Intel® FPGA SDK for OpenCL™ Pro Edition: Best Practices Guide
A newer version of this document is available. Customers should click here to go to the newest version.
6.1.4. Relaxing Loop-Carried Dependency by Inferring Shift Registers
Consider the following kernel:
1 __kernel void double_add_1 (__global double *arr,
2 int N,
3 __global double *result)
4 {
5 double temp_sum = 0;
6
7 for (int i = 0; i < N; ++i)
8 {
9 temp_sum += arr[i];
10 }
11
12 *result = temp_sum;
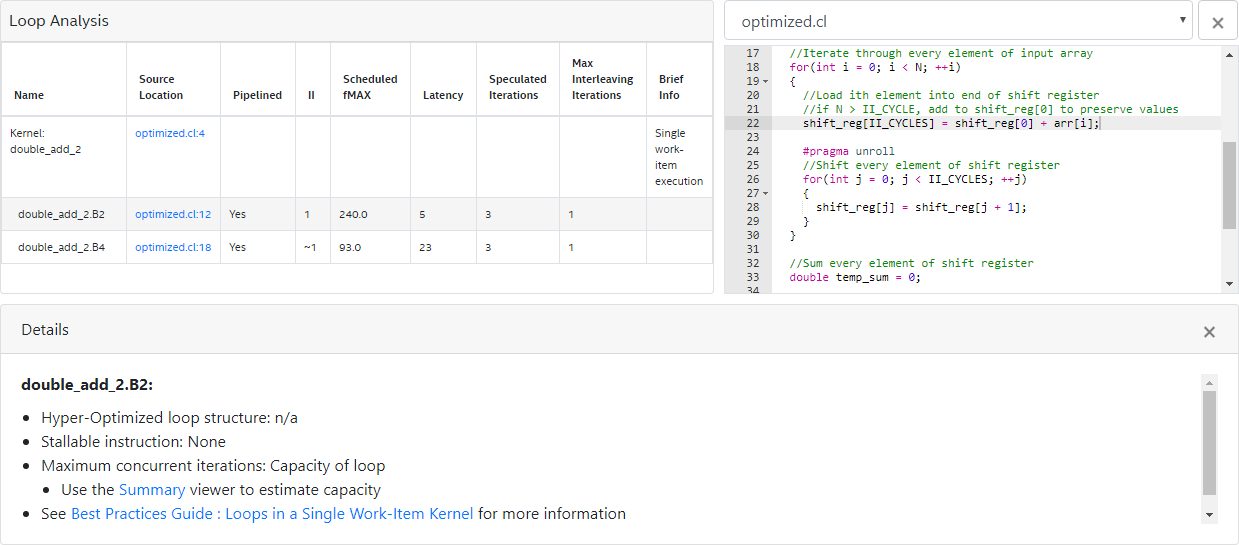
13 }The optimization report for kernel unoptimized resembles the following: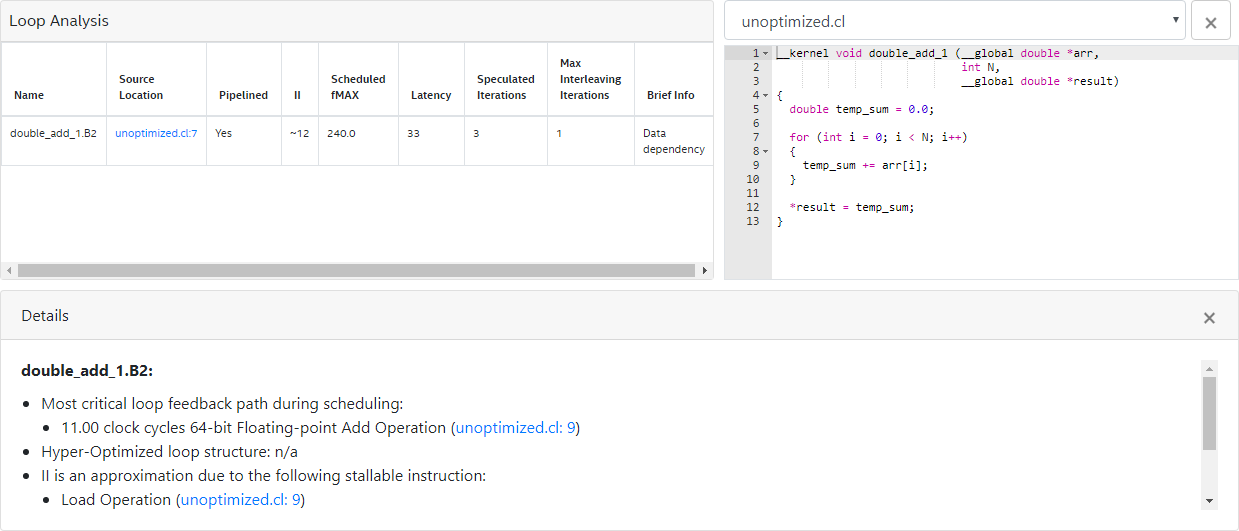
The kernel unoptimized is an accumulator that sums the elements of a double precision floating-point array arr[i]. For each loop iteration, the offline compiler takes 11 cycles to compute the result of the addition and then stores it in the variable temp_sum. Each loop iteration requires the value of temp_sum from the previous loop iteration, which creates a data dependency on temp_sum.
Below is the restructured kernel optimized:
1 //Shift register size must be statically determinable
2 #define II_CYCLES 12
3
4 __kernel void double_add_2 (__global double *arr,
5 int N,
6 __global double *result)
7 {
8 //Create shift register with II_CYCLE+1 elements
9 double shift_reg[II_CYCLES+1];
10
11 //Initialize all elements of the register to 0
12 for (int i = 0; i < II_CYCLES + 1; i++)
13 {
14 shift_reg[i] = 0;
15 }
16
17 //Iterate through every element of input array
18 for(int i = 0; i < N; ++i)
19 {
20 //Load ith element into end of shift register
21 //if N > II_CYCLE, add to shift_reg[0] to preserve values
22 shift_reg[II_CYCLES] = shift_reg[0] + arr[i];
23
24 #pragma unroll
25 //Shift every element of shift register
26 for(int j = 0; j < II_CYCLES; ++j)
27 {
28 shift_reg[j] = shift_reg[j + 1];
29 }
30 }
31
32 //Sum every element of shift register
33 double temp_sum = 0;
34
35 #pragma unroll
36 for(int i = 0; i < II_CYCLES; ++i)
37 {
38 temp_sum += shift_reg[i];
39 }
40
41 *result = temp_sum;
42 }The following optimization report indicates that the inference of the shift register shift_reg[II_CYCLES] successfully removes the data dependency on the variable temp_sum: