Intel® oneAPI DPC++/C++ Compiler Developer Guide and Reference
A newer version of this document is available. Customers should click here to go to the newest version.
Intel® C++ Class Libraries
The Intel® C++ Class Libraries enable Single-Instruction, Multiple-Data (SIMD) operations. The principle of SIMD operations is to exploit microprocessor architecture through parallel processing. The effect of parallel processing is increased data throughput using fewer clock cycles. The objective is to improve application performance of complex and computation-intensive audio, video, and graphical data bit streams.
Hardware and Software Requirements
The Intel® C++ Class Libraries are functions abstracted from the instruction extensions available on Intel® processors.
Details About the Libraries
The Intel® C++ Class Libraries for SIMD Operations provide a convenient interface to access the underlying instructions for processors as specified above. These processor-instruction extensions enable parallel processing using the single instruction-multiple data (SIMD) technique as illustrated in the following figure.
SIMD Data Flow
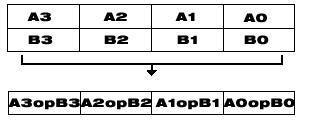
Performing four operations with a single instruction improves efficiency by a factor of four for that particular instruction.
These new processor instructions can be implemented using assembly inlining, intrinsics, or the C++ SIMD classes. Compare the coding required to add four 32-bit floating-point values, using each of the available interfaces:
Comparison Between Inlining, Intrinsics, and Class Libraries
The table below shows an addition of four single-precision floating-point values using assembly inlining, intrinsics, and the libraries. You can see how much easier it is to code with the Intel C++ SIMD Class Libraries. Besides using fewer keystrokes and fewer lines of code, the notation is like the standard notation in C++, making it much easier to implement over other methods.
Assembly Inlining |
Intrinsics |
SIMD Class Libraries |
|---|---|---|
... __m128 a,b,c; __asm{ movaps xmm0,b movaps xmm1,c addps xmm0,xmm1 movaps a, xmm0 } ... |
#include <xmmintrin.h> ... __m128 a,b,c; a = _mm_add_ps(b,c); ... |
#include <fvec.h> ... F32vec4 a,b,c; a = b +c; ... |