Intel MKL 11.3 has introduced Intel TBB support.
Intel MKL 11.3 can increase performance of applications threaded using Intel TBB. Applications using Intel TBB can benefit from the following Intel MKL functions:
- BLAS :
- all level 3 functions
- ?axpy, ?dot, ?gemv
- LAPACK - ?getrf, ?getrs, ?gesv, ?potrf, ?potrs, ?gelqf, ?geqrf, ?ormlq,?unmlq, ?ormrq, ?unmrq, ?sytrd, ?hetrd, ?latrd, ?bdsqr, ?syev, ?gels
- Sparse BLAS - Sparse BLAS - mkl_sparse_mv, mkl_sparse_?trsv, mkl_sparse_convert_csr and mkl_sparse_convert_bsr.
- Sparse Solvers:
- Intel MKL Pardiso ( reordering and factorization steps)
- Added support of Intel TBB threading support for Intel MKL Pardiso at the solving step ( note: available since MKLv.2017 update 2)
- Fast Poisson Solver
- Vector Mathematics
- Added Intel TBB threading support for all mathematical functions (note: available since MKL v. 2017 update 2)
- Data Fitting and Vector Statistics
- Introduced Introduced TBB-threading layer in MKL Data Fitting and Vector Statistics components ( note: available since MKL v.2018)
Other Intel MKL 11.3 functions execute sequential code, but may benefit as well if internally call a function from the list above. Depending on feedback from customers, future versions of Intel MKL may support Intel TBB in more functions.
Linking applications to Intel TBB and Intel MKL
The simplest way to link applications to Intel TBB and Intel MKL is to use Intel C/C++ Compiler. While Intel MKL supports static and dynamic linking, only dynamic Intel TBB library is available.
Under Linux, use the following commands to compile your application app.c and link it to Intel TBB and Intel MKL.
Dynamic Intel TBB, dynamic Intel MKL icc app.c -mkl -tbb
Dynamic Intel TBB, static Intel MKL icc app.c -static -mkl -tbb
Under Windows, use the following commands to compile your application app.c and link it to dynamic Intel TBB and Intel MKL.
Dynamic Intel TBB, dynamic Intel MKL icl.exe app.c -mkl -tbb
Improving Intel MKL performance with Intel TBB
Performance of Intel MKL can be improved by telling Intel TBB to ensure thread affinity to processor cores. Use the tbb::affinity_partitioner class to this end.
To improve performance of Intel MKL for small input data, you may limit the number of threads allocated by Intel TBB for Intel MKL. Use the tbb::task_scheduler_init class to do so.
For more information on controlling behavior of Intel TBB, see the Intel TBB documentation.
LAPACK (LU factorization ) performance in applications using Intel TBB and Intel MKL 11.3
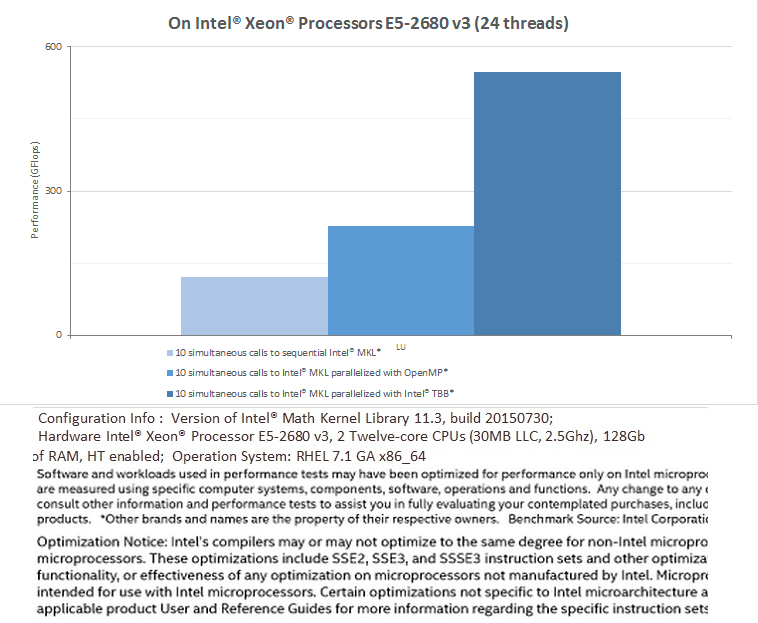
For more information about Using Intel® MKL with Threaded Applications, please refer to the Knowledge Base Article follow the link: /content/www/us/en/develop/articles/intel-math-kernel-library-intel-mkl-using-intel-mkl-with-threaded-applications.html or to the MKL User's Guide
* Each call is single run of single size on range from 1000 to 10000 with step 1000. Performance (GFlops) is computed as cumulative number of floating point operations for all 10 calls divided by wall clock time from starting very first call till finishing very last call.
** ? indicates the data types:
s - real, single precision
c - complex, single precision
d - real, double precision
z - complex, double precision