This article is part one of three articles to introduce the reader to persistent memory.
- Learn More Part 1 - Introduction
- Learn More Part 2 - Persistent Memory Architecture
- Learn More Part 3 - Operating System Support for Persistent Memory
Note: This article will be making references to chapters within the Programming Persistent Memory ebook on pmem.io
Persistent Memory Learn More Series
For many years computer applications organized their data between two tiers: memory and storage. The new generation of Intel's persistent memory is based on Intel® Optane™ technology, has introduced an additional tier in the memory and storage hierarchy.
In this series, we will learn about the technology, how it is exposed to applications, and why there is so much excitement around enabling applications to utilize persistent memory.
Persistent memory technology has the attributes of both storage and memory. It is persistent, like storage, meaning they hold their content across power cycles, and they are byte-addressable, like memory, meaning programs can access data structures in place.
What makes Intel persistent memory technology stand out is that it's fast enough for the processor to access directly without stopping to do the block I/O required for traditional storage.
Additional Resources
Why should we use PMem?
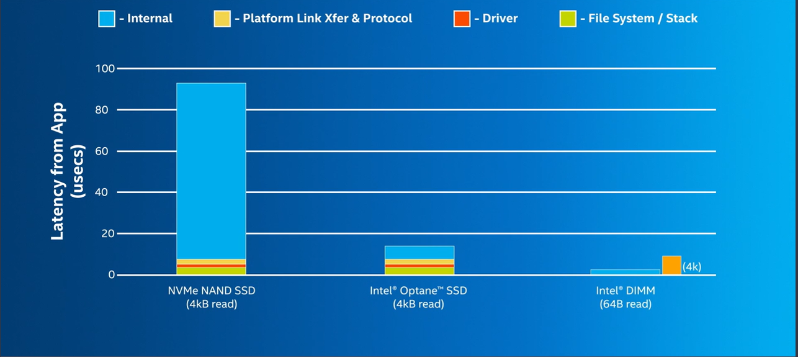
The main reason for the excitement around persistent memory is the ability to provide improved performance over existing storage devices. If you compare a modern NAND-based SSD (PCIe) and Intel Optane storage solutions, you find most of the time spent accessing the media, while the software stack latencies are minimal.
The PMem Architecture
PMem resides on the memory bus by using DDR slots so the CPU can access the data directly, without any driver or PCIe overhead. Since memory is accessed in 64-byte cache lines, it is more efficient, as the CPU reads what it needs to read instead of rounding every access up to block size, like storage. In Figure 1, you can see how low latency a 64-byte read is compared with traditional block storage NVMe SSDs.
With persistent memory, applications now have a new tier available for data placement. In addition to the memory and storage tiers, the persistent memory tier offers greater capacity than DRAM and significantly faster performance than storage. Applications access persistent memory-resident data structures in place, as they do with traditional memory, eliminating the need to page blocks of data back and forth between memory and storage.
The Non-Volatile Memory (NVM) Programming Model
The storage stack is shown in Figure 2 at a very high level. These basic blocks that make up the stack haven't changed much over decades of use. Applications use standard file APIs to open files on a file system, and the file system does block I/O as necessary through a driver or set of drivers. All accesses to the storage happens in blocks, typically over an interconnect like PCIe.
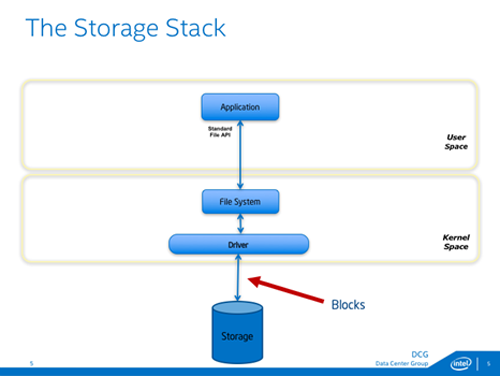
From an operating system perspective, support for basic file APIs like open/close and read/write have existed for a few decades. Developers writing applications in higher-level languages may be programming with libraries that provide more convenient APIs. Those libraries will eventually call these APIs internally.
Memory Mapping
Both Microsoft Windows and Linux support memory-mapped files, a feature that has been around for a long time but is not commonly used. For persistent memory, the APIs for memory mapping files are very useful; in fact, they are at the heart of the persistent memory programming model published by the Storage Networking Industry Association (SNIA).
