This information was first published on GitHub*.
Deploy Distributed LLMs with Intel® Xeon® Scalable Processors on Microsoft Azure
This article resumes where the previous article, Part 1: Fine-tune nanoGPT in a Distributed Architecture on Microsoft Azure* Cloud, concluded after fine-tuning the nanoGPT model on a single node. In the previous article, we also set up an Azure trusted virtual machine (VM) using an instance from the Dv5 series. Additionally, we created a virtual network and established a permissive network security group that is used to enable seamless communication between the instances in the cluster.
In Part 2, we set up the multi-CPU environment and fine-tune the nanoGPT model in a distributed system using three nodes.
To fine-tune nanoGPT in a multi-CPU environment, we begin by preparing a new accelerate configuration file. Before setting up this environment, make sure you have your machine's private IP address on hand. To obtain it, run the following command:
hostname -i
With the private IP address of your virtual machine ready, to generate the new accelerate configuration file for the multi-CPU environment, run the following command:
accelerate config --config_file ./multi_config.yaml
This generates a new configuration file named multi_config.yaml in your current working directory. When configuring the multi-CPU set up using accelerate config, you are prompted with several questions. Following are the prompts and responses to set up your distributed environment:
In which compute environment are you running?
This machine
Which type of machine are you using?
multi-CPU
How many different machines will you use (use more than 1 for multi-node training)? [1]: 3
What is the rank of this machine?
0
What is the IP address of the machine that will host the main process? 10.0.xx.xx
What is the port you will use to communicate with the main process? 29500
Are all the machines on the same local network? Answer `no` if nodes are on the cloud and/or on different network hosts [YES/no]: no
What rendezvous backend will you use? ('static', 'c10d', ...): static
Do you want to use Intel PyTorch Extension (IPEX) to speed up training on CPU? [yes/NO]: yes
Do you wish to optimize your script with torch dynamo?[yes/NO]: no
How many CPU(s) should be used for distributed training? [1]: 1
Do you wish to use FP16 or BF16 (mixed precision)?
fp16
Note For the rank, since we are initially running this from the master node, enter 0. For each machine, you need to change the rank accordingly. The prompt of How many CPU(s) should be used for distributed training refers to the number of CPU sockets in your machine. Generally, each machine will have only one CPU socket. However, in the case of bare metal instances, you may have two CPU sockets per instance. Modify the number of sockets based on your instance configuration.
Before creating the additional virtual machines for distributed fine-tuning, make sure to first delete the snapshot.pt file. If this file exists, the main.py script resumes training from this snapshot.
rm snapshot.pt
Create Two Additional Azure Virtual Machines for Distributed Fine-tuning
Now we are ready to set up the additional VMs in the cluster for distributed fine-tuning. To ensure a consistent setup across the machines, we create a virtual machine image (VMI) from the operating system disk snapshot. This way we do not generalize the virtual machine currently running.
In a new terminal, create the Azure snapshot of the virtual machine's operating system disk using the following command:
export DISK_NAME=intel-nano-gpt-disk-snapshot
export DISK_SOURCE=$(az vm show -n $VM_NAME -g $RG --query "storageProfile.osDisk.name" -o tsv)
az snapshot create -n $DISK_NAME -g $RG --source $DISK_SOURCE
Then, create an Azure compute gallery to store the virtual machine image definition and image version.
export GALLERY_NAME=intelnanogptgallery
az sig create -g $RG --gallery-name $GALLERY_NAME
Next, create the image definition for our virtual machine instance (VMI) that holds information about the image and the requirements for using it. The image definition that is created with the following command is used to create a generalized Linux* image from the machine's operating system disk.
export IMAGE_DEFINITION=intel-nano-gpt-image-definition
az sig image-definition create -g $RG \
--gallery-name $GALLERY_NAME \
--gallery-image-definition $IMAGE_DEFINITION \
--publisher Other --offer Other --sku Other \
--os-type linux --os-state Generalized
Now we are ready to create the image version using the disk snapshot and image definition we created previously. This command may take a few moments to complete.
export IMAGE_VERSION=1.0.0
export OS_SNAPSHOT_ID=$(az snapshot show -g $RG -n $DISK_NAME --query "creationData.sourceResourceId" -o tsv)
az sig image-version create -g $RG \
--gallery-name $GALLERY_NAME \
--gallery-image-definition $IMAGE_DEFINITION \
--gallery-image-version $IMAGE_VERSION \
--os-snapshot $OS_SNAPSHOT_ID
Once the image version has been created, we can now create two additional virtual machines in our cluster using this version.
