 Queues provide the vital link between the main program, and the computational capabilities of XPUs in our system. Queues let us orchestrate the scheduling of work and movement of data.
Queues provide the vital link between the main program, and the computational capabilities of XPUs in our system. Queues let us orchestrate the scheduling of work and movement of data.
In this installment of my #xpublog, I review SYCL queues and offer insights that highlight how to fully utilize SYCL queues (the rest of the story).
In my prior #xpublog post, I covered three things:
- What is an XPU - and why should I care?
- What is SYCL?, and how can it be used to make our neurotic kitten lighten up (you won't want to miss that)
- How can I try it out for myself using the Intel DevCloud for oneAPI (all free, easy, and very cool)
I encourage feedback to help direct what I tackle in future installments! I have included a link, at the end of this article, to where you can leave comments and see what others have to say.
What is a Queue and why care?
[embed]https://www.youtube.com/watch?v=p7HWSciMAms[/embed]
In order for our program to use a device (XPU), we create a connection to a device by creating a queue object. Upon creation the queue is associated with a specific device in our system. Once created, which device a queue connects to cannot be changed; if we want to command a different device, we need to create an additional queue. We can create as many queues as we need.
In our book, we describe queues for the first time in Chapter 2 “Where Code Executes.” My xpublogs aim to extend and complement the content in our book (download book as PDF). A few additional items can be useful references especially after you have read our book: the new SYCL 2020 Reference card (16 pages) is a handy reference; the online DPC++ reference can be useful for interface details; and the official SYCL 2020 language specification.
additional items can be useful references especially after you have read our book: the new SYCL 2020 Reference card (16 pages) is a handy reference; the online DPC++ reference can be useful for interface details; and the official SYCL 2020 language specification.
For purposes of programming, we treat a device as something to feed with data and code (kernels) to run.
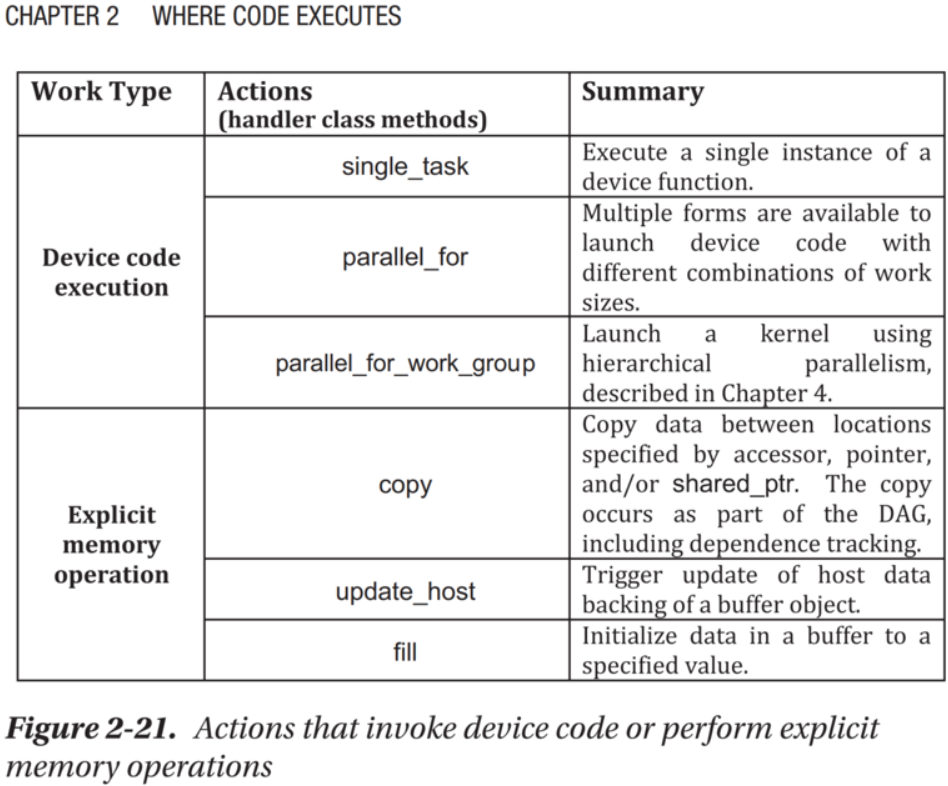
The Six Commands for Queues
There are two types of actions for a queue:
- requests to execute “kernels” of work, and
- memory commands to move around data that kernels need, or have created.
There are three varieties of each, therefore everything we need is handled by one of six actions available for queues.
