A newer version of this document is available. Customers should click here to go to the newest version.
Getting Started
Three key concepts govern software optimization for an accelerator. These concepts should guide your optimization efforts.
Amdahl’s Law
This may appear obvious, but it is the first step in making use of an accelerator. Amdahl’s law states that the fraction of time an application uses an accelerator (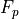 ) limits the benefit of acceleration. The maximum speedup is bounded by
) limits the benefit of acceleration. The maximum speedup is bounded by 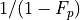 . If you use the accelerator
. If you use the accelerator 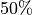 of the time, you will get at most a
of the time, you will get at most a 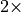 speedup, even with an infinitely powerful accelerator.
speedup, even with an infinitely powerful accelerator.
Note here that this is in terms of your program execution, not your program’s source code. The parallel kernels may represent a very small fraction of your overall source code, but if this is where you execution time is concentrated, you can still do well.
Locality
An accelerator often has specialized memory with a disjoint address space. An application must allocate or move data into the right memory at the right time.
Accelerator memory is arranged in a hierarchy. Registers are more efficient to access than caches, and caches are more efficient to access than main memory. Bringing data closer to the point of execution improves efficiency.
There are many ways you can refactor your code to get your data closer to the execution. They will be outlined in the following sections. Here, we focus on three:
Allocate your data on the accelerator, and when copied there, keep it resident for as long as possible. Your application may have many offloaded regions. If you have data that is common between these regions, it makes sense to amortize the cost of the first copy, and just reuse it in place for the remaining kernel invocations.
Access contiguous blocks of memory as your kernel executes. The hardware will fetch contiguous blocks into the memory hierarchy, so you have already paid the cost for the entire block. After you use the first element of the block, the remaining elements are almost free to access so take advantage of it.
Restructure your code into blocks with higher data reuse. In a two-dimensional matrix, you can arrange your work to process one block of elements before moving onto the next block of elements. For example, in a stencil operation you may access the prior row, the current row, and the next row. As you walk over the elements in a block you reuse the data and avoid the cost of requesting it again.
Work Size
Data-parallel accelerators are designed as throughput engines and are often specialized by replicating execution units many times. This is an easy way of getting higher performance on data-parallel algorithms since more of the elements can be processed at the same time.
However, fully utilizing a parallel processor can be challenging. For example, imagine you have 512 execution units, where each execution unit had eight threads, and each thread has 16-element vectors. You need to have a minimum of 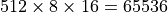 parallel activities scheduled at all times just to match this capacity. In addition, if each parallel activity is small, you need another large factor to amortize the cost of submitting this work to the accelerator. Fully utilizing a single large accelerator may require decomposing a computation into millions of parallel activities.
parallel activities scheduled at all times just to match this capacity. In addition, if each parallel activity is small, you need another large factor to amortize the cost of submitting this work to the accelerator. Fully utilizing a single large accelerator may require decomposing a computation into millions of parallel activities.