4(sycl::queue &q, const IntArray &a, const IntArray &b,
IntArray &sum, int iter) {
sycl::range num_items{a.size()};
sycl::buffer a_buf(a);
sycl::buffer b_buf(b);
sycl::buffer sum_buf(sum.data(), num_items);
size_t num_groups = groups;
auto start = std::chrono::steady_clock::now();
q.submit([&](auto &h) {
// Input accessors
sycl::accessor a_acc(a_buf, h, sycl::read_only);
sycl::accessor b_acc(b_buf, h, sycl::read_only);
// Output accessor
sycl::accessor sum_acc(sum_buf, h, sycl::write_only, sycl::no_init);
h.parallel_for(
sycl::nd_range<1>(num_groups * wg_size, wg_size),
[=](sycl::nd_item<1> index) [[intel::reqd_sub_group_size(sg_size)]] {
index.barrier(sycl::access::fence_space::local_space);
size_t grp_id = index.get_group()[0];
size_t loc_id = index.get_local_id();
size_t start = grp_id * mysize;
size_t end = start + mysize;
for (int i = 0; i < iter; i++) {
for (size_t i = start + loc_id; i < end; i += wg_size) {
sum_acc[i] = a_acc[i] + b_acc[i];
}
}
});
});
q.wait();
auto end = std::chrono::steady_clock::now();
std::cout << "VectorAdd4<" << groups << "> completed on device - took "
<< (end - start).count() << " u-secs\n";
return ((end - start).count());
} // end VectorAdd4
To show how threads are scheduled, the above two kernels are called with 8 work-groups, sub-group size of 8 and work-group size of 320 as shown below. Based on the choice of work-group size and sub-group size, 40 threads per work-group need to be scheduled by the hardware.
Initialize(sum); VectorAdd3<8, 320, 8>(q, a, b, sum, 10000); Initialize(sum); VectorAdd4<8, 320, 8>(q, a, b, sum, 10000);
The chart from VTune below shows that the measured GPU occupancy for VectorAdd3 and VectorAdd4 kernels.
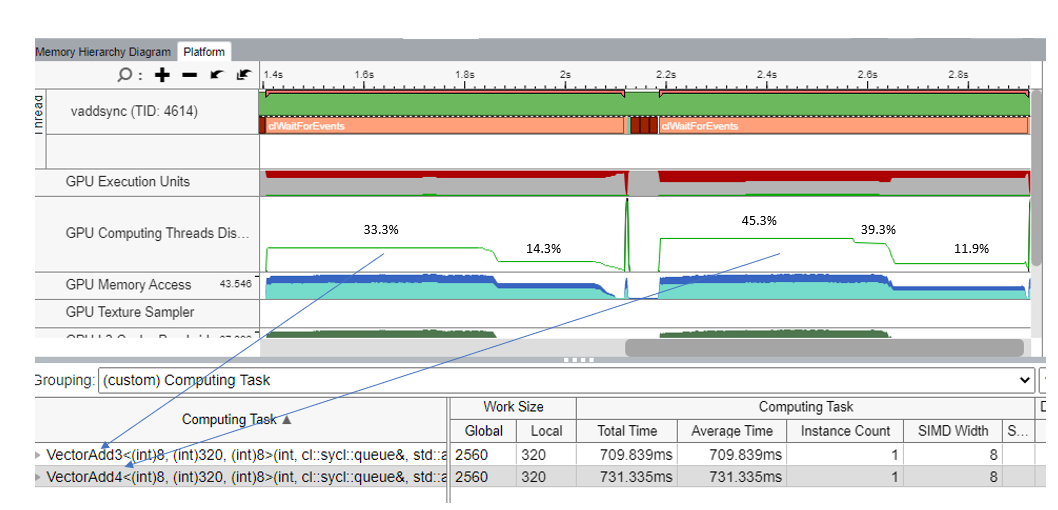
For the VectorAdd3 kernel, there are two phases for occupancies: 33.3% (224 threads occupancy) and 14.3% (96 threads occupancy) on a TGL machine that has a total of 672 threads. Since there are a total of eight work-groups, with each work-group having 40 threads, there are two Xe-cores (each of which have 112 threads) into which the threads of six work-groups are scheduled. This means that 40 threads each from four work-groups are scheduled, and 32 threads each from two other work-groups are scheduled in the first phase. Then in the second phase, 40 threads from the remaining two work-groups are scheduled for execution.
As seen in the VectorAdd4 kernel, there are three phases of occupancies: 45.3% (304 threads), 39.3% (264 threads), and 11.9% (80 threads). In the first phase, all eight work-groups are scheduled together on 3 Xe-cores, with two Xe-cores getting 112 threads each (80 from two work-groups and 32 from one work-group) and one Xe-core getting 80 threads (from two work-groups). In the second phase, one work-group completed execution, which gives us occupancy of (304-40=264). In the last phase, the remaining eight threads of two work-groups are scheduled and these complete the execution.
The same kernels as above when run with a work-group size that is a multiple of the number of threads in a Xe-core and lot more work-groups gets good utilization of the hardware achieving close to 100% occupancy, as shown below.
Initialize(sum); VectorAdd3<24, 224, 8>(q, a, b, sum, 10000); Initialize(sum); VectorAdd4<24, 224, 8>(q, a, b, sum, 10000);
This kernel execution has a different thread occupancy since we have many more threads and also the work-group size is a multiple of the number of threads in a Xe-core. This is shown below in the thread occupancy metric on the VTune timeline.

Note that the above schedule is a guess based on the different occupancy numbers, since we do not yet have a way to examine the per slice based occupancy numbers.
You can run different experiments with the above kernels to gain better understanding of how the GPU hardware schedules the software threads on the Execution Units. Be careful about the work-group and sub-group sizes, in addition to a large number of work-groups, to ensure effective utilization of the GPU hardware.
Intel® GPU Occupancy Calculator
In summary, a SYCL work-group is typically dispatched to an Xe-core. All the work-items in a work-group shares the same SLM of an Xe-core for intra work-group thread barriers and memory fence synchronization. Multiple work-groups can be dispatched to the same Xe-core if there are sufficient VE ALUs, SLM, and thread contexts to accommodate them.
You can achieve higher performance by fully utilizing all available Xe-cores. Parameters affecting a kernel’s GPU occupancy are work-group size and SIMD sub-group size, which also determines the number of threads in the work-group.
The Intel® GPU Occupancy Calculator can be used to calculate the occupancy on an Intel GPU for a given kernel, and its work-group parameters.