Is a Queue the Only Way to Control a Device?
I would suggest we consider queues as an all powerful connection between the host and devices (XPUs).
However, I will not say that "SYCL queues are the only way to command a device" because it is technically not true.
Initially, a ‘queue’ is the host’s only connection for asking a device to run code or operate on memory. However, once we have shared memory set up, the host and devices can interact via shared memory. This technically means that a queue is not the only way to communicate with devices.
Now we know, and we can go on ignoring this technicality and think of queues as the way to control devices.
Which Device does our Queue Connect to?
As we saw in my prior xpublog, if we create a queue without specifying a device, the runtime will assign whatever device it thinks was the best available. SYCL guarantees there is always a device available, if there is no accelerator in the system then the device we default to is likely to be the CPU. Even though SYCL guarantees there will be a device, we encourage error handling be used in production code in case the runtime finds that the device drivers are not installed and accessible.
In addition to simply letting the runtime pick the device for us, SYCL allows us whatever level of control that we desire in choosing the device with which our queue will connect. At runtime, our program can check what resources are available, and make any choice we want. We can give general guidance such as "I want to run on a GPU," or we can get as specific as we like.
Default device selection when we feel nonchalant
In a prior xpublog, I presented a "Hello SYCL" that lightened up our kitten Nermal. In the original program, I simply created a queue. That is the same as using the 'default selector.' This is a nonchalant approach - it effectively says 'use whatever you've got!'
This approach will always work, because SYCL guarantees that there must always be a device available. While the specificiation can require that of our implementation, it is technically possible to break it if we don't install the drivers to make our installation complete! A truely robust program should provide a try/catch around queue creation even if a valid installation should not fail.
Device selection that is a little more prescriptive
In addition to the default selector, SYCL allows us to ask for a CPU, a GPU, or an accelerator. The accelerator category is a catch-all for devices that are not a CPU or a GPU. DPC++ also offers an Intel extension to request a real FPGA, or an emulated FPGA. Since FPGA compilations are not known for speed, we will want to debug as much as possible using an emulator before checking code out on a real FPGA.
Each of these selectors can fail if such a device is not on the system. For example, the GPU selector will fail on a system that has no GPU on it. Having error handling set up (see Chapter 5 in our book) is important in production applications.
If we request a GPU, and there are multiple GPUs in the system, it is up to the runtime to pick one for us. We have no control over which GPU is choosen for us, unless we use a custom device selector.
Device selection for control freaks (like me)
It is easy to imagine many configurations are possible, and it is easy to imagine that we might have very specific ideas on our order of preference in picking a device if more than one XPU is available at runtime. For instance, we might prefer a GPU with USM support over a GPU without USM support, or we might like to get the GPU with the largest memory, or we may prefer an FPGA over any GPU at all.
We call it "custom device selector." We simply write a routine that scores a given device, and the runtime uses the scoring to pick a device. We cover this, with an example, in our book in Chapter 12 - I talk this through in the video (start 5 minutes in). Figure 12-3, in particular, has a simple example to illustrate the concept. The mechanism is simple, and powerful enough to put us completely in control.

Can Devices talk to Each Other?
For now, let's consider devices to be totally independent with only connections to a host. In a future xpublog, I will explore the how SYCL has contexts which helps us manage which resources we can access when sharing is possible between devices such as shared memory.
Connecting our Queue to an FPGA emulator
Applying what we've learned so far - we can revisit our "Hello SYCL" program, from my prior xpublog, and change it to specifically target an FPGA emulator. To do so, we simply change the queue creation to use an FPGA selector.
I change
queue q;
to:
INTEL::fpga_emulator_selector my_selector;
queue q( my_selector ); // note the code graphic video code is mixed up (wrong)
Since this uses an Intel extension for FPGAs, I have to add an include:
#include <CL/sycl/INTEL/fpga_extensions.hpp>
SYCL encourages vendor specific device types. Based on the current SYCL 2020 specification, using an FPGA needs to either be via an SYCL 'accelerator' (pretty generic) or use a vendor extension for FPGAs. Intel choose to create a vendor extension, and offer some FPGA specific capabilities in their support.
Try running it online (DevCloud)
I hope you'll try it out online - it takes only about two minutes to experience it in person! The Jupyter notebook can be reached by selecting the "xpublog 4" in the Welcome notebook. Get to the Welcome notebook by following the "When returning" instructions in the DevCloud notes in my prior xpublog.
