Multiplying Matrices Using dgemm
oneMKL provides several routines for multiplying matrices. The most widely used is the dgemm routine, which calculates the product of double precision matrices:
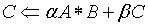
The dgemm routine can perform several calculations. For example, you can perform this operation with the transpose or conjugate transpose of A and B. The complete details of capabilities of the dgemm routine and all of its arguments can be found in the cblas_?gemm topic in the Intel® oneAPI Math Kernel Library Developer Reference.
Use dgemm to Multiply Matrices
This exercise demonstrates declaring variables, storing matrix values in the arrays, and calling dgemm to compute the product of the matrices. The arrays are used to store these matrices:
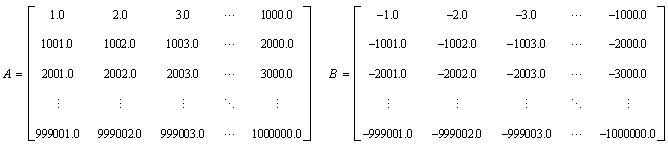
The one-dimensional arrays in the exercises store the matrices by placing the elements of each column in successive cells of the arrays.
The C source code for the exercises in this tutorial can be downloaded from mkl-cookbook-samples-120115.zip.
/* C source code is found in dgemm_example.c */
#define min(x,y) (((x) < (y)) ? (x) : (y))
#include <stdio.h>
#include <stdlib.h>
#include "mkl.h"
int main()
{
double *A, *B, *C;
int m, n, k, i, j;
double alpha, beta;
printf ("\n This example computes real matrix C=alpha*A*B+beta*C using \n"
" Intel(R) MKL function dgemm, where A, B, and C are matrices and \n"
" alpha and beta are double precision scalars\n\n");
m = 2000, k = 200, n = 1000;
printf (" Initializing data for matrix multiplication C=A*B for matrix \n"
" A(%ix%i) and matrix B(%ix%i)\n\n", m, k, k, n);
alpha = 1.0; beta = 0.0;
printf (" Allocating memory for matrices aligned on 64-byte boundary for better \n"
" performance \n\n");
A = (double *)mkl_malloc( m*k*sizeof( double ), 64 );
B = (double *)mkl_malloc( k*n*sizeof( double ), 64 );
C = (double *)mkl_malloc( m*n*sizeof( double ), 64 );
if (A == NULL || B == NULL || C == NULL) {
printf( "\n ERROR: Can't allocate memory for matrices. Aborting... \n\n");
mkl_free(A);
mkl_free(B);
mkl_free(C);
return 1;
}
printf (" Intializing matrix data \n\n");
for (i = 0; i < (m*k); i++) {
A[i] = (double)(i+1);
}
for (i = 0; i < (k*n); i++) {
B[i] = (double)(-i-1);
}
for (i = 0; i < (m*n); i++) {
C[i] = 0.0;
}
printf (" Computing matrix product using Intel(R) MKL dgemm function via CBLAS interface \n\n");
cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
m, n, k, alpha, A, k, B, n, beta, C, n);
printf ("\n Computations completed.\n\n");
printf (" Top left corner of matrix A: \n");
for (i=0; i<min(m,6); i++) {
for (j=0; j<min(k,6); j++) {
printf ("%12.0f", A[j+i*k]);
}
printf ("\n");
}
printf ("\n Top left corner of matrix B: \n");
for (i=0; i<min(k,6); i++) {
for (j=0; j<min(n,6); j++) {
printf ("%12.0f", B[j+i*n]);
}
printf ("\n");
}
printf ("\n Top left corner of matrix C: \n");
for (i=0; i<min(m,6); i++) {
for (j=0; j<min(n,6); j++) {
printf ("%12.5G", C[j+i*n]);
}
printf ("\n");
}
printf ("\n Deallocating memory \n\n");
mkl_free(A);
mkl_free(B);
mkl_free(C);
printf (" Example completed. \n\n");
return 0;
}
This exercise illustrates how to call the dgemm routine. An actual application would make use of the result of the matrix multiplication.
This call to the dgemm routine multiplies the matrices:
cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
m, n, k, alpha, A, k, B, n, beta, C, n);
The arguments provide options for how oneMKL performs the operation. In this case:
- CblasRowMajor
-
Indicates that the matrices are stored in row major order, with the elements of each row of the matrix stored contiguously as shown in the figure above.
- CblasNoTrans
-
Enumeration type indicating that the matrices A and B should not be transposed or conjugate transposed before multiplication.
- m, n, k
-
Integers indicating the size of the matrices:
A: m rows by k columns
B: k rows by n columns
C: m rows by n columns
- alpha
-
Real value used to scale the product of matrices A and B.
- A
-
Array used to store matrix A.
- k
-
Leading dimension of array A, or the number of elements between successive rows (for row major storage) in memory. In the case of this exercise the leading dimension is the same as the number of columns.
- B
-
Array used to store matrix B.
- n
-
Leading dimension of array B, or the number of elements between successive rows (for row major storage) in memory. In the case of this exercise the leading dimension is the same as the number of columns.
- beta
-
Real value used to scale matrix C.
- C
-
Array used to store matrix C.
- n
-
Leading dimension of array C, or the number of elements between successive rows (for row major storage) in memory. In the case of this exercise the leading dimension is the same as the number of columns.
Compile and Link Your Code
oneMKL provides many options for creating code for multiple processors and operating systems, compatible with different compilers and third-party libraries, and with different interfaces. To compile and link the exercises in this tutorial with Intel® Parallel Studio XE Composer Edition, type
- Windows* OS: icl /Qmkl src\dgemm_example.c
- Linux* OS, macOS*: icc -mkl src/dgemm_example.c
Alternatively, you can use the supplied build scripts to build and run the executables.
- Windows* OS:
build build run_dgemm_example
- Linux* OS, macOS*:
make make run_dgemm_example
For the executables in this tutorial, the build scripts are named:
Example |
Executable |
|---|---|
dgemm_example.c |
run_dgemm_example |
dgemm_with_timing.c |
run_dgemm_with_timing |
matrix_multiplication.c |
run_matrix_multiplication |
dgemm_threading_effect_example.c |
run_dgemm_threading_effect_example |
This assumes that you have installed oneMKL and set environment variables as described in .
For other compilers, use the oneMKL Link Line Advisor to generate a command line to compile and link the exercises in this tutorial: http://software.intel.com/en-us/articles/intel-mkl-link-line-advisor/.
After compiling and linking, execute the resulting executable file, named dgemm_example.exe on Windows* OS or a.out on Linux* OS and macOS*.
Product and Performance Information |
|---|
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex. Notice revision #20201201 |