Transition Guide
Upgrading from Intel® Media SDK to Intel® oneAPI Video Processing Library
A newer version of this document is available. Customers should click here to go to the newest version.
oneVPL Architecture
The following scheme summarizes oneVPL architecture and illustrates the linking between various levels:
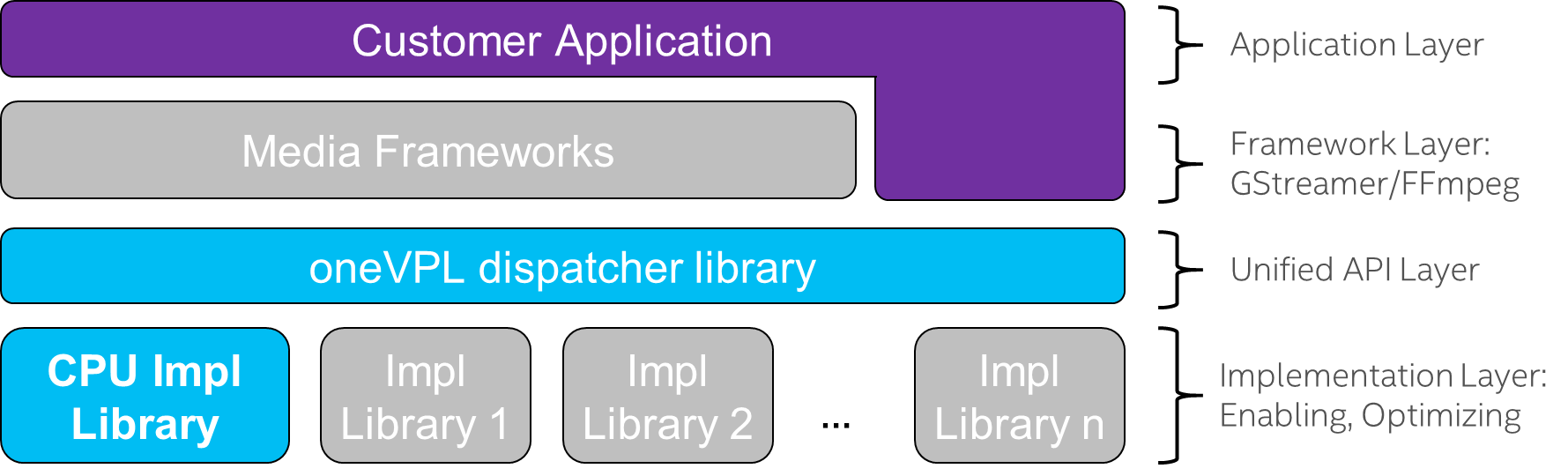
The sections below offer more details.
Linking
Applications link to the dispatcher instead of directly linking to an implementation library.
The dynamic loading of the dispatcher allows the application to choose between many library implementations to load at runtime and route API calls to the chosen implementation.
Library Implementations
Different implementations for different hardware
Different library implementations can target different hardware, which allows each implementation to map hardware capabilities to the oneVPL API.
On the diagram above, the available libraries could be designed for different generations of GPUs as well as other hardware types. This design means that you can write an application using the API that will work on many hardware types, even though the code that implements the API functions in each of these libraries is very different.
This allows applications to focus on functionality instead of maintaining multiple device-specific code pathways. It also future-proofs the application code since new hardware can be enabled by adding another implementation library without changes to the application code.
Different implementations for the same hardware
In some cases, a single hardware type can have multiple API implementations.
For Intel GPUs, the legacy Intel® Media SDK implementation provides access to legacy GPU hardware acceleration, while the oneVPL implementation enables newer hardware. Both oneVPL and Intel® Media SDK implementations are included in the GPU runtime packages. Legacy Intel® Media SDK GPU implementations are most widely available today.
Where multiple implementations for a hardware type are available, the dispatcher determines which one to load based on the runtime environment.