You may note that I'm building my program statically for just one device. That gives me the ability to compile quickly when I'm not targeting the FPGA. As soon as I include an FPGA target, an FPGA compilation needs to happen. The code takes a little more than an hour to compile for an FPGA device, which is typical for an FPGA device compile. An FPGA emulator option lets us compile quickly while debugging - and is what I've setup to use in this tutorial to make it fast to try out.
This shows how easy it is to modify our program to direct work to various XPUs.
A note about compiling in advance
In the video (time = 9:39) I mention that unlike other devices, the FPGA code must be compiled in advance. This is understandable because FPGA compiles are too slow (2+ hours) to do 'just in time' each time we run the program.
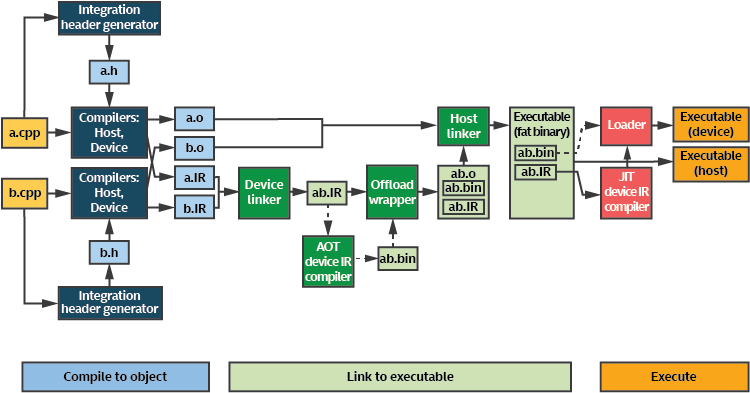
It is possible other XPU devices may have heavy-weight compilation processes too, however most commonly code for other XPUs can be finalized for the device at run time. We refer to this as ‘just-in-time compile’ from an intermediate form into the precise code needed by the available device. We dive into this more in our book, specifically Chapter 13 where Figure 13-2 (shown below) illustrates the key concepts at a high level.

Now, for the rest of the story...
Let's consider some interesting answers to questions that help shed more light on how queues work and are used in applications.
Q: Can I force which device a program uses?
While our program is in control of what device it selects, a nice trick is that we can limit the devices from which our program can select.
There is no standard SYCL way to do this, but the DPC++ implementation does provide an answer. Other SYCL compilers may have similar mechanisms.
For DPC++, the SYCL_DEVICE_FILTER environment variable can be set to limit the SYCL runtime to the use of only a subset of possible devices. This can affect device query functions (platform::get_devices() and platform::get_platforms()) and device selectors.
On many systems, a single device might be supported by multiple drivers. For instance, an Intel GPU may have a Level Zero and an OpenCL driver installed and available. Other systems might be able to have multiple versions of drivers installed simulataneously. The SYCL_DEVICE_FILTER can affect which devices the program sees, and which drivers our program can interact with as well. This gives us control over what the program thinks is the full platform!
While we are limiting what devices our program will see when it runs, the program still has to select a device, and run on it. All we are doing with this filter is limiting its choices. On a system with multiple XPUs, we could limit which XPU our program could run on. In this way we could compile one program, and then run specific instances on specific XPUs.
The DPC++ LLVM project github has complete documentation on this feature.
Q: Can I get a runtime trace of the device discovery and selection process?
The same documentation offers some very cool tracing options, that can help understand behavior on specific systems during the device discovery and selection processes. That can be very helpful when we find ourselves puzzling about why something isn't working as we expected, or just to get simple peace of mind that our program is running where we expected.
Q: What type of queue are SYCL queues?
The default queue style is not a FIFO. Instead, once we put an item in the queue, it may run in any order relative to other items in the queue as long as dependencies are maintained. Buffer usage create depenedencies implicitly, and we need to manage other dependencies (e.g., shared memory) explicitly. We dive into how in the Chapter 8 of our book.
SYCL does support in-order queues if we augment the default queue with a property of 'in order.'
Q: Can using multiple queues be better than one?
Sometimes multiple queues can be more convenient than one, and that can lead to code that is easier to understand and maintain.
Four reasons that I know of, for considering using multiple queues to the same device:
- When we have multiple threads, or multiple ranks, in a program, because that can great simply programming by avoiding coordination of using a single queue - so this is encouraged!
- Multiple queues can be better than one if they allow us to express more parallelism. While I encourage everyone to just use a default queue type, if you do use in-order queues you will want to consider using multiple in-order queues if you have opportunities for concurrency.
