A newer version of this document is available. Customers should click here to go to the newest version.
Distributed DFT
Starting from Intel® oneAPI Math Kernel Library (oneMKL) 2025.2 release, a DPC++ interface for computing Distributed Discrete Fourier Transforms is introduced. This is designed to perform FFTs on a collection (single or multi mode) of SYCL GPU devices, where each individual GPU device is accessible within its respective process. To organize communication between different processes, the interface uses the Message Passing Interface (MPI). This interface declares the oneapi::mkl::experimental::dft namespace, which contains
the scoped enumerations oneapi::mkl::experimental::dft::distributed_config_param and oneapi::mkl::experimental::dft::distributed_config_value;
the oneapi::mkl::experimental::dft::distributed_descriptor class template;
the oneapi::mkl::experimental::dft::compute_forward and oneapi::mkl::experimental::dft::compute_backward function templates.
This new interface closely resembles the single process DPC++ interface and thus re-uses the scoped enumerations defined in the oneapi::mkl::dft namespace for configuring and executing a DFT distributed across multiple processes. For a DFT of forward domain and floating-point format represented by the values dom and prec (known at compile time) of respective types oneapi::mkl::dft::domain and oneapi::mkl::dft::precision (see the scoped enumerations), the desired global transform and its general configuration are to be communicated uniformly across each process via an object of the oneapi::mkl::experimental::dft::distributed_descriptor<prec, dom> class. Once successfully committed across all the involved processes to the desired DFT configuration and to a user-provided local sycl::queue instance, that oneapi::mkl::experimental::dft::distributed_descriptor object can be used as an argument to the appropriate compute function(s) along with the relevant local chunks of input and output data.
The distributed DFT DPC++ interface computes a DFT in five steps:
Each process creates a oneapi::mkl::experimental::dft::distributed_descriptor object dist_desc for the targeted global DFT problem with a call to the relevant parameterized constructor, e.g.,
distributed_descriptor<prec, dom> dist_desc(MPI_COMM_WORLD, lengths);
wherein prec and dom are specialization values of types oneapi::mkl::dft::precision and oneapi::mkl::dft::domain, respectively. dist_desc captures the configuration of the global transform, such as the dimensionality (or rank), length(s), number of transforms, layout of the input and output data (defined by strides, distances, and possibly other configuration parameters), scaling factors, etc. All the configuration settings are assigned default values in this call, which might need to be modified thereafter.
By default, distributed_descriptor objects within each process are initialized for the in-place calculation of an unbatched (
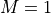 ), unscaled (
), unscaled (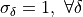 ) global DFT of the forward domain, precision and length(s) set at construction.
) global DFT of the forward domain, precision and length(s) set at construction.Optionally adjust the configuration of dist_desc by calling its relevant configuration-setting member function(s) as many times as needed including the data distribution configuration. The value associated with (almost) any configuration parameter can be obtained with the appropriate configuration-querying member function(s) (default values are returned unless the queried configuration parameter was previously set). The configurations defining the global transform must be set uniform across all processes, otherwise the behavior is undefined(except for the custom distribution configuration).
Commit dist_desc with a call to its commit member function; that is, make the object ready to compute the global transform. All the dist_desc objects across the processes need to be successfully committed for performing the global transform. Once the objects are committed, the configuration parameters of the global DFT, are considered frozen for computation purposes: changing any of them after committing the object effectively invalidates it for computation purposes until the commit member function is called again. The commit member function takes in a sycl::queue object which is built upon the sycl::device object which is mapped to a physical device by MPI.
Use the committed dist_desc to query the local size of the device memory allocations needed for the respective domain(forward or backward) within each process and initialize the input data. The configuration-querying member function can be used to achieve this.
Use the committed dist_desc to call the (appropriate) oneapi::mkl::experimental::dft::compute_forward or oneapi::mkl::experimental::dft::compute_backward functions as needed to compute the desired global transform(s). These functions require no other argument than a committed distributed descriptor object and the device-accessible input and output data.
Supported functionality and limitations
-
- Only 2D and 3D transforms are supported, with the following limitations,
-
The dimensions must have length greater than or equal to the number of processes.
Batching is not supported.
Only default packed layouts are supported.
Supports Intel® Data Center GPU Max Series device only.
All the processes must be provided the same MPI communicator.
Currently only supports Intel® MPI.
The environment variable I_MPI_OFFLOAD must be set to 1 to be functional; otherwise, an exception will be thrown.