export VM_IMAGE_ID=$(az sig image-version show -g $RG --gallery-name $GALLERY_NAME --gallery-image-definition $IMAGE_DEFINITION --gallery-image-version $IMAGE_VERSION --query "id" -o tsv)
az vm create -n intel-nano-gpt-vms \
-g $RG \
--count 2 \
--size $VM_SIZE \
--image $VM_IMAGE_ID \
--admin-username $ADMIN_USERNAME \
--ssh-key-name $SSH_KEY \
--public-ip-sku Standard \
--vnet-name $VNET_NAME \
--subnet $SUBNET_NAME \
--nsg $NETWORK_SECURITY_GROUP \
--nsg-rule SSH
Configure a Passwordless SSH
Next, with the private IP addresses of each of the nodes in the cluster, create an SSH configuration file located at ~/.ssh/config on the master node. The configuration file should look like this:
Host 10.0.xx.xx
StrictHostKeyChecking no
Host node1
HostName 10.0.xx.xx
User azureuser
Host node2
HostName 10.0.xx.xx
User azureuser
StrictHostKeyChecking no disables strict host key checking, and allows the master node to SSH into the worker nodes without prompting for verification.
With these settings, you can check your passwordless SSH by running ssh node1 or ssh node2 to connect to the nodes without any additional prompts.
Next, on the master node, create a host file (~/hosts) that includes the names of all the nodes you want to include in the training process, as defined in the previous SSH configuration. Use localhost for the master node itself as you will launch the training script from the master node. The hosts file looks like this:
localhost
node1
node2
This setup allows you to seamlessly connect to any node in the cluster for distributed fine-tuning.
Fine-tune nanoGPT on Multiple CPUs
Before beginning the fine-tuning process, it is important to update the machine_rank value on each machine. Follow these steps for each worker machine:
- SSH into the worker machine.
- Locate and open the multi_config.yaml file.
- Update the value of the machine_rank variable in the file. Assign the rank to the worker nodes starting from 1.
- For the master node, set the rank to 0.
- For the first worker node, set the rank to 1.
- For the second worker node, set the rank to 2.
- Continue this pattern for additional worker nodes in the cluster.
By updating the machine_rank, you ensure that each machine is correctly identified within the distributed fine-tuning environment. This is crucial to successfully run the fine-tuning process.
To fine-tune PyTorch* models in a distributed setting on Intel hardware, we use the Intel® MPI Library implementation. This implementation provides flexible, efficient, and scalable cluster communication on Intel architecture. The Intel® HPC Toolkit includes all the necessary components, including oneccl_bindings_for_pytorch, which is installed alongside the MPI toolset.
Before launching the fine-tuning process, ensure you have set the environment variables for oneccl_bindings_for_pytorch in each node in the cluster by running the following command:
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
This command sets up the environment variables required for using oneccl_bindings_for_pytorch and enables distributed training using Intel MPI Library.
Note In a distributed setting, mpirun can be used to run any program, not only distributed fine-tuning. It allows you to run parallel applications across multiple nodes or machines using the capabilities of MPI.
Now, run the distributed fine-tuning process. The following command can be used to launch this process:
mpirun -f ~/hosts -n 3 -ppn 1 -genv LD_PRELOAD="/usr/lib/x86_64-linux-gnu/libtcmalloc.so" accelerate launch --config_file ./multi_config.yaml --num_cpu_threads_per_process 16 main.py
Some notes on the arguments for mpirun to consider:
- n: This parameter represents the number of CPUs or nodes. In our case, we specified -n 3 to run on three nodes. Typically, it is set to the number of nodes you are using. However, in the case of bare metal instances with two CPU sockets per board, you would use 2n to account for the two sockets.
- ppn: The process per node (ppn) parameter determines how many training jobs you want to start on each node. We only want one instance of each fine-tuning process to be run on each node, so we set this to -ppn 1.
- genv: This argument allows you to set an environment variable that will be applied to all processes. We used it to set the LD_PRELOAD environment variable to use the libtcmaclloc performance library.
- num_cpu_threads_per_process: The num_cpu_threads_per_process argument specifies the number of CPU threads that PyTorch uses per process. We set this to use 16 threads in our case. When running deep learning tasks, it is best practice to use only the physical cores of your processor, which in our case is 16.