- If we need to synchornize, we can do a wait on a queue. Such a wait requires that everything submitted to a queue compeltes before we proceed. If we want more control over which operations we really want to wait upon, then we can use multiple queues to allow us to wait on only the operations issued to a particular queue. This is a clever way to wait on a subset of operations that we would have otherwise submitted to a single queue.
- If we want to issue different commands to different parts of a device we will use multiple queues. SYCL supports the concept of a subdevice, and each subdevice can have one or more queues attached. When we subdivide a device, we can use mutliple queues to determine which parts of the overall device gets the work to execute. We do not discuss subdevices in our book, so I will discuss them in a future xpublog and in the next revision of our book.
We get to decide if having multiple queues to the same device is more convenient in our application or not. It is up to us to choose what work best for us.
Q: Can using multiple queues be worse than using one?
Hopefully using multiple queues will never be worse that using one, assuming they share a context. I'll discuss contexts in a future xpublog. If you are not using contexts in your code explicitly, my belief is that implementations should default to sharng a context between queues if it can.
If multiple queues are slower, I would investigate two things:
- Contexts are not cheap to create - so I would check that I had not gone crazy creating an excessive number of contexts per thread.
- Multiple paths theoretically would be affected by command buffering differently (‘batching’) that is a more complex interaction of the software stack, and might send you digging into platform optimization guides. I would not rush to do that unless I was pretty sure I've done what I could at other levels of application tuning.; I am guessing that I may revisit this in a future xpublog for fun too.
Q: Can a queue be forced to use only part of a device?
The answer is YES - SYCL calls this a subdevice.
A device can be subdivided with queue(s) for each division. In fact, we can also still have queue(s) to the whole device.
Subdevices act exactly as devices, and can be divided up themselves.
In a future xpublog, when I discuss contexts, and abstract models for the machine and our application, the uses for this will become more evident.
This is a powerful mechanism, and can be very useful.
We do not discuss subdevices in our book, so I will discuss them in a future xpublog and in the next revision of our book.
Q: Can multiple applications share a device?
If we run multiple SYCL applications on a single host, then each application is entitled to have one or more connections to an XPU (device). If we have multiple applications running, we will end up sharing a device.
SYCL does not define a specific portable API to query that a device is busy. Even if it did, we’d really want to see into the future to know how much longer it will be busy.
As I mentioned earlier, implementations may offer ways to affect the environment that a SYCL program runs in by using a filter to affect which drivers (hence which devices) the application will “see.” This can be used to control which applications use which devices, if that level of control appeals to us.
Q: Can a queue direct work to multiple devices?
No, a single SYCL queue can only dispatch to a single device (or sub-device).
We could try to write an abstraction to behave like a queue and spread work across multiple devices, while under the covers we would be forced to manage unique SYCL queues for each device. Such an approach will face multiple challenges including managing data placement, movement, and access. However, with detailed knowledge of your own application's needs this might make sense to consider.
Q: Why did SYCL 2020 get rid of Host Device?
The final SYCL 2020 appeared after our book, and resulted in a book errata.
The host device concept was dropped in the final SYCL 2020 specification after our book, went to press. It’s the only significant change we did not predict in the content we included in our book.
I've written about this in the book errata that we maintain alongside the code examples in the github project for our book.
SYCL requires there be always be a device - so our kernels can always run somewhere. However, with SYCL 2020 there is not longer a magical 'host device' with specific properties. The concept of such a 'magical device' did not fit well with all embedded platforms since targets machines cannot always be expected to have the ability to support such a device. This is a great example of how SYCL is very serious about being cross-platform.
Dropping it was an improvement, and it will not be missed. In general, if you thought you wanted a ‘host device’ – you probably want to find and use a ‘CPU device.’
Now you know…the rest of the story.
Watch for future xpublog topics
That was a look at SYCL queues, and some answers for questions about queue usage.
In my next xpublog, we will consider how to simplify our thinking about hardware and software, and discuss contexts. This offers to help with our sanity, and lead to more portable and maintainable applications.
It's a must-not-miss explanation of how to think clearly and program well in SYCL.
There is a huge amount of wonderful training available on DevCloud, for more information, visit the oneAPI DevCloud training page. I recommend starting by clicking “View training Modules” for the Intel oneAPI Base Toolkit.
Post comments – please!
Please post comments with your #xpublog thoughts, feedback, and suggestions on community.intel.com James-Reinders-Blog.
What should we dig into and explore? I love to dig to offer perspectives and details that come from experience, and sharing between developers. With some encouragement, I’ll dig into any topic that you find interesting and that I can help illuminate.
I look forward to your thoughts, feedback, and a good discussion.