Memory mapping a file is only allowed after the file is already opened. The permission checks have already happened when an application calls CreateFileMapping and MapViewOfFile on Windows or mmap on Linux.
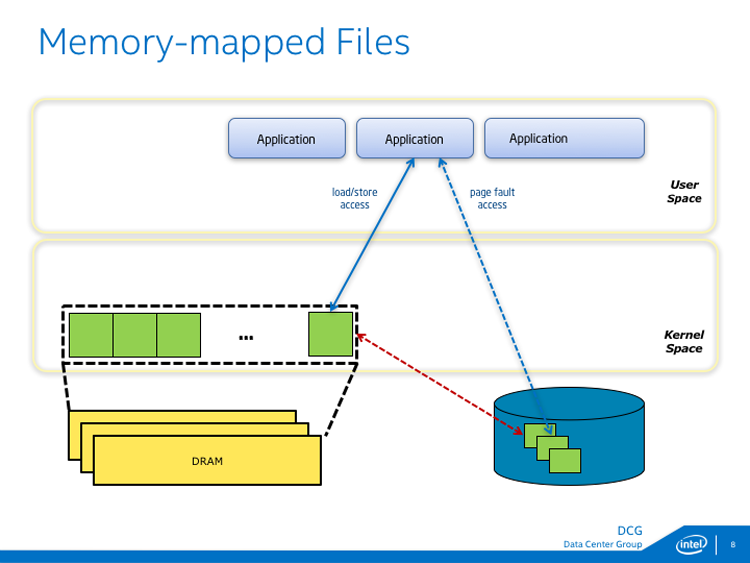
Once those calls are made, the file appears in the application's address space, allowing load/store access to the file contents. An important aspect of memory-mapped files is that changes done by store instructions are not guaranteed to be persistent until they are flushed to storage. On Windows, use FlushViewOfFile and FlushFileBuffers. On Linux use msync or fsync.
This is where the power of the memory-mapped file API benefits persistent memory programming.
- The goal of this article is to introduce Optane PMem modes. Concepts like memory mapping, persistence, transactional operations, PMem errors are different from memory errors, RAS, why do we need PMDK, what is PMDK, and then Call to Action to get them started by going to "Get Started Page."
Transactional Operations
Combining multiple operations into a single atomic operation is usually referred to as a transaction. In the database world, the acronym ACID describes the properties of a transaction: atomicity, consistency, isolation, and durability
Atomicity
As described earlier, atomicity is when multiple operations are composed into a single atomic action that either happens entirely or does not happen even in system failure. For persistent memory, the most common techniques used are
- Redo logging, where the full change is first written to a log, so it can be rolled forward during recovery if interrupted.
- Undo logging, where information is logged, allowing a partially done change to be rolled back during recovery.
- Atomic pointer updates, where a change is made active, update a single pointer atomically, usually changing it from pointing to old data to new data. The preceding list is not exhaustive, and it ignores the details that can get relatively complex. One common consideration is that transactions often include memory allocation/deallocation. For example, a transaction that adds a node to a tree data structure usually includes allocating the new node. If the transaction is rolled back, the memory must be freed to prevent a memory leak. Now imagine a transaction that performs multiple persistent memory allocations and free operations, all of which must be part of the same atomic operation. The implementation of this transaction is more complicated than just writing the new value to a log or updating a single pointer
Consistency
Consistency means that a transaction can only move a data structure from one valid state to another. Programmers usually find that the locking they use to make updates thread-safe often indicates consistency points for persistent memory. If it is not valid for a thread to see an intermediate state, locking prevents it from happening, and when it is safe to drop the lock, that is because it is safe for another thread to observe the current state of the data structure.
Isolation
Multithreaded (concurrent) execution is commonplace in modern applications. When making transactional updates, the isolation allows the concurrent updates to have the same effect as if they were executed sequentially. At runtime, isolation for persistent memory updates is typically achieved by locking. Since the memory is persistent, the isolation must be considered for transactions in-flight when the application was interrupted. Persistent memory programmers typically detect this situation on restart and roll partially done transactions forward or backward appropriately before allowing general-purpose threads access to the data structures.