Following is an example of the distributed training final output:
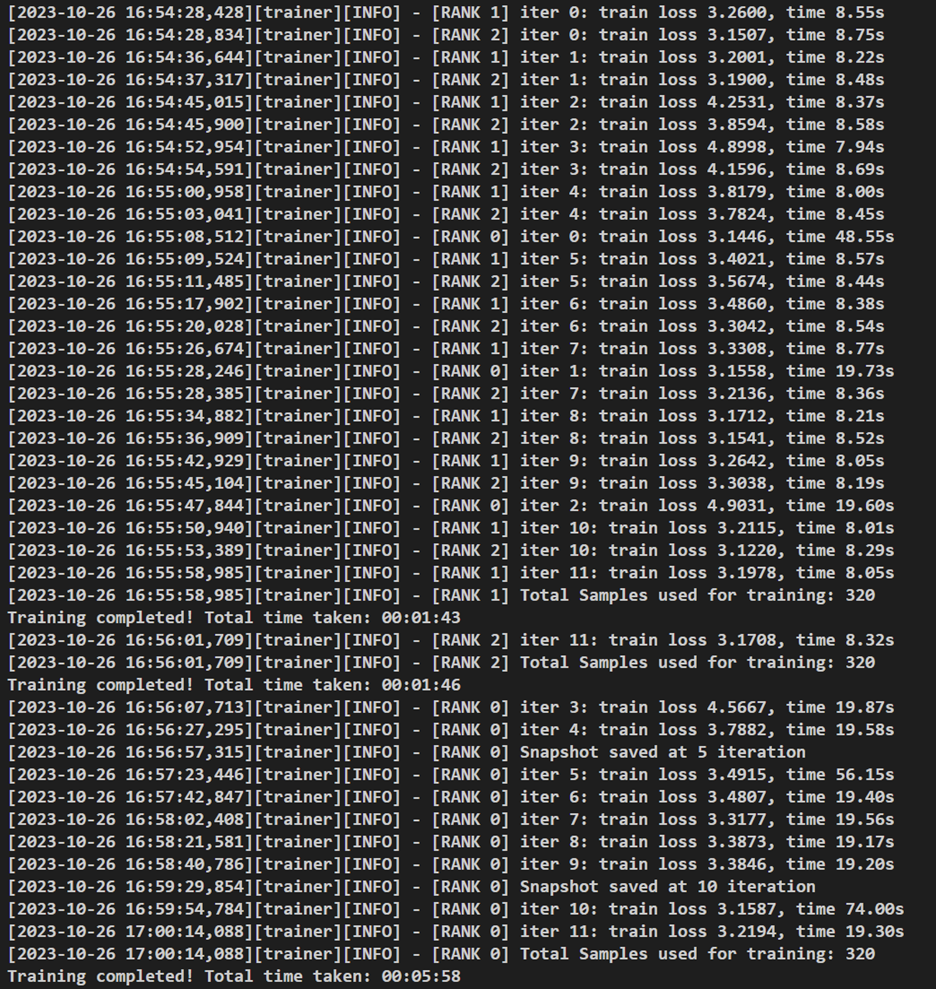
Figure 1. Results of distributed fine-tuning with three nodes
Model Inference
Now that we have fine-tuned the model, let's generate some text using the following command.
python sample.py --ckpt_path=ckpt.pt
The sample.py script is designed to generate sample text containing 100 tokens. By default, the input prompt for generating these samples is the It is interesting prompt. However, you also have the option to specify your own prompt by using the --prompt argument as follows:
python sample.py --ckpt_path=ckpt.pt --prompt="This is a new prompt"
Following is one sample generated text from the It is interesting prompt:
Input Prompt: It is interesting
--------------- Generated Text ---------------
It is interesting to see how many people like this, because I have been listening to and writing about this for a long time.
Maybe I am just a fan of the idea of a blog, but I am talking about this particular kind of fan whose blog is about the other stuff I have like the work of Robert Kirkman and I am sure it is a fan of the work of Robert Kirkman. I thought that was really interesting and I am sure it can be something that I could relate to.
-------------------------------------------
This example illustrates that the language model can generate text, but it is not useful in its current form until fine-tuned for your specific tasks. While there is repetition in the tokens here, this module's primary focus was on the successful distributed training process and using the capabilities of Intel hardware effectively.
Clean up Azure Resources
When you are ready to delete the Azure resources and the resource group, run:
az group delete -n $RG --yes --no-wait
Summary
By adopting distributed training techniques, we have achieved greater data processing efficiency. In approximately six minutes, we processed three times the amount of data as compared to non-distributed training methods. Additionally, we get a lower loss value indicating better model generalization. This performance boost and generalization enhancement is a testament to the advantages of using distributed architectures for fine-tuning LLMs.
Distributed training is of paramount importance in modern machine learning and deep learning scenarios. Its significance lies in the following aspects:
- Faster training: As demonstrated in the output, distributed systems reduce the training time for large datasets. It allows parallel processing across multiple nodes, which accelerates the training process and enables efficient use of computing resources.
- Scalability: With distributed training, the model training process can easily scale to handle massive datasets, complex architectures, and larger batch sizes. This scalability is crucial for handling real-world, high-dimensional data.
- Model generalization: Distributed training enables access to diverse data samples from different nodes, leading to improved model generalization. This, in turn, enhances the model's ability to perform well on unseen data.
Overall, distributed training is an indispensable technique that empowers data scientists, researchers, and organizations to efficiently tackle complex machine learning tasks and achieve more performant results.