A newer version of this document is available. Customers should click here to go to the newest version.
Using Performance Libraries
This section discusses using efficient functions from libraries like oneAPI Math Kernel Library (oneMKL) or oneAPI Deep Neural Network Library (oneDNN) instead of hand-coded alternatives. Unless you’re an expert studying a particular mathematical operation, it’s usually a bad idea to write your own version of that operation. For example, matrix multiplication is a common, straightforward mathematical operation:
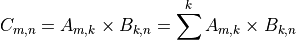
It’s also easy to implement with just a few lines of code:
// Multiply matrices A and B
for (m = 0; m < M; m++) {
for (n = 0; n < N; n++) {
C[m][n] = 0.0;
for (k = 0; k < K; k++) {
C[m][n] += A[m][k] * B[k][n];
}
}
} // End matrix multiplication
However, this naive implementation won’t give the best possible performance. Simple visual inspection of the inner loop shows non-contiguous memory access for matrix B. Cache reuse, and hence performance, will be poor.
It’s not difficult to port the naive algorithm to SYCL to offload the matrix multiplication kernel to an accelerator. The following code initializes the queue to submit work to the default device and allocates space for the matrices in unified shared memory (USM):
// Initialize SYCL queue
sycl::queue Q(sycl::default_selector_v);
auto sycl_device = Q.get_device();
auto sycl_context = Q.get_context();
std::cout << "Running on: "
<< Q.get_device().get_info<sycl::info::device::name>() << std::endl;
// Allocate matrices A, B, and C in USM
auto A = sycl::malloc_shared<float *>(M, sycl_device, sycl_context);
for (m = 0; m < M; m++)
A[m] = sycl::malloc_shared<float>(K, sycl_device, sycl_context);
auto B = sycl::malloc_shared<float *>(K, sycl_device, sycl_context);
for (k = 0; k < K; k++)
B[k] = sycl::malloc_shared<float>(N, sycl_device, sycl_context);
auto C = sycl::malloc_shared<float *>(M, sycl_device, sycl_context);
for (m = 0; m < M; m++)
C[m] = sycl::malloc_shared<float>(N, sycl_device, sycl_context);
// Initialize matrices A, B, and C
Data in USM can be moved between host and device memories by the SYCL runtime. Explicit buffering is not required. To offload the computation to the default accelerator, it is converted to a SYCL kernel and submitted to the queue:
// Offload matrix multiplication kernel
Q.parallel_for(sycl::range<2>{M, N}, [=](sycl::id<2> id) {
unsigned int m = id[0];
unsigned int n = id[1];
float sum = 0.0;
for (unsigned int k = 0; k < K; k++)
sum += A[m][k] * B[k][n];
C[m][n] = sum;
}).wait(); // End matrix multiplication
However, simply offloading such code to an accelerator is unlikely to restore performance. In fact, performance could get worse. Badly written code is still badly written whether it runs on the host or a device.
Common, computationally demanding operations like matrix multiplication are well-studied. Experts have devised a number of algorithms that give better performance than naive implementations of the basic mathematical formulas. They also use tuning techniques like cache blocking and loop unrolling to achieve performance regardless of the shapes of matrices A and B.
oneMKL provides an optimized general matrix multiplication function (oneapi::mkl::blas::gemm) that gives high performance on the host processor or a variety of accelerator devices. The matrices are allocated in USM as before, and passed to the gemm function along with the device queue, matrix dimensions, and various other options:
// Offload matrix multiplication
float alpha = 1.0, beta = 0.0;
oneapi::mkl::transpose transA = oneapi::mkl::transpose::nontrans;
oneapi::mkl::transpose transB = oneapi::mkl::transpose::nontrans;
sycl::event gemm_done;
std::vector<sycl::event> gemm_dependencies;
gemm_done = oneapi::mkl::blas::gemm(Q, transA, transB, M, N, K, alpha, A, M,
B, K, beta, C, M, gemm_dependencies);
gemm_done.wait();
The library function is more versatile than the naive implementations and is expected to give better performance. For example, the library function can transpose one or both matrices before multiplication, if necessary. This illustrates the separation of concerns between application developers and tuning experts. The former should rely on the latter to encapsulate common computations in highly-optimized libraries. The oneAPI specification defines many libraries to help create accelerated applications, e.g.:
oneMKL for math operations
oneDAL for data analytics and machine learning
oneDNN for the development of deep learning frameworks
Intel VPL for video processing
Check whether your required operation is already available in a oneAPI library before creating your own implementation of it.