A newer version of this document is available. Customers should click here to go to the newest version.
Visible to Intel only — GUID: GUID-DF1F85BE-56D5-45AF-B30F-1629E3E6F695
Visible to Intel only — GUID: GUID-DF1F85BE-56D5-45AF-B30F-1629E3E6F695
GPU Execution Model Overview
The General Purpose GPU (GPGPU) compute model consists of a host connected to one or more compute devices. Each compute device consists of many GPU Compute Engines (CE), also known as Execution Units (EU) or Xe Vector Engines (XVE). The compute devices may also include caches, shared local memory (SLM), high-bandwidth memory (HBM), and so on, as shown in the figure General Purpose Compute Model. Applications are then built as a combination of host software (per the host framework) and kernels submitted by the host to run on the VEs with a predefined decoupling point.
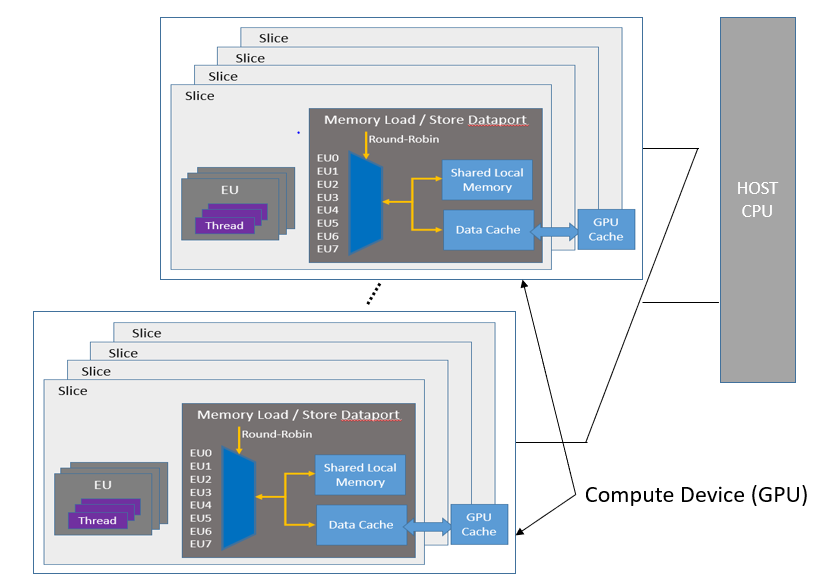
The GPGPU compute architecture contains two distinct units of execution: a host program and a set of kernels that execute within the context set by the host. The host interacts with these kernels through a command queue. Each device may have its own command queue. When a command is submitted into the command queue, the command is checked for dependencies and then executed on a VE inside the compute unit clusters. Once the command has finished executing, the kernel communicates an end of life cycle through “end of thread” message.
The GP execution model determines how to schedule and execute the kernels. When a kernel-enqueue command submits a kernel for execution, the command defines an index space or N-dimensional range. A kernel-instance consists of the kernel, the argument values associated with the kernel, and the parameters that define the index space. When a compute device executes a kernel-instance, the kernel function executes for each point in the defined index space or N-dimensional range.
An executing kernel function is called a work-item, and a collection of these work-items is called a work-group. A compute device manages work-items using work-groups. Individual work-items are identified by either a global ID, or a combination of the work-group ID and a local ID inside the work-group.
The work-group concept, which essentially runs the same kernel on several unit items in a group, captures the essence of data parallel computing. The VEs can organize work-items in SIMD vector format and run the same kernel on the SIMD vector, hence speeding up the compute for all such applications.
A device can compute each work-group in any arbitrary order. Also, the work-items within a single work-group execute concurrently, with no guarantee on the order of progress. A high level work-group function, like Barriers, applies to each work-item in a work-group, to facilitate the required synchronization points. Such a work-group function must be defined so that all work-items in the work-group encounter precisely the same work-group function.
Synchronization can also occur at the command level, where the synchronization can happen between commands in host command-queues. In this mode, one command can depend on execution points in another command or multiple commands.
Other types of synchronization based on memory-order constraints inside a program include Atomics and Fences. These synchronization types control how a memory operation of any particular work-item is made visible to another, which offers micro-level synchronization points in the data-parallel compute model.
Note that an Intel GPU device is equipped with many Vector Engines (VEs), and each VE is a multi-threaded SIMD processor. Compiler generates SIMD code to map several work-items to be executed simultaneously within a given hardware thread. The SIMD-width for a kernel is a heuristic driven compiler choice. Common SIMD-width examples are SIMD-8, SIMD-16, and SIMD-32.
For a given SIMD-width, if all kernel instances within a thread are executing the same instruction, the SIMD lanes can be maximally utilized. If one or more of the kernel instances choose a divergent branch, then the thread executes the two paths of the branch and merges the results by mask. The VE’s branch unit keeps track of such branch divergence and branch nesting.