Durability
A transaction is considered durable if it is on persistent media when it is complete. Even if the system loses power or crashes at that point, the transaction remains completed. As described in Chapter 2, this usually means the changes must be flushed from the CPU caches. This can be done using standard APIs, such as the Linux msync() call, or platform-specific instructions such as Intel's CLWB. When implementing transactions on persistent memory, pay careful attention to ensure that log entries are flushed to persistence before changes are started and flush changes to persistence before a transaction is considered complete. Another aspect of the durable property is the ability to find persistent information again when an application starts up. This is so fundamental to how storage works that we take it for granted. Metadata such as file names and directory names are used to find the durable state of an application on storage. The same is true for persistent memory due to the programming model described in Chapter 3, where persistent memory is accessed by first opening a file on direct access (DAX) file system and then memory mapping that file. However, a memory-mapped file is just a range of raw data; Chapter 4 Fundamental Concepts of Persistent Memory Programming, how does the application find the data structures resident in that range? At least one well-known location of a data structure must be used as a starting point for persistent memory. This is often referred to as a root object (described in Chapter 7). The root object is used by many of the higher-level libraries within PMDK to access the data.
Persistence
Use cases that take advantage of persistent memory for persistence, as opposed to the volatile use cases previously described, are generally replacing slower storage devices with persistent memory. Determining the suitability of a workload for this use case is straightforward. If application performance is limited by storage accesses (disks, SSDs, etc.), then using a faster storage solution like persistent memory could help. There are several ways to identify storage bottlenecks in an application. Open source tools like dstat or iostat give a high-level overview of disk activity, and tools such as VTune Profiler provide a more detailed analysis.
Reliability, Availability, and Serviceability (RAS)
This chapter describes the high-level architecture of reliability, availability, and serviceability (RAS) features designed for persistent memory. Persistent memory RAS features were designed to support an application's unique error-handling strategy when persistent memory is used. Error handling is an integral part of the program's overall reliability, directly affecting applications' availability. The error-handling strategy for applications impacts what percentage of the expected time the application is available to do its job. Persistent memory vendors and platform vendors will decide which RAS features and how they will be implemented at the lowest hardware levels. Some common RAS features were designed and documented in the ACPI specification, maintained and owned by the UEFI Forum (https://uefi.org/). In this chapter, we try to attain a general perspective of these ACPI-defined RAS features and call out vendor-specific details if warranted.
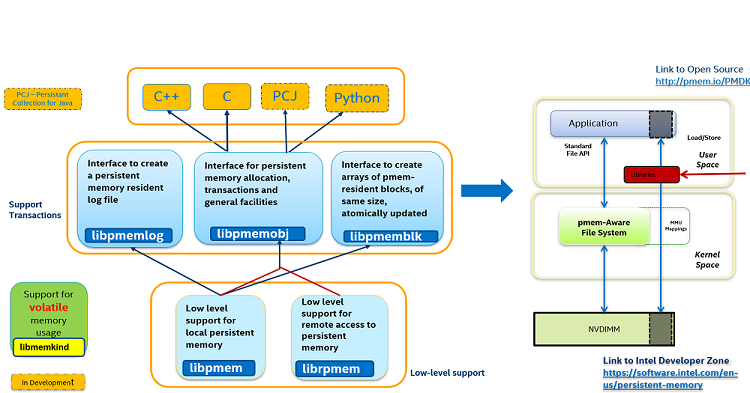
The persistent memory programming model allows byte-level access to non-volatile media plugged into the memory bus, shown here by the common industry term NVDIMM, which is short for non-volatile dual in-line memory module. You can see that once the mappings are created, the application has direct access, provided by the MMU's virtual-to-physical mappings. The ability to configure these direct mappings to persistent memory is a feature known as direct access (DAX). Support for this feature is what differentiates a typical file system from a persistent memory-aware file system. DAX is supported today by both Windows and Linux.
Introduction to the Persistent Memory Development Kit (PMDK)
PMDK is a collection of open-source libraries and tools that are available today for both Linux and Windows. For more information, please visit pmem.io, the Persistent Memory Programming web site. PMDK facilitates persistent memory programming adoption with higher-level language support. C and C++ support are currently fully validated and delivered on Linux and available as early access on Windows.
Conclusion
Persistent memory is a game-changer, and the programming model described here provides access to this emerging technology. PMDK Libraries provide support for transactional operations to keep the data consistent and durable. There are still many unknowns, and there continues to be a lot of exciting work in this field.
To learn more, check out the Persistent Memory Programming video series.